[ML筆記] Coursera 機器學習基石(上) Week4
Coursera 機器學習基石(上) Week4 筆記
本週探討 Machine Learning 的限制
首先來玩個小遊戲,根據上面六張圖片,找出一個規則,然後回得下面的圖片是 +1 還是 -1


如果根據對稱與否判斷,是的話就為 +1,就會判斷他是 +1
如果根據左上角是否是黑色的,是的話就為 -1 ,就會判斷他是 -1
無論我們回答哪一種答案,都有可能會被說是答錯了! 取決於評分者心裡想的規則是哪一套
由上例可知,如果我們遇到一個 “壞心的” 老師,來打分數,他 always 可以說我們答錯了!
這樣的問題 ML 無法處理

假設給我們前五個 data input output 結果,要我們預測後三個

假設我們定義的 g 在前五筆資料測試下,確保是正確的
但是他在後三筆測試資料下,無論輸出哪一種,都會有全錯的可能,因為
在前五筆資料 OXXOX 的情況下,後三筆資料的組合情況尚有八種可能,因此我們回答任何一種,都有可能會被說成錯誤,這類問題必須還要再加上一些限制條件。

針對未知來做推論:
例如想要知道罐子裡面,橘色彈珠的比例
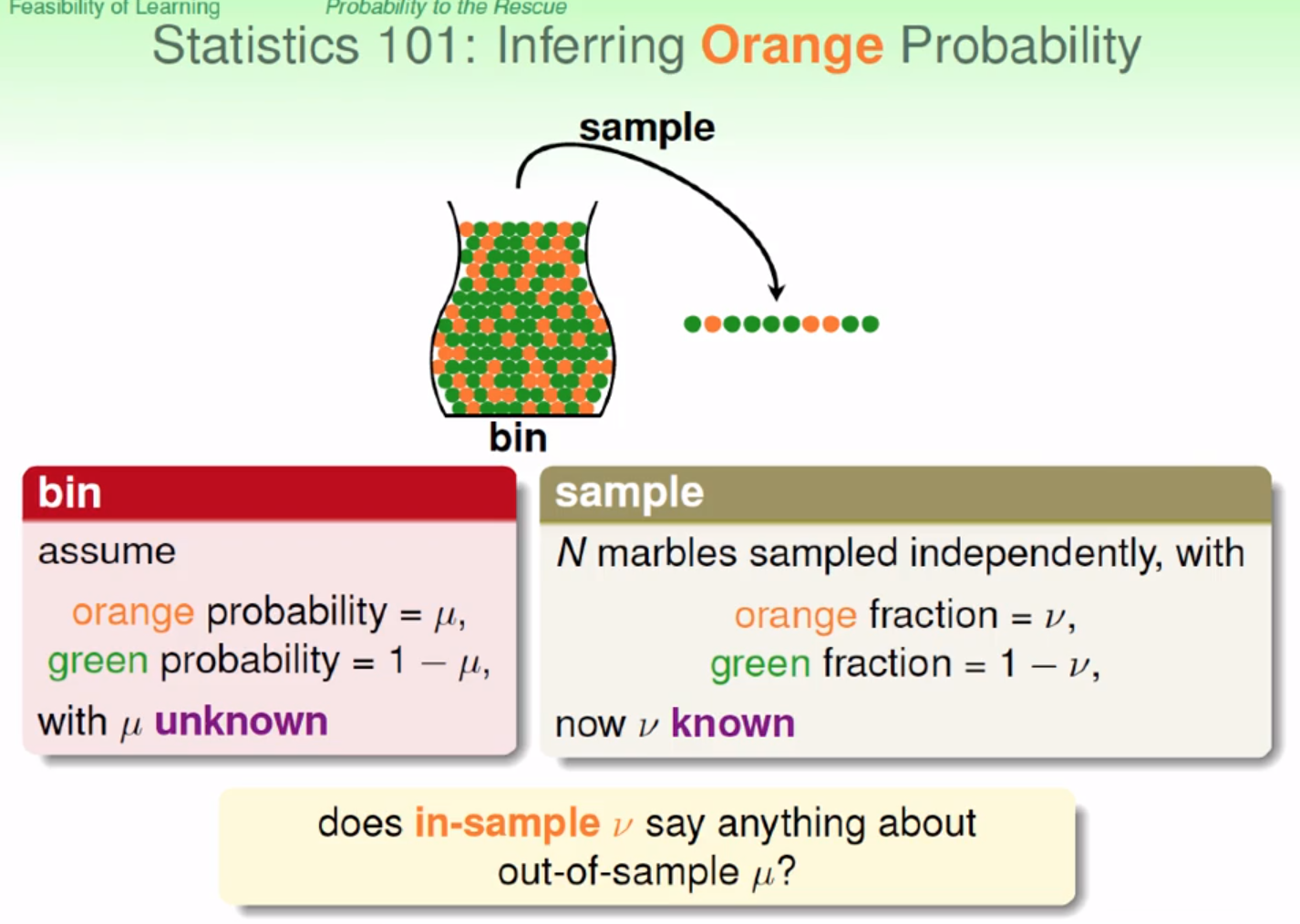
做法:抽一把起來計算橘色的比率,也得知了綠色的比率

根據我的的抽樣結果,我們只能得到一個觀察:
罐子裡面橘色與綠色的比率 “可能” 跟我們抽樣出來算出的比率接近!
以數學式表示:

Hoeffding’s inequality

根據不等式,當我們抽取的樣本數越多 N 越大,我們抽樣的比例就越有可能接近實際的 data 的比例
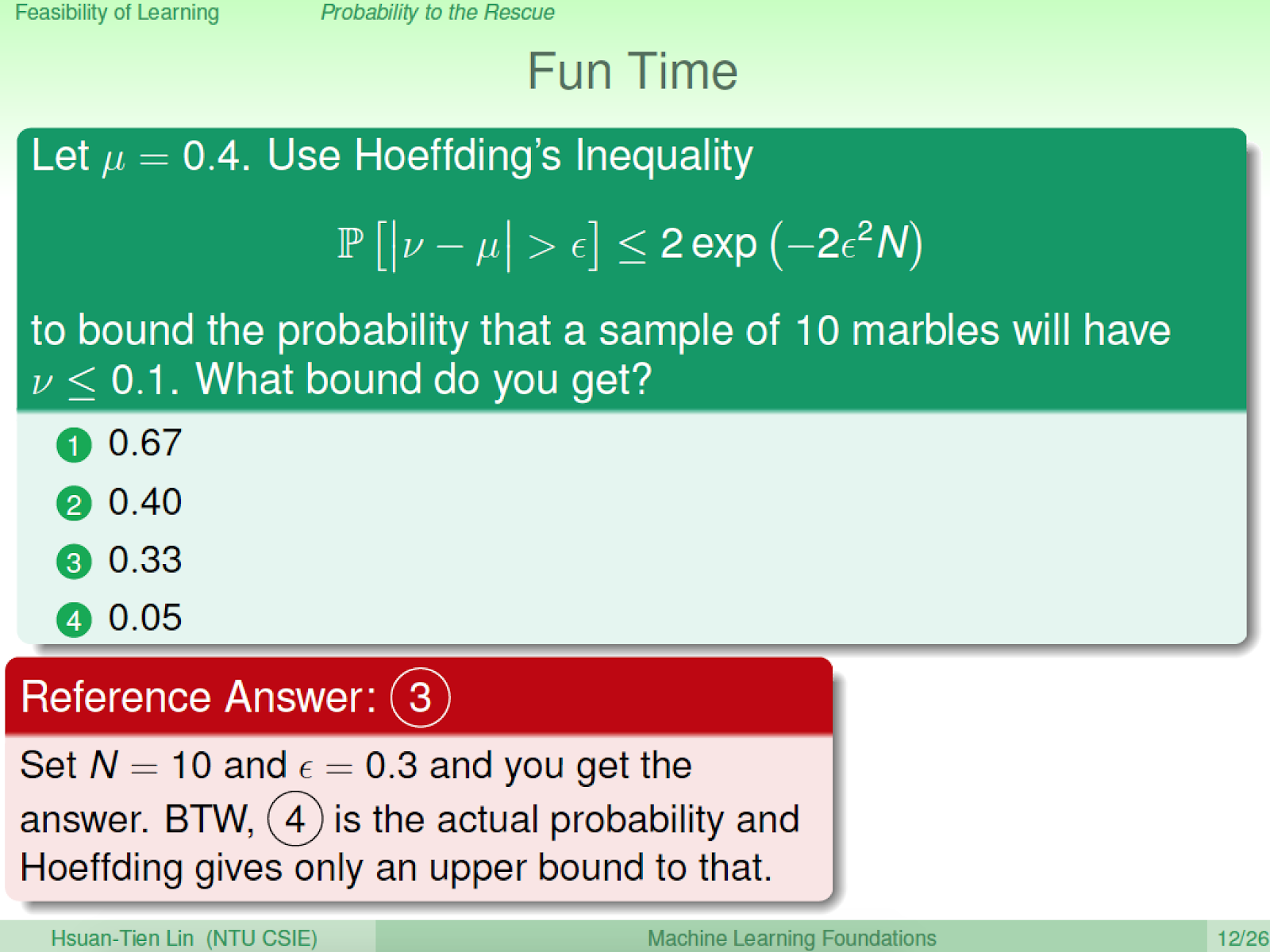
P[|0.1 - 0.4| > ϵ] 因為0.1求 bound,所以取 ϵ = 0.3
根據 Hoeffding’s Inequality 知道上述機率

選 (3) 0.33
選項 4 的計算法:
h() 為 hypothesis function 我們所假設的判斷準則
已知袋子裡面兩個顏色的求分佈為比值為 0.4,即兩種顏色比例為 4:6
當我們抽 10 顆,使得 v <= 0.1,分兩種情況討論:

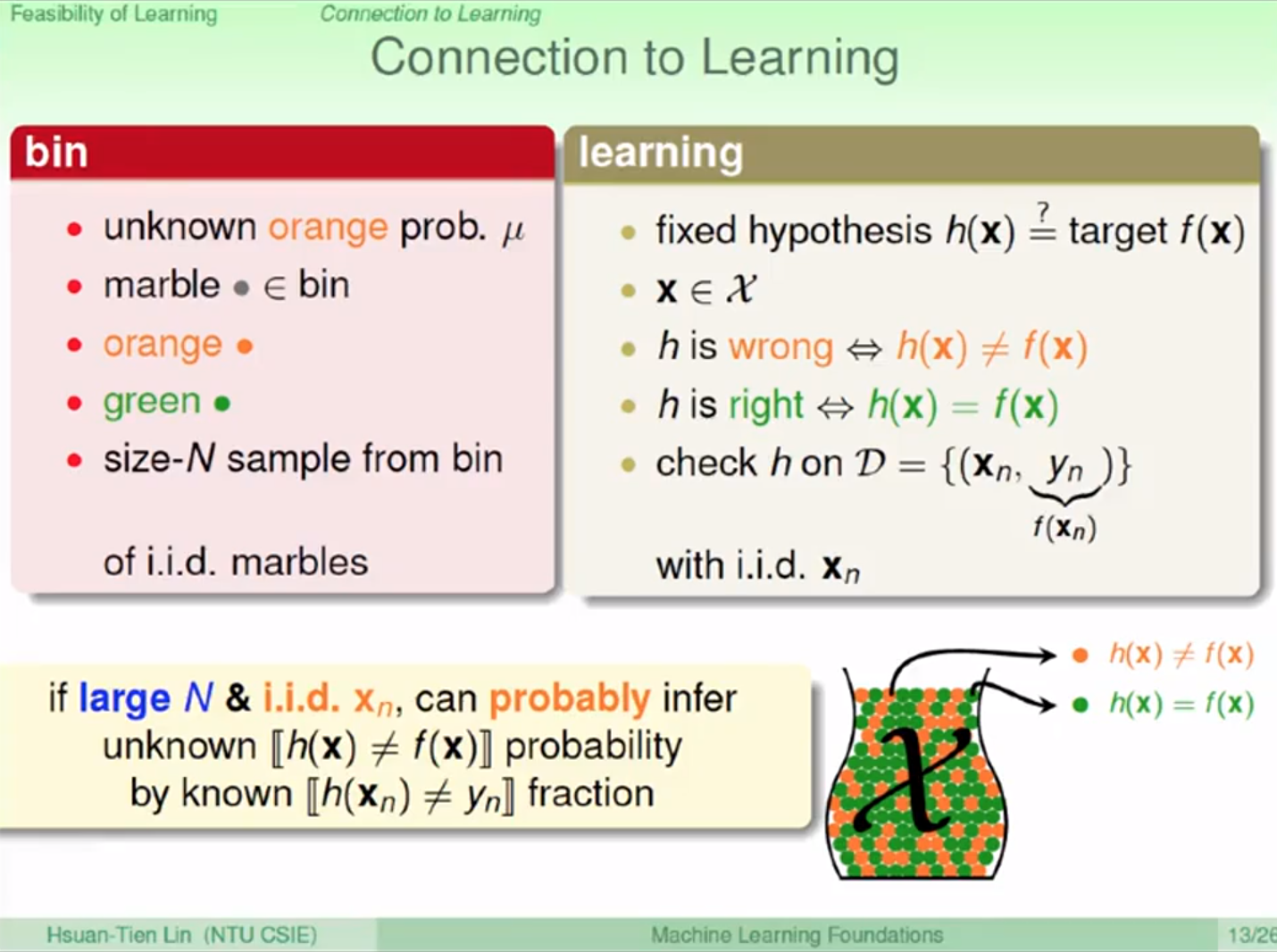
假設我們有個 h() 當我們拿到一筆 data x 時,拿去跑 h(x) 如果結果跟 f(x) 一樣的話
就代表正確判斷,如果跟 f(x) 不一樣的話,就代表我們的 h() 誤判
計算 h 在資料集 D 上面的表現如何,可以計算他的錯誤機率 h(x) 跟 f(x) 不一樣的機率
取樣 D 筆資料

Eout 對應到 h 整個真實世界 dataset 的 error 這是我們無法量測的
Ein 代表 in-sample 的 error 也就是 h 在我們抽取出來的資料集當中的 error
我們目標就是從 Ein 推論到 Eout

倘若 N 夠大資料量夠大,我們可以確保 h 所得到 Error 會跟真實世界中的 Error 很接近
機器學習:有很多不同的 h() 可以選擇

如果我們剛好選到一個很好的 h 他會得到一個很小的 error ,並且將我們的假設 h 作為 g 來使用,得到我們的 g = f Probably Approximately Correct (PAC) 的結論
如果我們挑到的 h 算出來有很大的 error 代表我們在實際的 dataset 上極有可能也會有很大的 error ,則我們至少知道當 h as g 時,g 不等於 f PAC 的結論
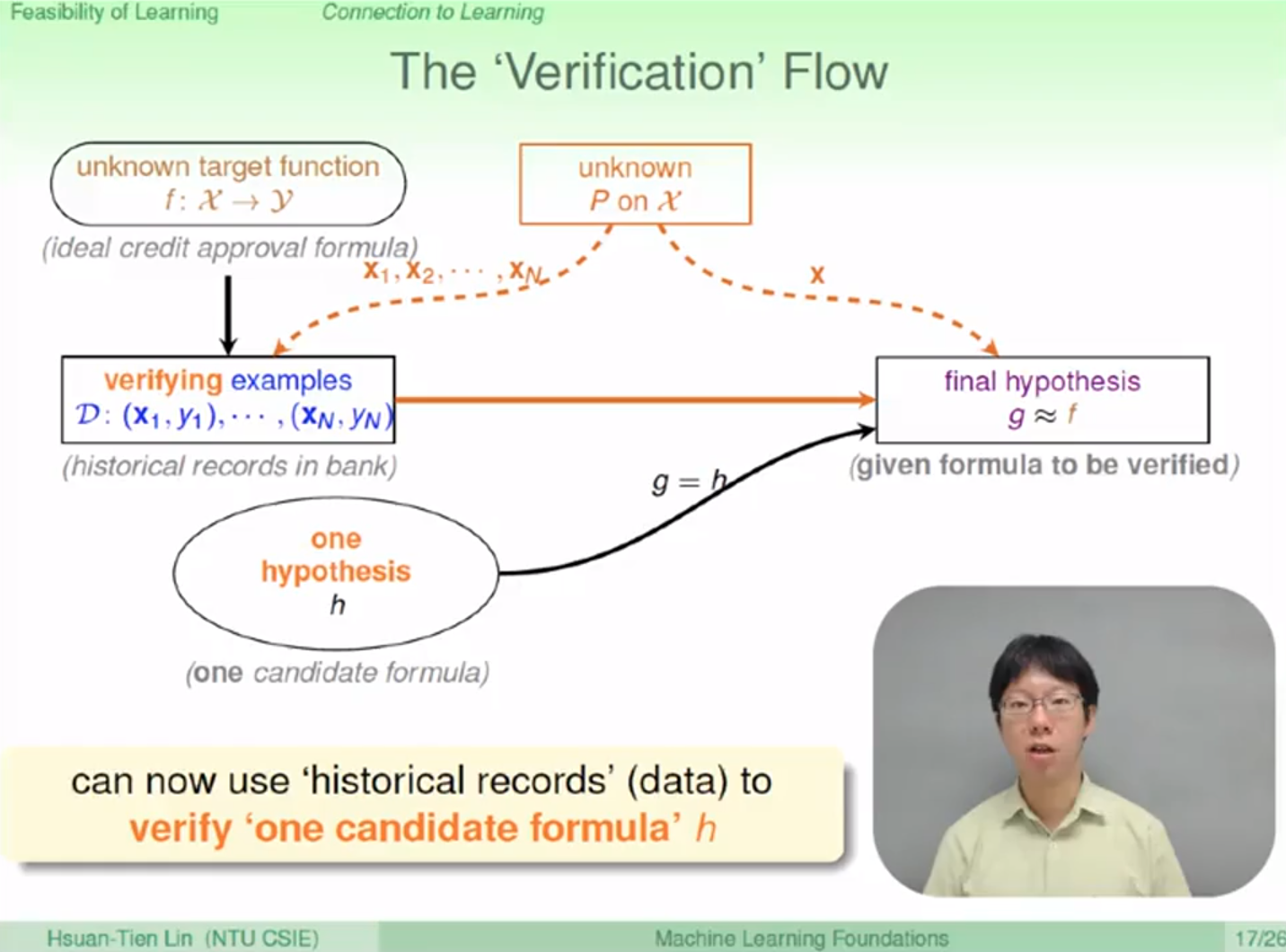
實際上在 learning 時我們會將一個 hypothesis 在 verify 資料集上使用 f 來驗證我們的假說 h
小練習

目前為止探討都是單一 hypothesis 的情形,接著來看有多個 h(() 的情況

當我們有多個 hypothesis 時,出現其中一個 hypothesis 不小心全對!
我們應該要採用該 hypothesis 做為我們的 g function 嗎?
舉一個生活中的案例
教室中有 150 位台大學生,每一位躑硬幣 5 次
當有一位學生出現全部正面的情形時,我們應該要根據他的結果來判斷,這顆硬幣的正面機率真的把較高嗎? 真的跟我們熟知的 ½ 不同嗎?
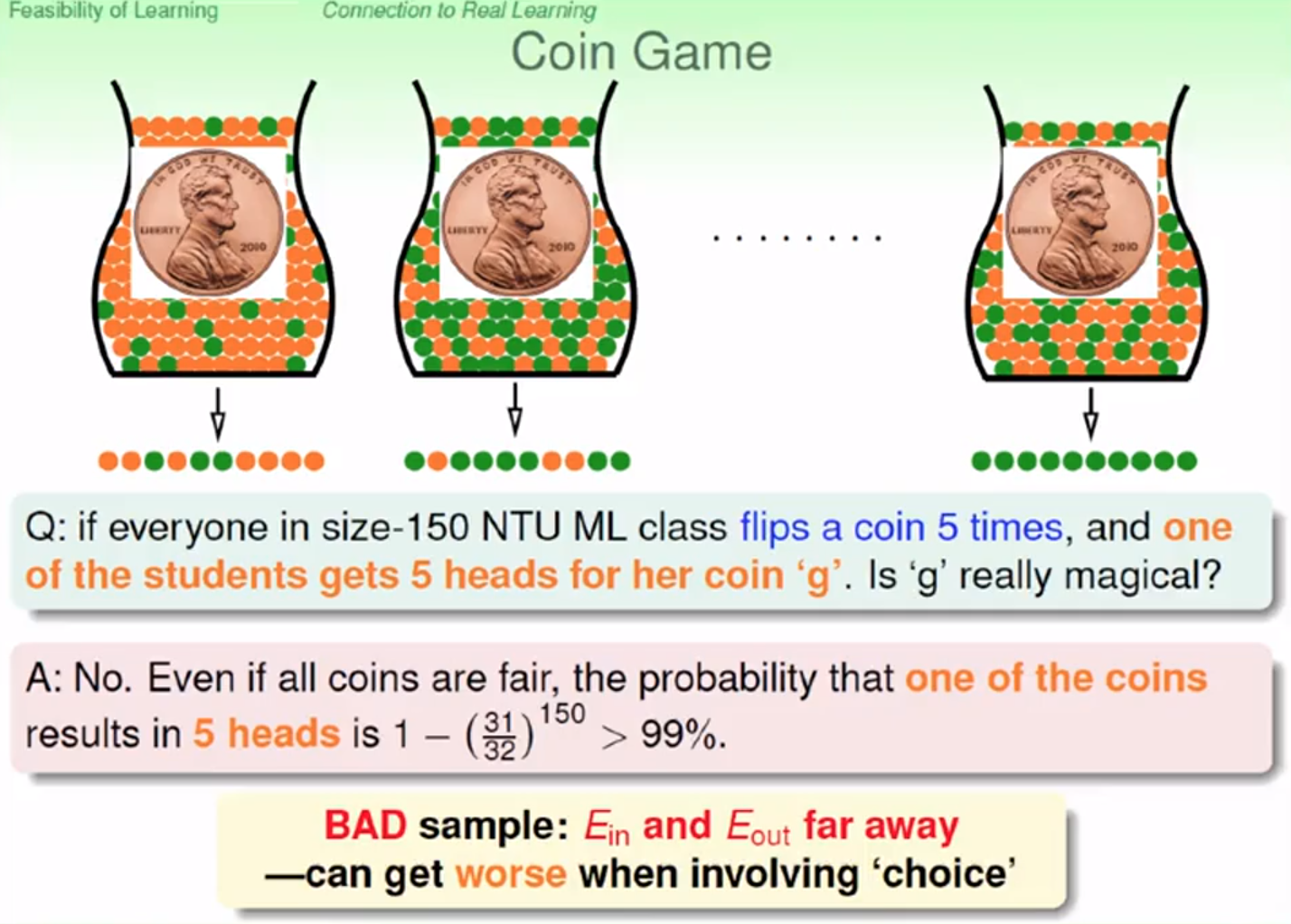
連續投擲硬幣五次,每一次都有正反兩種可能,所以共有 25 = 32 種情況,其中只 1 種情況出現五次連續正面,而不出現連續正面的機率為 31/32
我們計算150個人做躑硬幣實驗時,出現連續 5 個正面的機率為
1 - (31/32)150 > 99% 也就是超過 99% 的機率會發生這樣的狀況!
Hoeffding 告訴我們說,當我們取樣出來量夠大時,算出來的分佈會很接近我們罐子裡面的實際分佈,不好的情形會被壓到很小,但是根據以上實驗,當我們有多種(150種)選擇的時候,不好的選擇也可能會惡化我們的結果

所以我們來探討什麼叫做不好的資料
如果 Eout 跟 Ein 差很遠,就可發現這筆為不好的資料
資料集可能有 D1 , D2 , D3 , D4 , …
我們可以統計哪些資料集是不好的資料
當我們把所有資料集窮舉出來,並統計不好的資料的比例,當我們資料集加總起來夠多時,就會發現不好的比重其實是不多的,這樣也符合 Hoeffding 所提出的不等式。
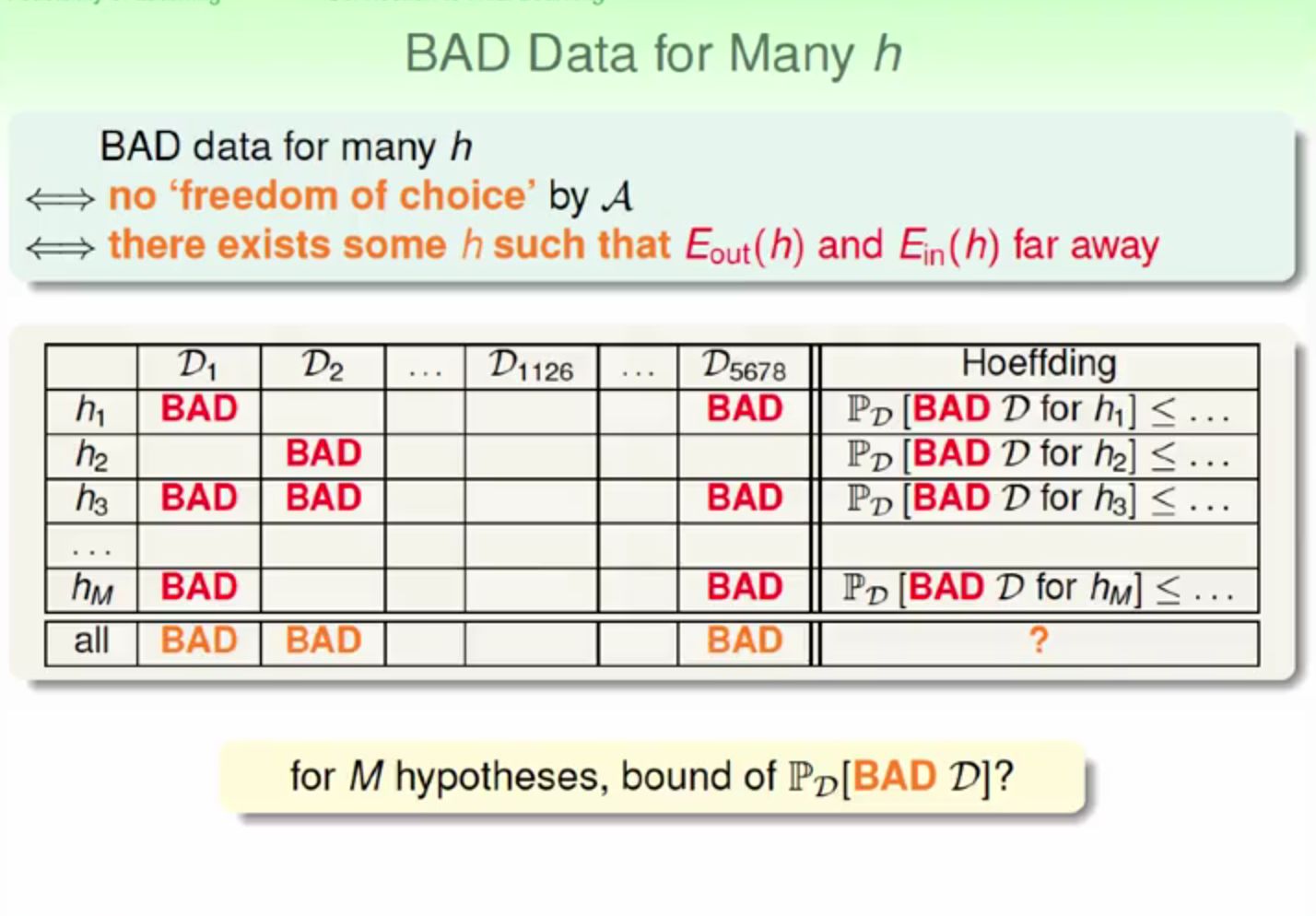
我們在所有資料集上,提出各式各樣的假說 h1 , h2 , … , hM 並且統計出這些假說在哪些資料集上表現不好,針對每一種假說 h 在所有資料集統計後的表現結果皆符合 Hoeffding 不等式
最後我們要統計一個 all 的欄位,任一資料集在某個 h 上表現不好就當作 BAD
如此可以算出所有資料集在於任一方法 BAD 聯集出現的機率

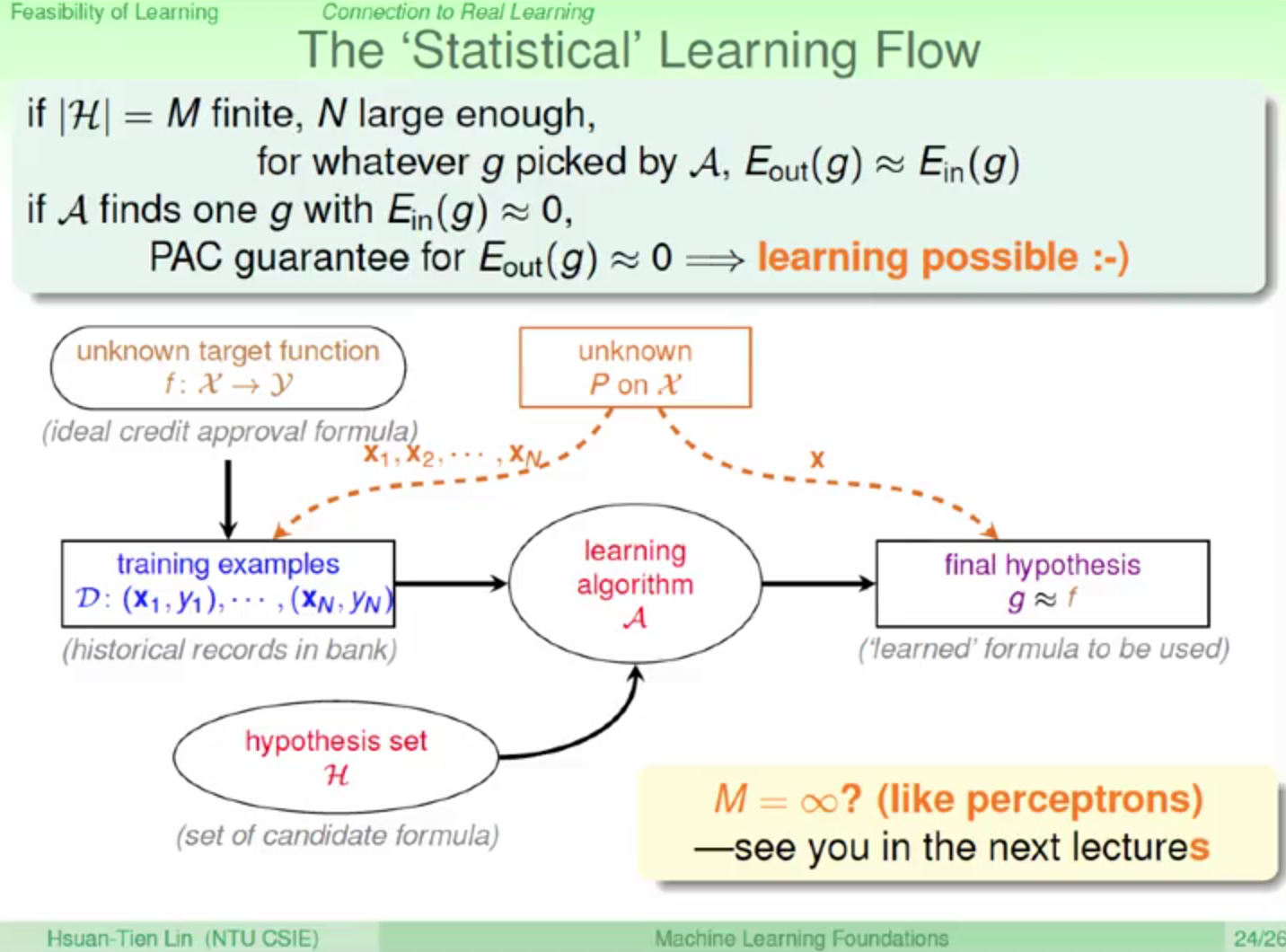
根據公式推導,我們可以得到一個結論:
當我們的資料量夠多時,我們不用管是哪一個 h 都是 “安全的”
表示不管演算法怎麼選,我們一定可以選到一個好的 g ,使得這個 g 的 Ein 與 Eout 最小
最合理的演算法 A 即為使得 Ein 最小的那一組 h 即可以作為我們要求的 g
因此不管我們演算法怎麼選,只要我們的資料量夠多!
就可以找到一個最好的 g 使得 Ein 與 Eout 最小

選項一:不同的資料集 x1 , x2 表現出來的 BAD 結果應當不同才對!
選項二是對的:因為我們如果有不好的資料 x1 那資料集全部取負號 -x1 可以想像成不好資料的另外一面,他只是把 Ein 跟 Eout 反過來而已,所以它也會是不好的資料!
因為選項二是對的,所以拿他去推導可以看做 h1 = h3,h2 = h4,可以發現選項四是對的!
選項三:根據公式推導,即可以得到的結論

這一節課一開始先跟大家講機器學習做不到哪些事情
但我們加上一些統計上的假設,可以得到機器學習做得到的事情
目前為止我們探討的 Hypothesis 是有限的,所以可以得到 Ein 有好的解的結論
之後要再推廣到探討無限的 Hypothesis 時會發生什麼事!






{kind=link}
留言
張貼留言