[ML筆記] Structured Learning - Introduction
ML Lecture 21: Structured Learning - Introduction
本篇為台大電機系李宏毅老師 Machine Learning (2016) 課程筆記
上課影片:
https://www.youtube.com/watch?v=5OYu0vxXEv8
課程網 (投影片出處):
http://speech.ee.ntu.edu.tw/~tlkagk/courses_ML16.html
目前為止的 input output 都只是 vector
但是我們面對的問題往往是 input 一個 sequence , output 另一個 sequence 或是
input 一個 tree structure,output 另外一個 tree structure
→ 做到 input 是一個 object,output 是另一個 object
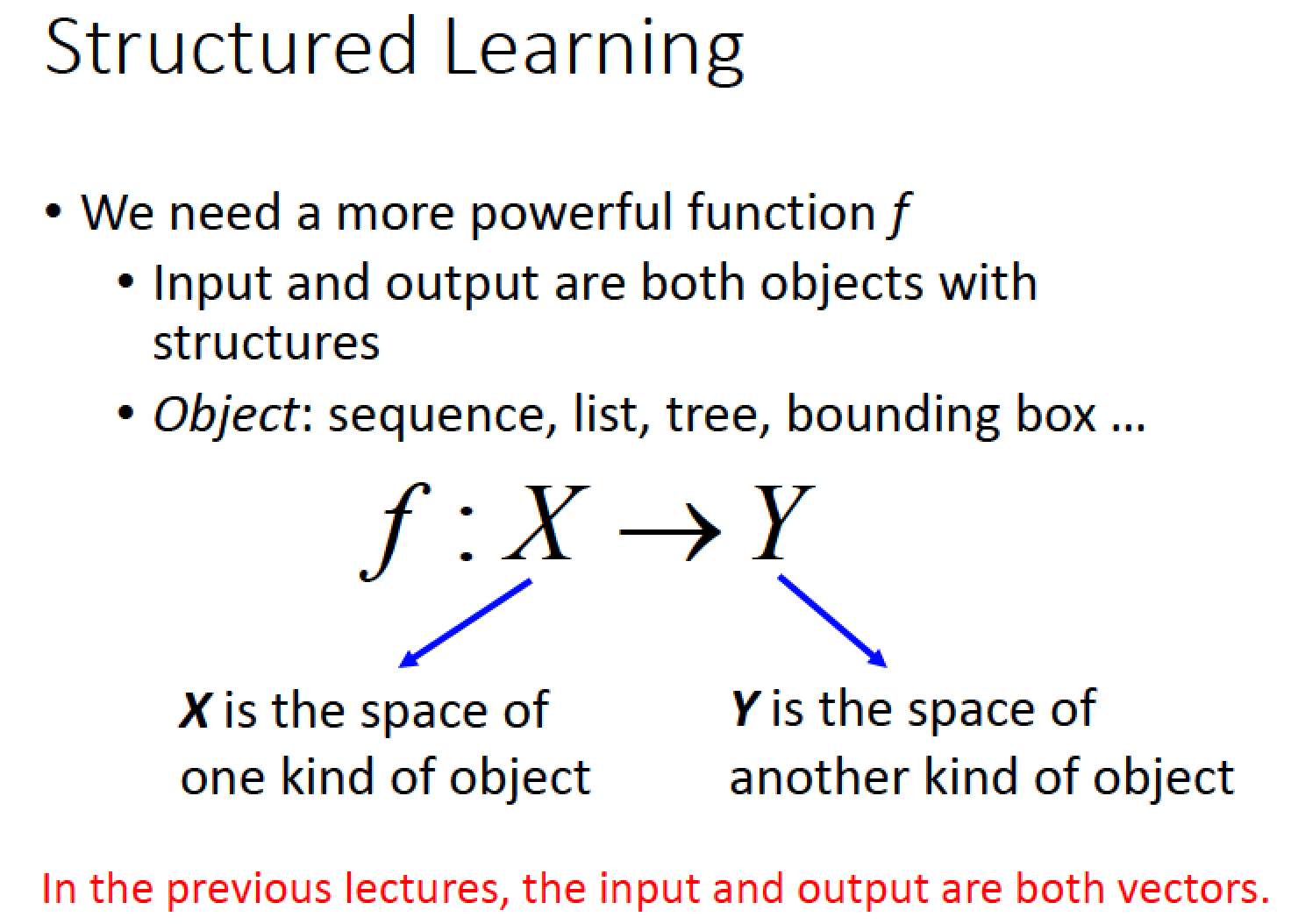
大原則:找一個 function input 是我們要的 object ,output 是另一個 object

Structure Learning 的應用層面非常多:語音辨識,翻譯,文法頗析
Image Object Detection 那個 bounding box 座標就是一個 object
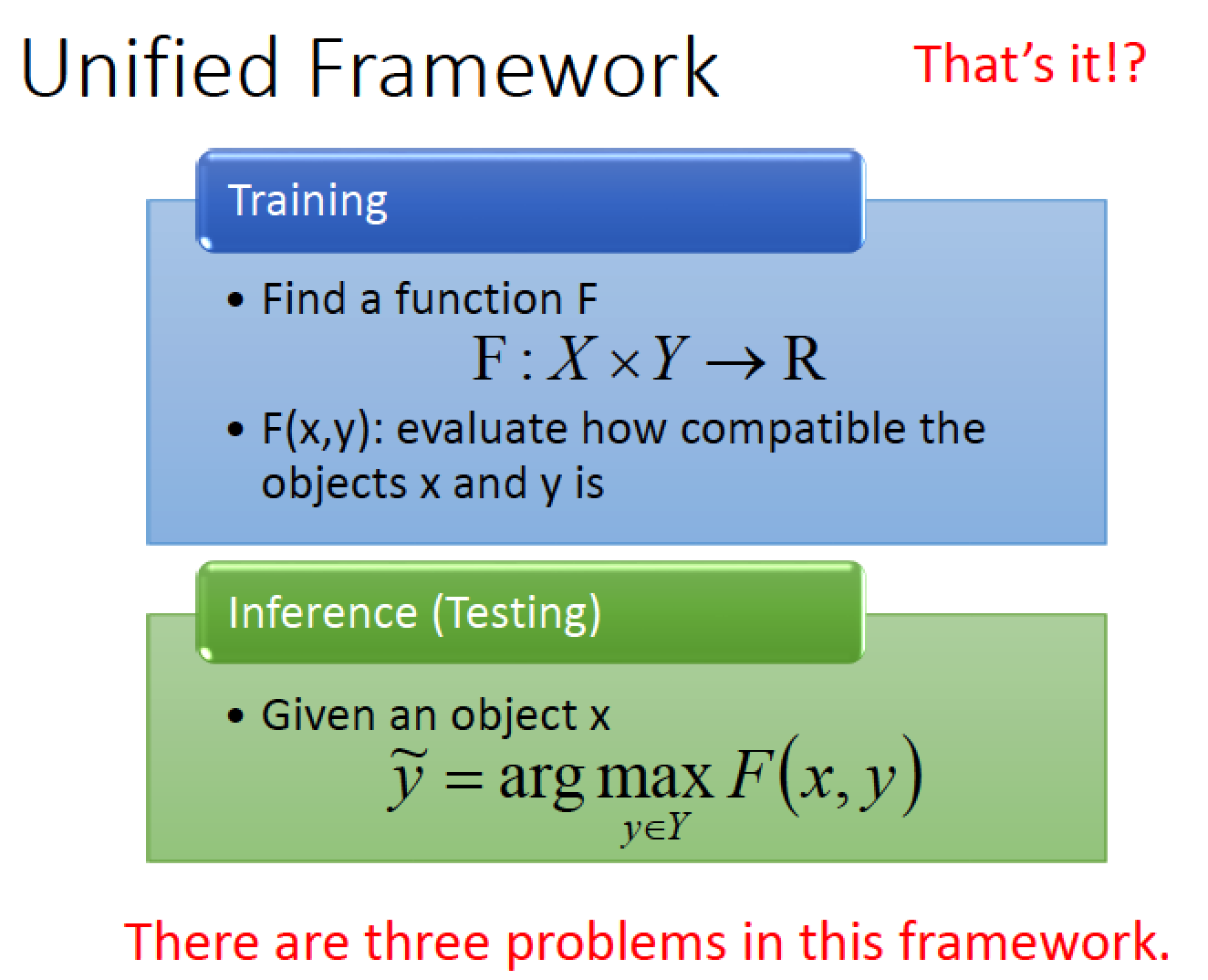
Structure Learning 有一個 Unified Framwork
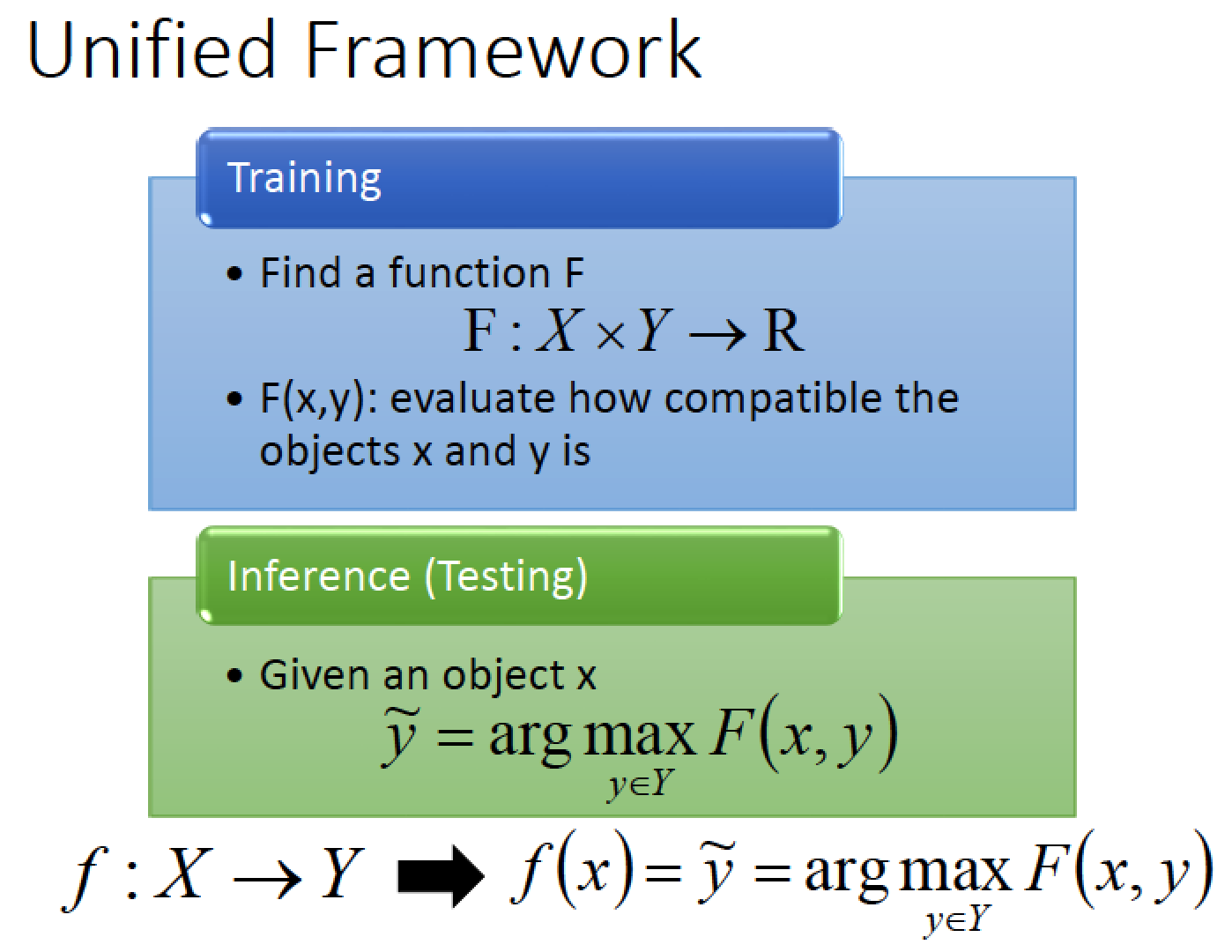
Training:
我們找一個 Function F ,他的 input 是 X 跟 Y ,他的 output 是一個 real number
x,y 如果越匹配,function 他的 output 值就會越大
Testing:
給一個新的 x 我們去窮舉所有可能的 y
假設窮舉出來的 y 有一個能讓 F 的 output 有最大值,則那個 y 就是最合 x 的 y
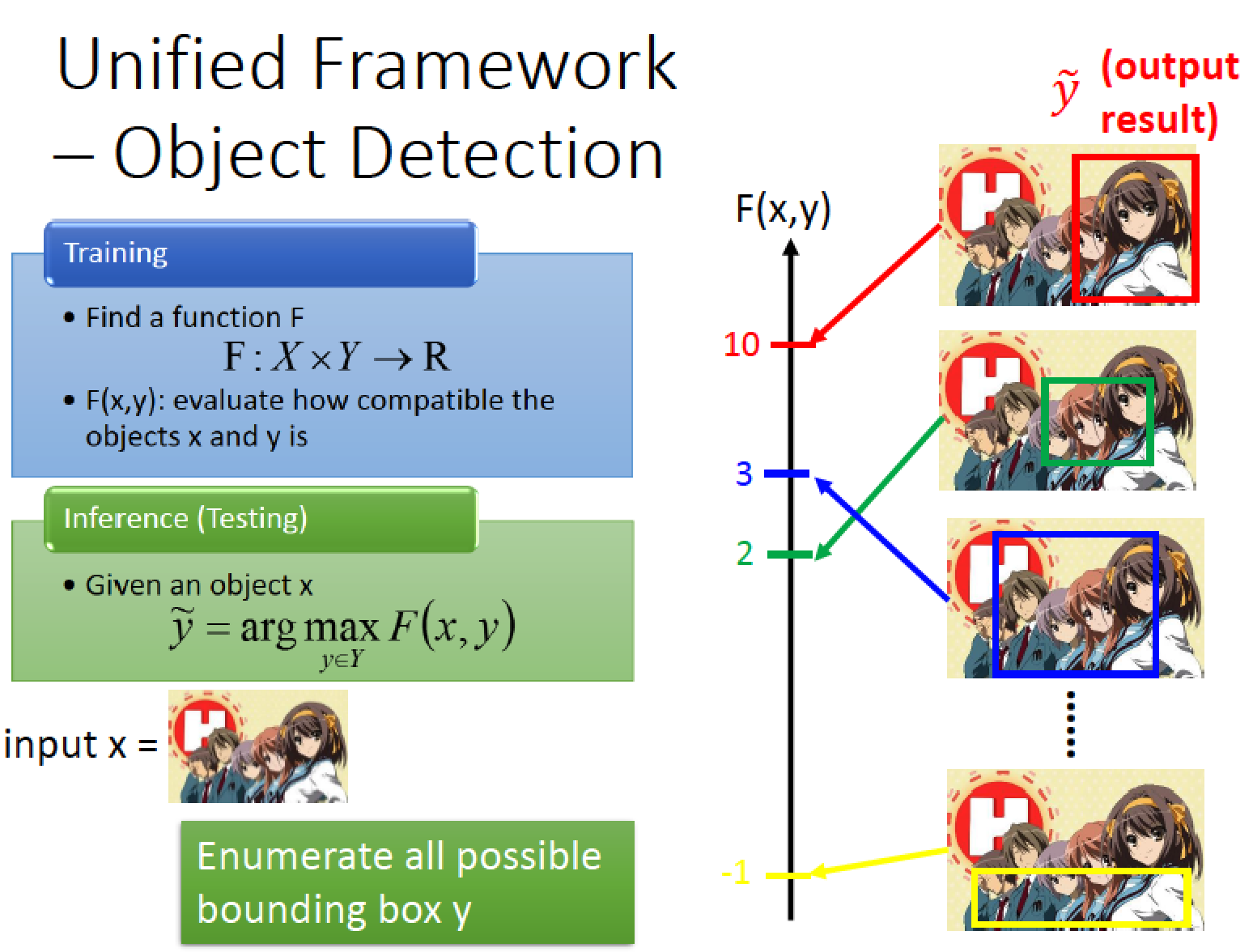
舉例來說:做 Image Detection for 涼宮春日
 input 一張圖,output 涼宮春日所在的位置 (bounding box)
input 一張圖,output 涼宮春日所在的位置 (bounding box)
這個例子中,目標就是input image 配上我們的 bounding box 有多 “匹配”
也就是我們框出來的有多正確

做法:窮舉所有可能的 bounding box 看看哪個 bounding box 可以得到最高的分數,
最高分數的 bounding box 就是我們要找的!
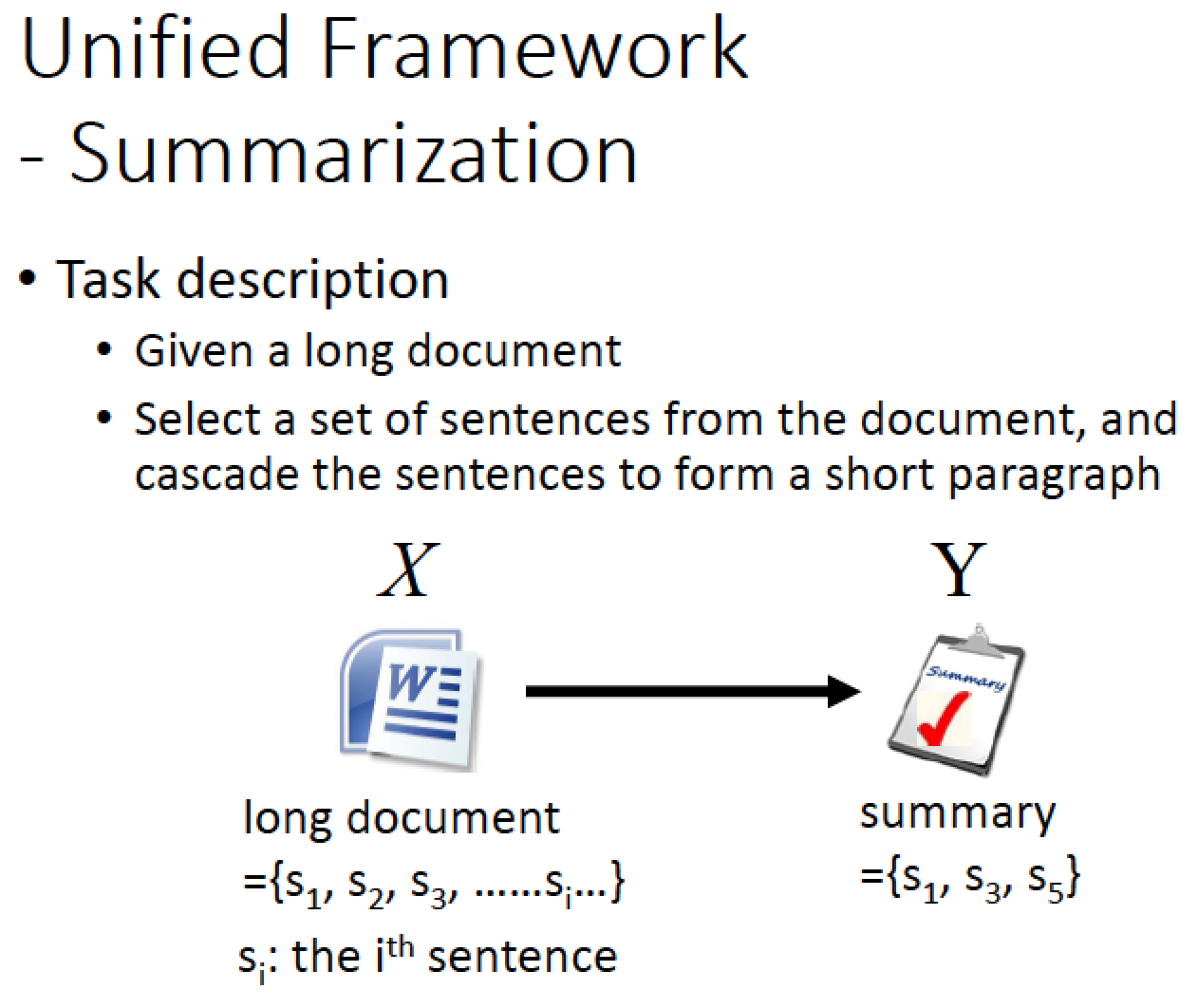
在別的 Task 裡面也是差不多的
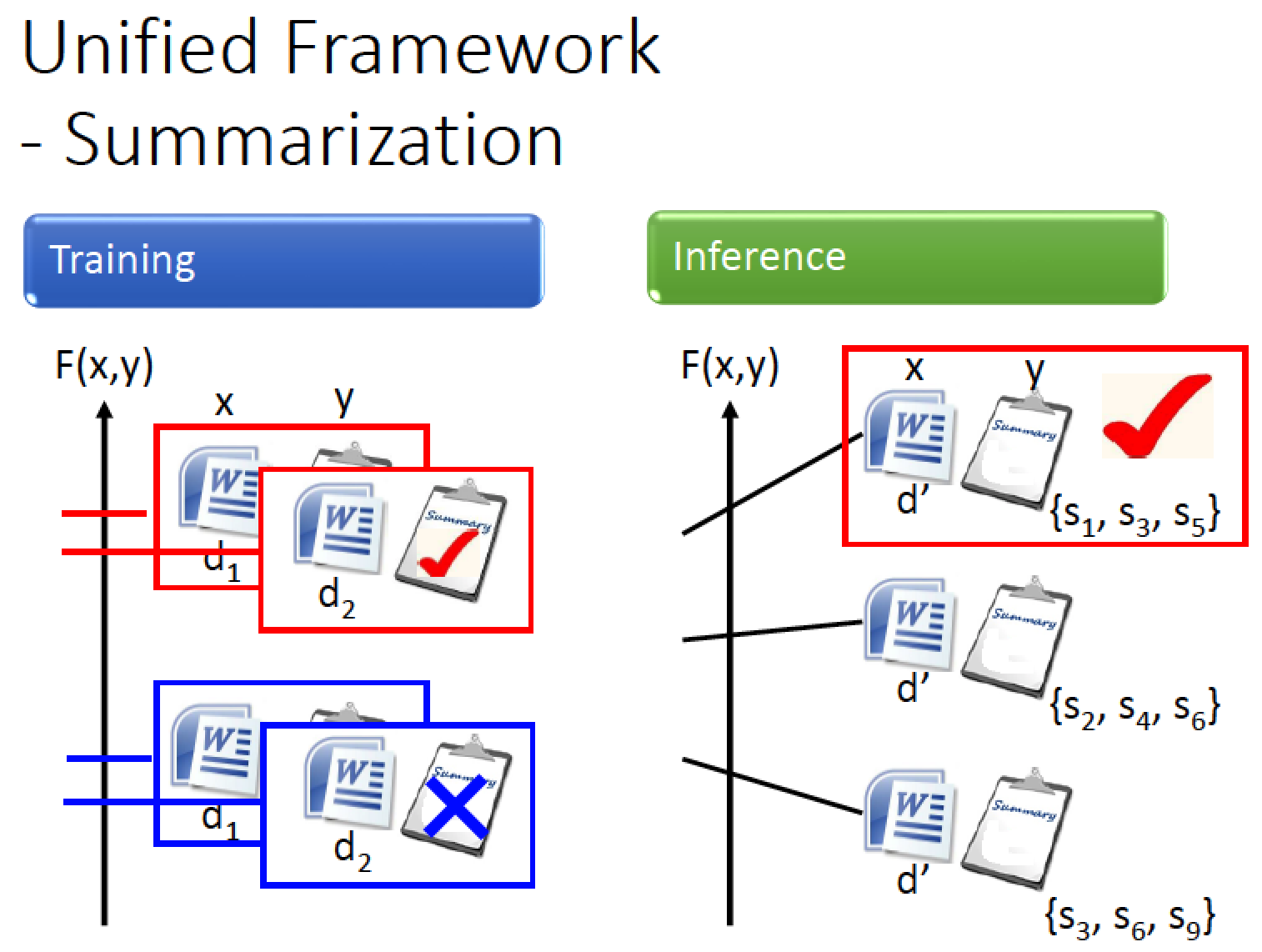
例如在做 Document Summarization 的時候
input 是一篇很長的 document 他有很多句子
output 是一個 summary ,這個 summary 是從 document 當中取幾個句子出來的組合
Training 時:
document 跟正確的 summary 匹配時,我們的 F 值就會很大
document 跟不正確的 summary 匹配時,我們的 F 值就會很小
Testing 時:也是窮舉所有可能的 summay 看哪一個 summary 可以讓 F 分數最高
或是做 Retrieval 時,在搜尋引擎的 Task 上
input 是一個查詢值
output 是一個 webpage 的 list


Training 時,就必須要有 input 以及正確的 list 匹配,讓分數變高
在 testing 時,假設我們搜尋涼宮春日,那我們就會窮舉所有可能的 List ,
看看哪個 list 能讓 F 的分數最高。
你可能會想說 “窮舉所有可能” 多荒謬,但是這件事情是可以做的,
我們只需要一個好的演算法來解這個問題即可
另一種說法解釋 Structure Learning Unified Framework

Training 的時候我們是要 Estimate X 跟 Y 的 Joint Probability
X 跟 Y 一起出現的機率,就是一個介於 0 ~ 1 的值
Testing or Inference 的時候,就是
給我一個 object X ,我們去計算 P(y | x) 計算,哪一個 y 的機率最高,
就是我們要的 y
看看哪一個 y 跟 given x 的 Joint Probabity 最高,找最有可能的 y

看 Graphical model 的文獻,發現大部分都是用機率再講,其實講的是一樣的問題
用機率來講的話有個壞處,機率有限制,會花很多時間在做 normalization
Energy-based model 講的也是 structure learning
這個 Framework 要做的話,要解三個問題
問題1: F(x,y) 應該長什麼樣子

問題 2:如何窮舉所有可能的 y ?

問題3:training 的時候我們希望正確的 x,y 可以大過其他的可能
這個 training 是可完成的嗎

只要能夠解這三個問題,就可以做 Structure Learning

GAN 是解這三個問題的 solution !
數位語音處理時的三個問題,其實也是這三個問題

Structure Learning 跟 DNN Link 在一起:
之前講過的 DNN 其實也可以視為 Structre Learning 的 special case
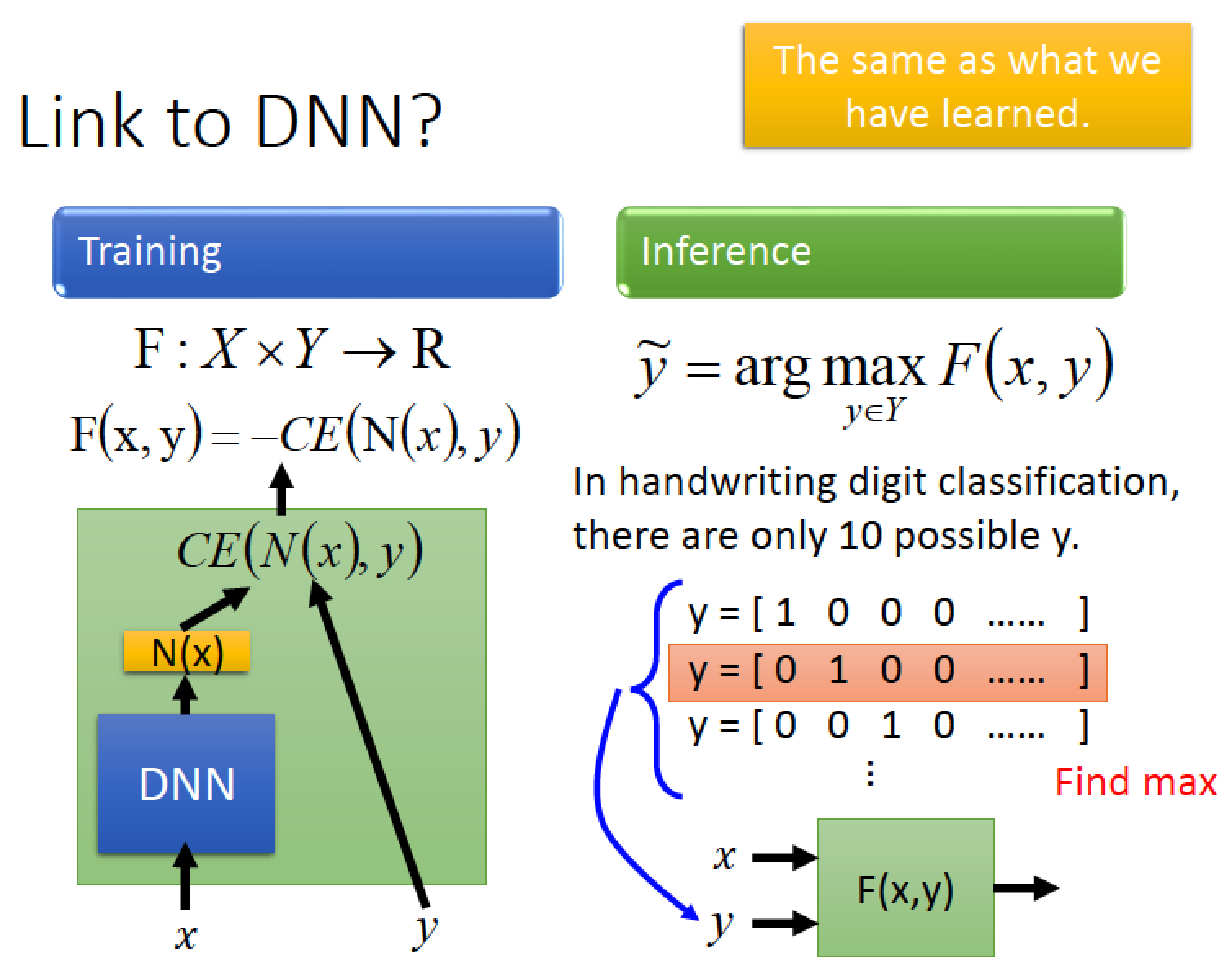
例如在做 MNIST 手寫數字辨識的 Task 時:
先把 X 丟進一個 DNN 然後再 input 一個 y ,這個 y 是一個 10 維的 vector,
它只有一個維度是 1 其他都是 0
然後把 y 跟 N(x) 做 cross entropy (CE) ,負的 CE(N(x), y) 就是 F(x,y)
接下來在 testing 或是說在 inference 的時候:
我們就窮舉所有可能的辨識結果 (這個案例中也只有 10 個可能的辨識結果)
窮舉 10 個可能的辨識結果,這 10 個 y 長這樣
[1, 0, 0, 0, 0, 0, 0, 0, 0, 0]
[0, 1, 0, 0, 0, 0, 0, 0, 0, 0]
[0, 0, 1, 0, 0, 0, 0, 0, 0, 0]
[0, 0, 0, 1, 0, 0, 0, 0, 0, 0]
[0, 0, 0, 0, 1, 0, 0, 0, 0, 0]
[0, 0, 0, 0, 0, 1, 0, 0, 0, 0]
[0, 0, 0, 0, 0, 0, 1, 0, 0, 0]
[0, 0, 0, 0, 0, 0, 0, 1, 0, 0]
[0, 0, 0, 0, 0, 0, 0, 0, 1, 0]
[0, 0, 0, 0, 0, 0, 0, 0, 0, 1]
看哪一個辨識結果 y,可以讓 F(x, y) 最大,他就是我們要的辨識結果!





留言
張貼留言