[ML筆記] Structured Learning - Linear Model
ML Lecture 22: Structured Learning - Linear Model
本篇為台大電機系李宏毅老師 Machine Learning (2016) 課程筆記
上課影片:
https://www.youtube.com/watch?v=HfPw40JPays
課程網 (投影片出處):
http://speech.ee.ntu.edu.tw/~tlkagk/courses_ML16.html
延續上一篇,接下藍要來探討,想辦法解這三個 Problem
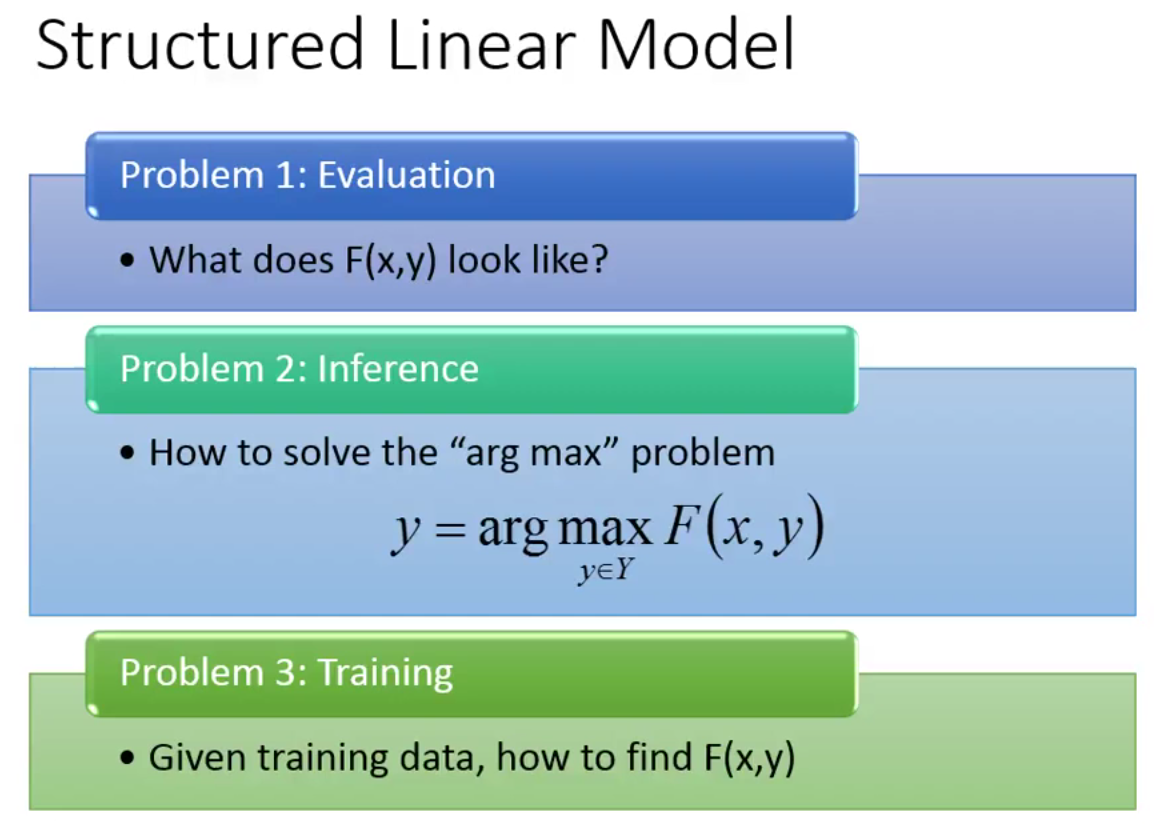
第一個 Problem:定義 F(x,y) 函式的長相
第二個 Problem:如何去窮舉所有的 y 去找到最佳匹配的 x,y 組合
第三個 Problem:在 train 階段如何順利地找到最好的 F
這個 Specific Form 必須是 Linear

我用某一種特徵計算函式 “phi” 𝜙() 來描述 x, y 的 pair
代表 x, y 具有特徵 1 的強度為 𝜙1(x, y)
代表 x, y 具有特徵 2 的強度為 𝜙2(x, y)
依此類推
然後 F(x, y) 被定義成 w1𝜙1(x, y) + w2𝜙2(x, y) + w3𝜙3(x, y) + …
F(x, y) = w 跟 𝜙 的 inner product
舉例說明 F(x, y) 會長什麼樣子
例如在 image object detection 問題中
我們可以自訂一個 feature vector ,內容隨便定
如圖例:我們定
紅色 pixel 在框框裡面出現的比例當作一個維度
綠色 pixel 在框框裡面出現的比例當作一個維度
藍色 pixel 在框框裡面出現的比例當作一個維度
紅色 pixel 在框框外面出現的比例當作一個維度
…
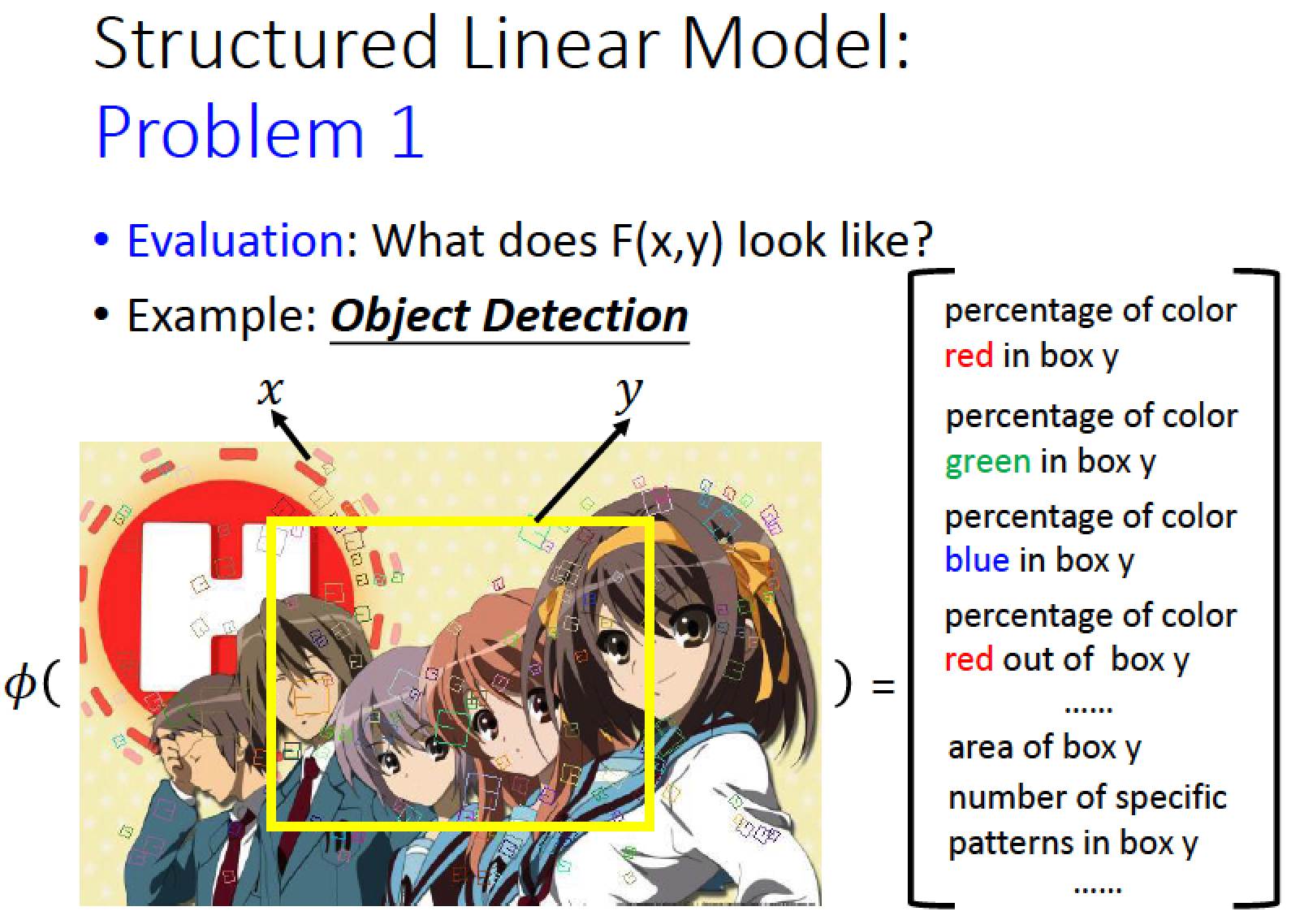
問題:這些 feature 要由人來找嗎?還是讓 machine 透過 data 自動抽取呢?
答:目前採用 CNN 自動抽取 feature 後搭配 structured learning 的架構來做效果最好
另一個例子:做 summarization 時
x 是一個 document
y 是 summary
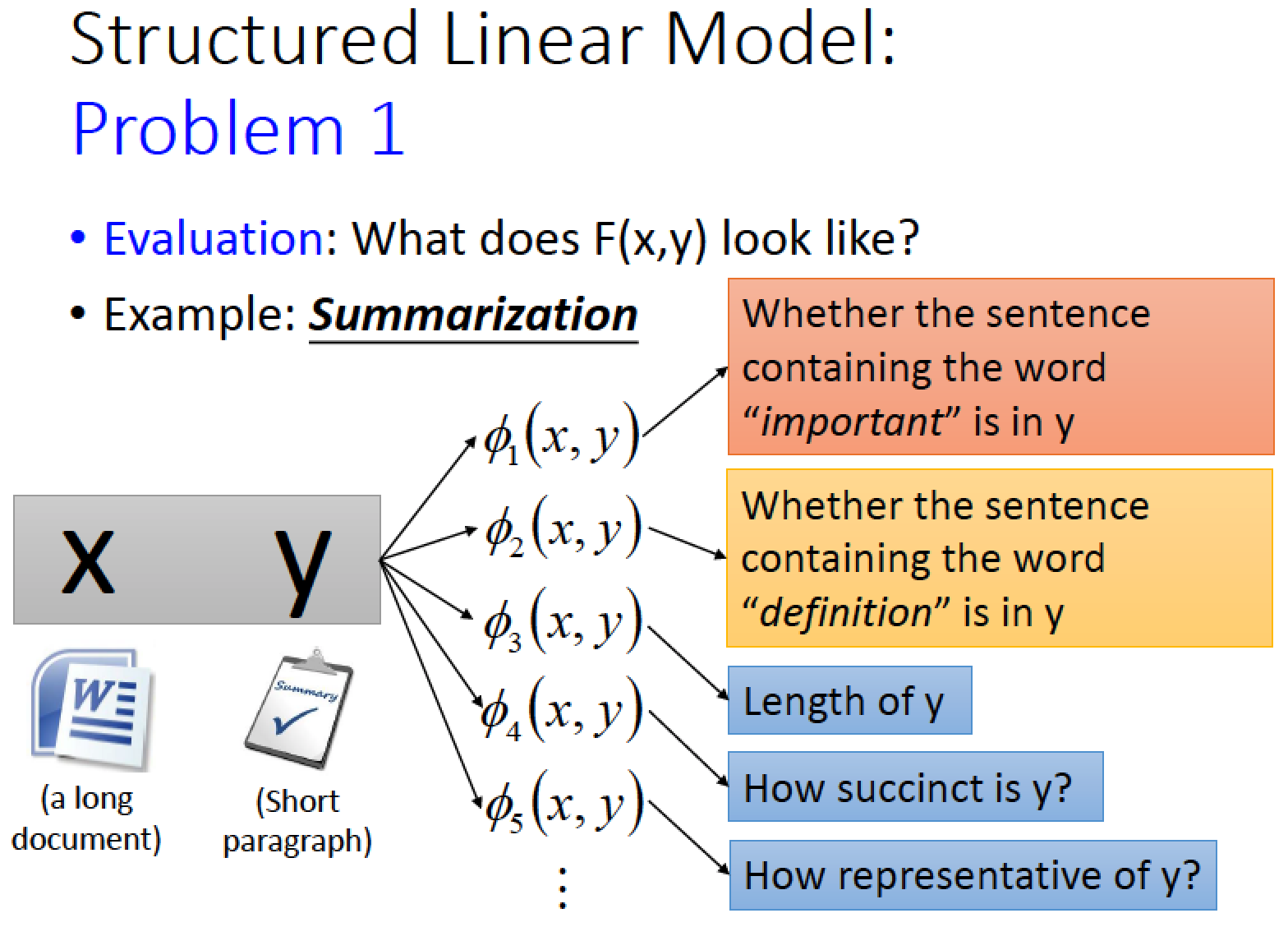
我們的 phi function 可以是 “y 裡面有沒有包含 important 這個字”
也可以是 “y 裡面有沒有包含 definition 這個字”
或者是 “y 的長度是多少”
“y 的精簡程度為多少”
例子:做 retrieval 時
x 是使用者 input 的 keyword
y 是系統回傳搜尋的結果

我們的 phi function 可以是 “ y 的第一筆搜尋結果跟 x 相關程度” 等等
第一個問題定義好之後,第二個問題怎麼辦呢?
窮舉所有的 y 看哪個 y 可以讓 F 函式的值最大

這裡我們先假設這個問題已經被解決了,先來看第三個問題

第三個問題:希望找到一個 Function 可以滿足以下條件:
對於所有的 training data r :
希望讓正確的 Y 代進去 Function 裡面時
它的值要大過於任何所有其他的 y 代進去的結果
以下舉一個具體的例子來說明這件事:
Object detection 例子:
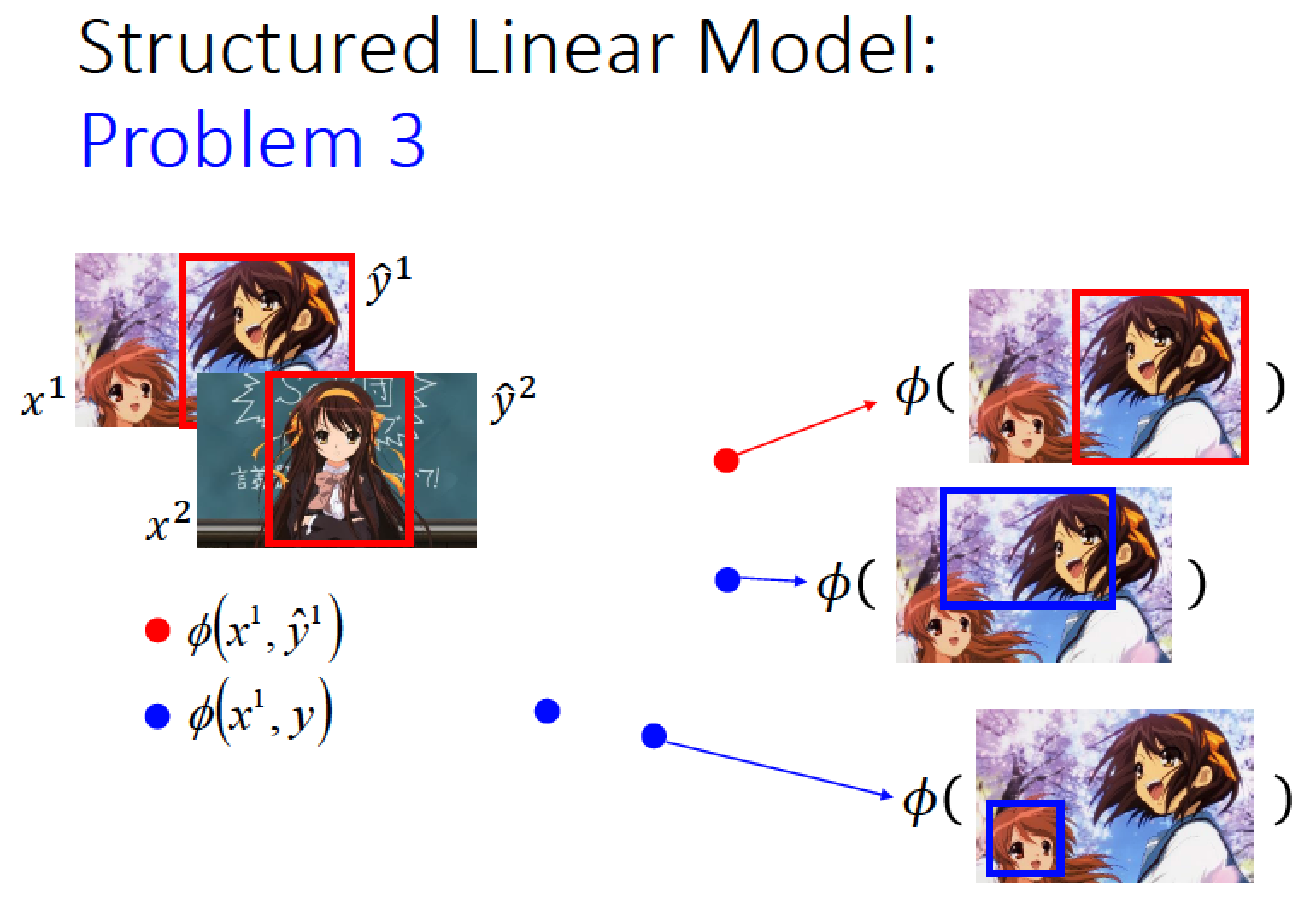
我們蒐集了一筆 data x1,他要對應的框框 y1-hat 如左圖紅框
我們蒐集了另一筆 data x2 ,他要對應的框框 y2-hat 如左圖紅框
我們假設目前 feature 只有兩的維度,我們把它畫在平面上
x1 跟 y1-hat 所形成的 feature 是紅色的點 (正確的紅色框 只有一個)
x1 跟其他的 y 所形成的 feature 是藍色的點 (不正確的紅色框 有很多個)
→ 紅色點只有一個,而藍色的點有很多很多個
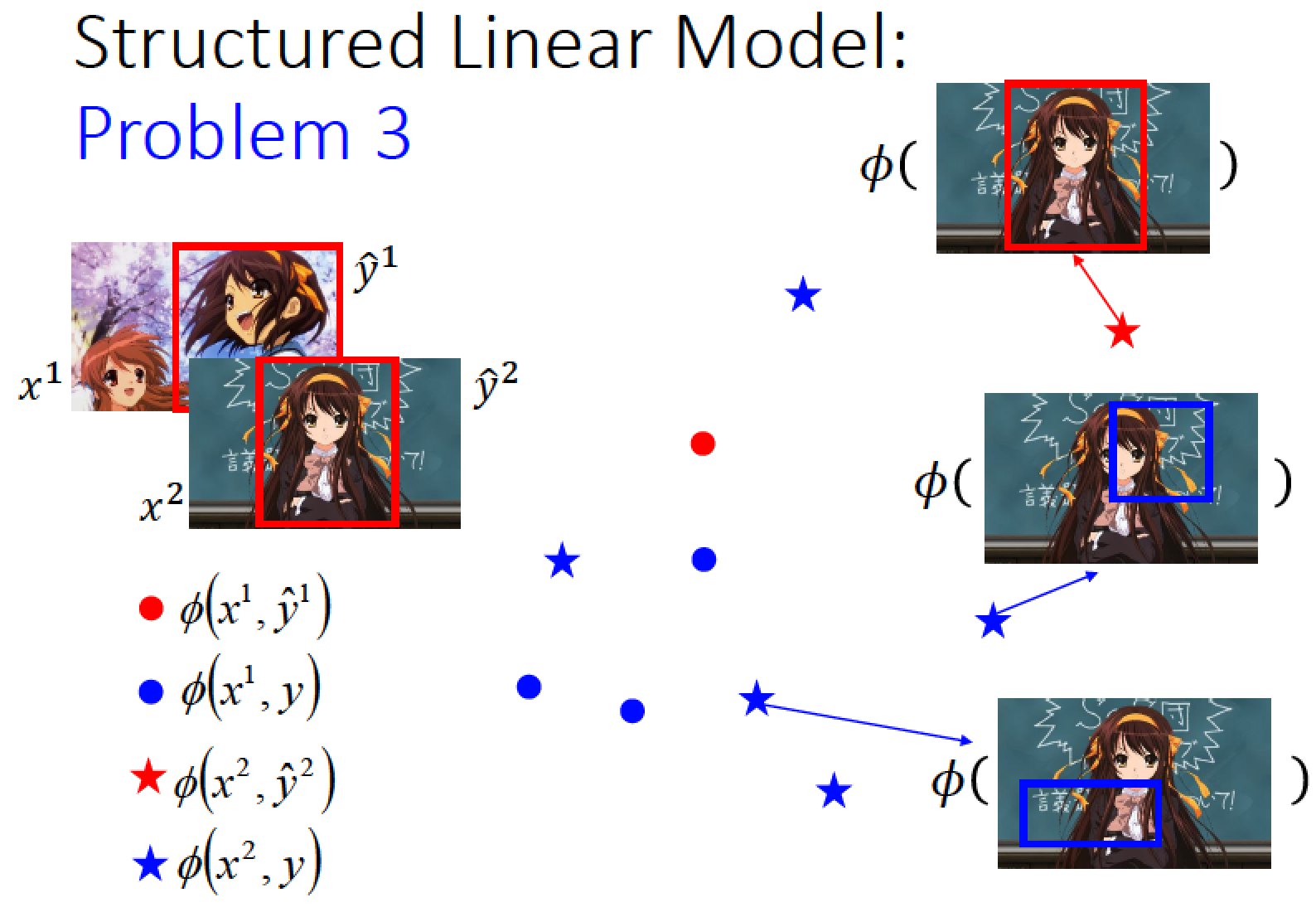
x2 跟 y2-hat 所形成的 feature 是紅色的星 (正確的藍色框)
x2 跟其他的 y 所形成的 feature 是藍色的星 (不正確的藍色框)
→ 說紅色的星只有一個,而藍色的星有很多很多個
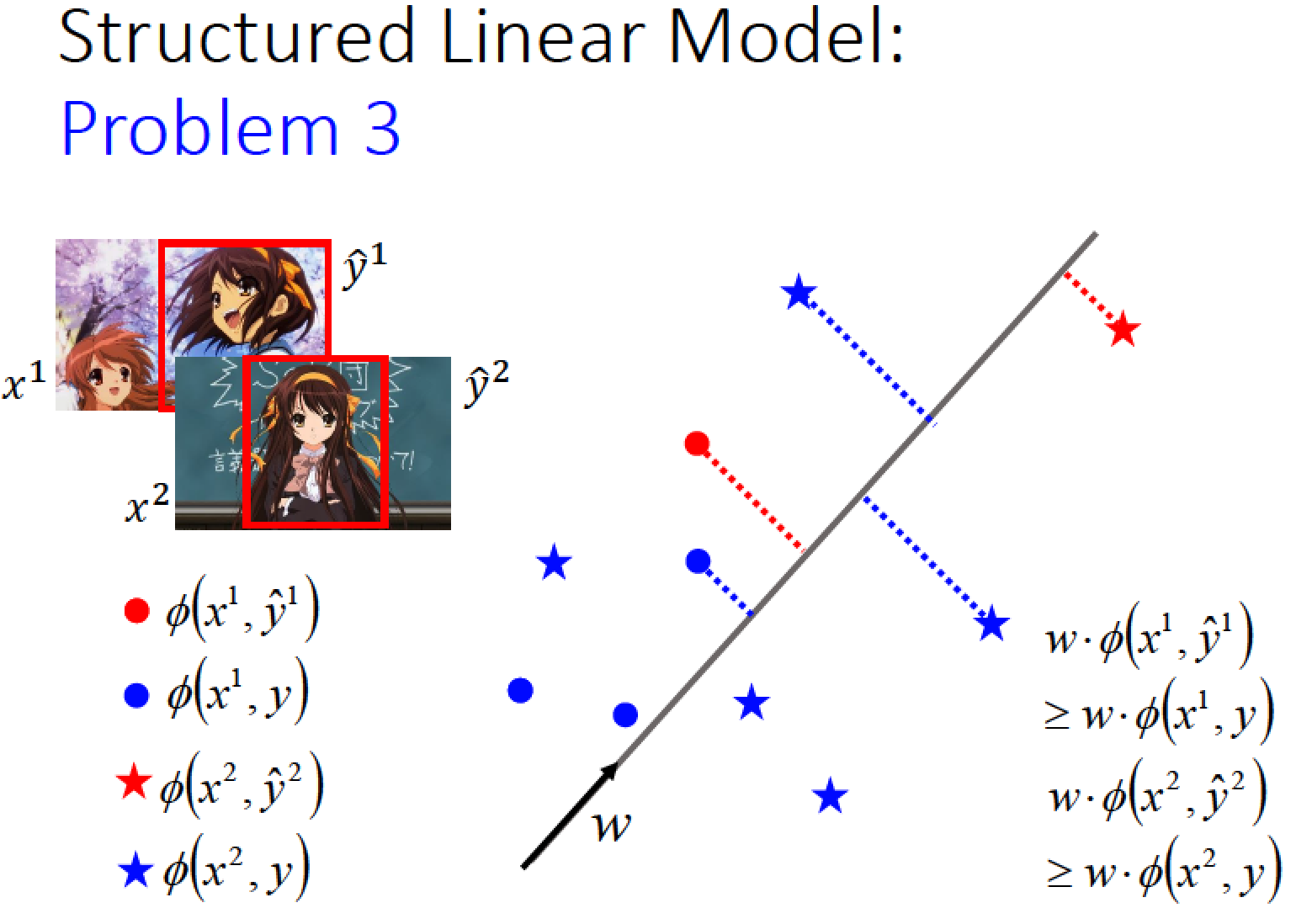
再來我們要達到任務是,我們希望找到一個 w
這個 w 可以做到事情:
我們把成千上萬藍色的星星,藍色的點,以及紅色的點,紅色的星星
都去跟 w 做 inner product 以後,得到的結果為
- 紅色的點所得到的值,大過於藍色的點所得到的值
- 紅色星星所得到的值,大過於所有藍色星星所得到的值
點只跟點比較,星星只跟星星比較,兩者不同形狀不互相比較

接下來要講的就是,這個問題沒有想像中的困難
我們提供一個演算法可以解:
演算法的 input 就是所有個 training data x,y
output 就是 vector w,且這個 w 要滿足我們前面所講的特性!
針對所有個 data ,以迴圈走訪
迴圈裡面,每次取一筆資料 xr, yr-hat
然後我們去找一個 yr-delta 可以讓 F 值最大
如果找到的 yr-delta 不是正確答案 y-hat 的話,我們要把 w 改一下
w update 為 w + phi(xr, yr-hat) - phi(xr, yr-delta)
這樣更新的操略,其實就是 perceptron learning algorithm
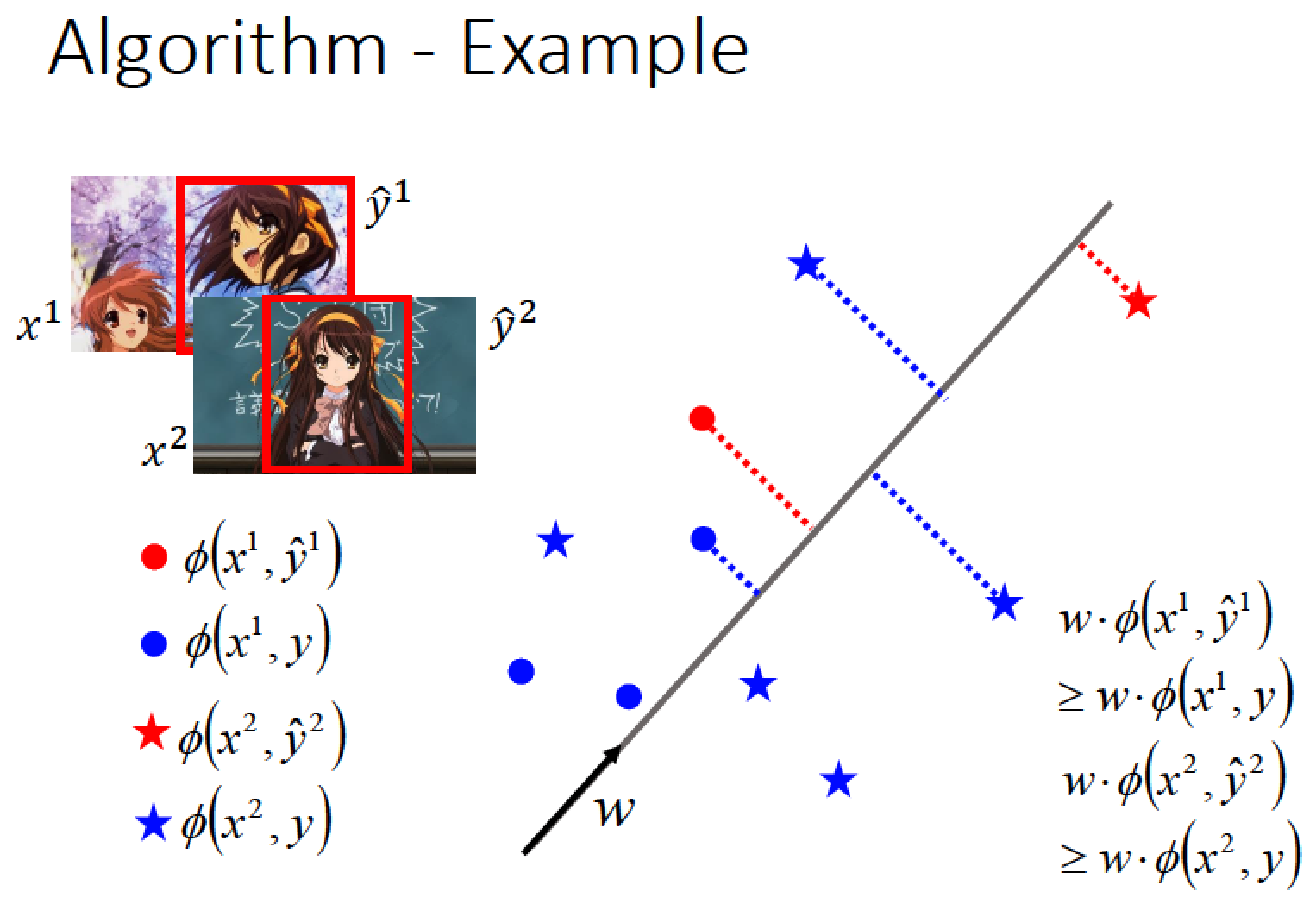
來舉個例子來說明一下,這個演算法是怎麼運作的

首先假設 w = 0
我們目前也只有兩筆 data (x1, y1-hat) , (x2, y2-hat)
先隨便 pick 一個 training data (x1, y1-hat)
我們要根據手上的 data 去看哪一個 y 代進去 w * phi(x1, y) 會有最大值
因為現在 w 是 0 所以不管選哪個 y 出來計算 w * phi(x, y)都是 0
所以先 random 找一個點 y 當作 y-delta
然後因為我們選出來的 y-delta 跟 y-hat 不一樣,所以要做調整
所以要更新 w
目前的 w 是 0 所以更新後,phi(x1, y1-hat) - phi(x1, y-delta)
得到一個圖中朝上的向量 w
接著,再選一個 training data (x2, y2-hat) (圖裡面的 紅色星星)

選了 (x2, y2-hat) 以後呢
我們要做的事情就是,窮舉所有的 y 看看哪一個跟 w 做 inner product 之後最大
我們假設找到一個 y2-delta (圖裡面最上面的藍色星星)
因為 y2-delta 也跟 y2-hat 不一樣,所以要更新 w
我們把紅色星星的 vector 減掉藍色星星 vector 得到綠色的 vector
然後再把上一步驟的 w 跟綠色的相加,得到一個新的 w (圖中往右上方向)
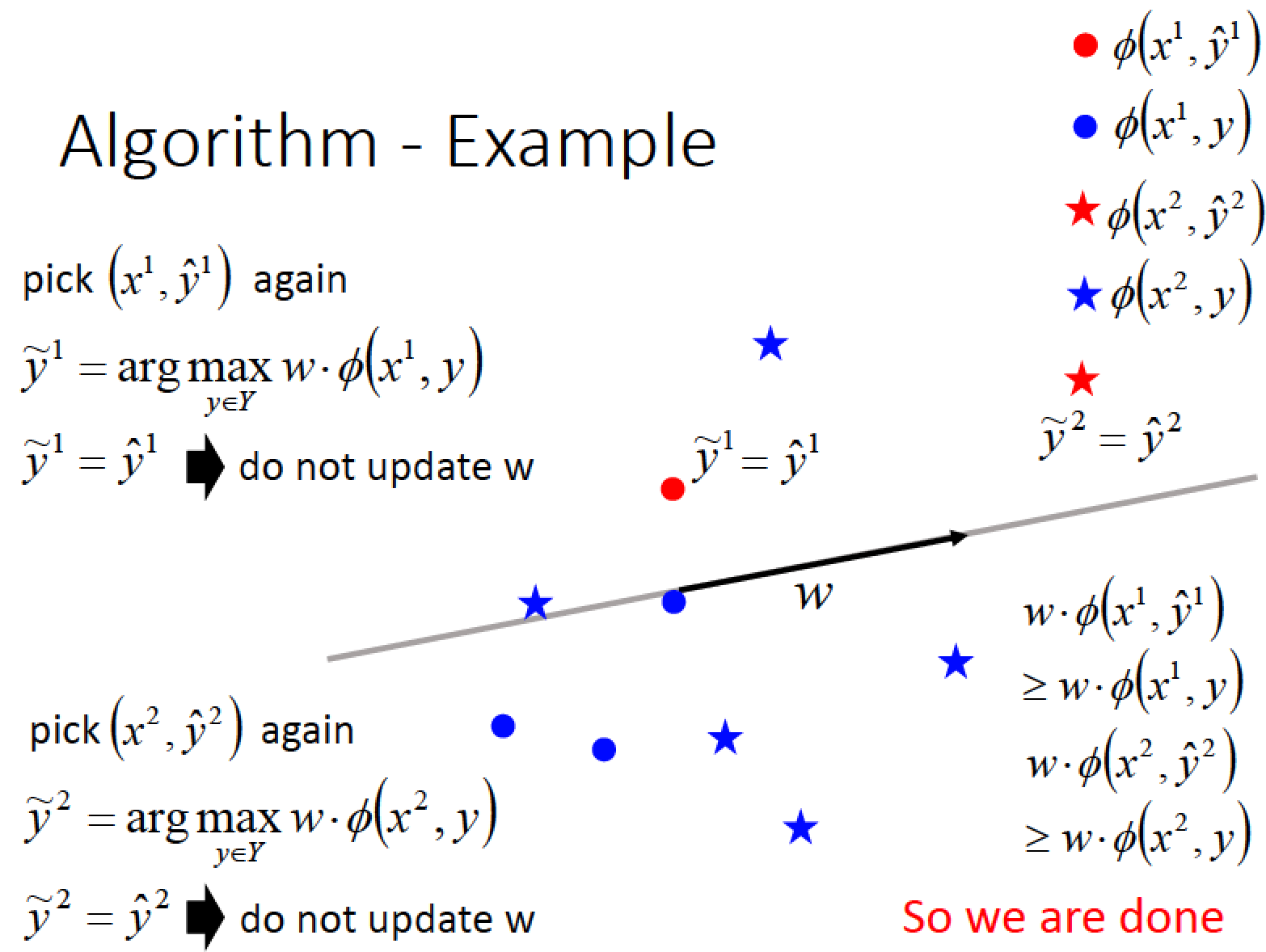
得到新的 w 以後,我們要繼續去看所有的點
新的 w 跟所有的點去計算 inner product 後
發現說他對於第一筆 data 而言 y1-delta 正好就等於 y1-hat
對於第二筆 data 而言 y2-delta 也正好等於 y2-hat
也就是說圖中紅色點跟 w 做 inner product 後的值大過所有藍色的點
紅色星星跟 w 做 inner product 後的值也大過所有藍色的星星
當 w 不再更新的時候,整個演算法就結束了!






留言
張貼留言