[ML 筆記] 自注意機制 Self-attention (上)
Self-attention 筆記(上)
本篇為台大電機系李宏毅老師 Machine Learning (2021) 課程筆記
上課影片:https://youtu.be/hYdO9CscNes
定義 Sequence-to-Sequence (Seq2seq) 的問題
將 Input 視為一個 Sequence:
例如文字資料處理,我們可以把句子中每個詞彙都描述成向量集 Vector set
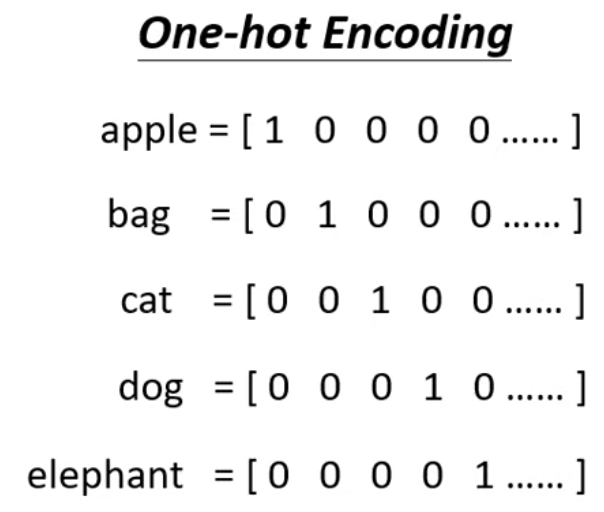
而把文字表示成向量的方法很多,其中一種做法是 One-hot Encoding
這個 encoding 有個很明顯的缺點,就是它假設所有詞彙都是沒有關係的
例如下圖當中,我們無法從 encode 後的 vector 看出這五個單字哪些比較相近
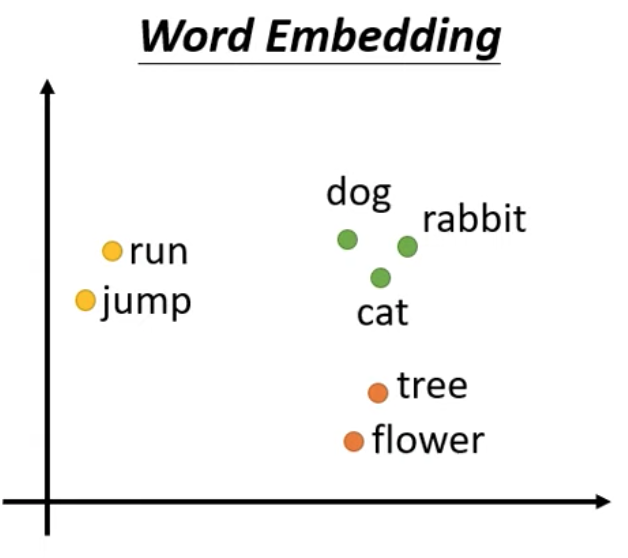
另一個常見的作法就是使用 Word Embedding 細節在此先不討論,有興趣可以查相關文章
聲音訊號的 input 也是一個 Sequence,
在描述聲音訊號時,我們會設定一個 frame (或是講成一個 window) size 通常訂 25ms
再將 window 逐步往右移動,移動的步伐時間長度通常設定在 10 ms

我們也可以把 social network 的 graph 看作是一堆的向量組成
或是分子結構,一個分子也可以看作是一堆向量,有了一堆向量,就可以視為一串 sequence

接下來可能會問
Input 是一串 Sequence 的模型,輸出有哪些可能性?
類型一:輸出跟輸入數量一樣,一對一,每個輸入都對應一個 label
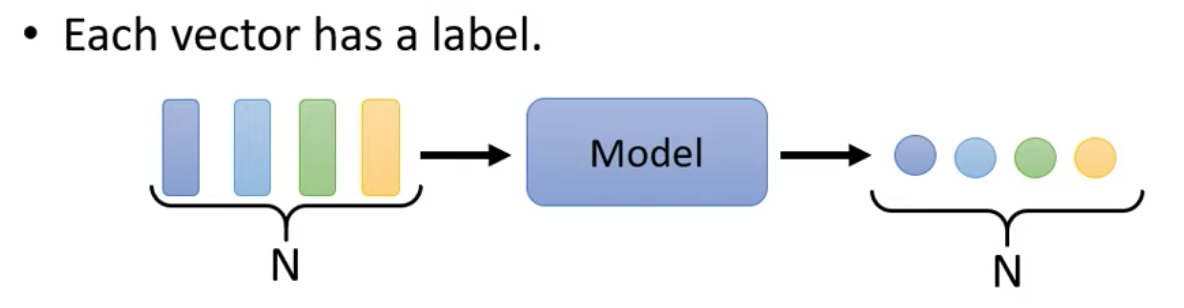
例如:
類型二:整句輸入對應到的輸出是一個 label

類型三:輸出的長度是不固定的,交由機器自行決定
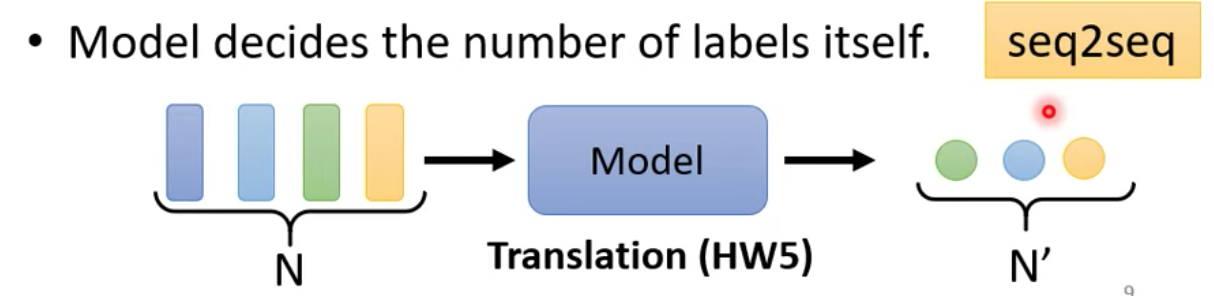
在此我們先討論第一種類型,輸入輸出數目一樣多的類型的問題
這樣的類型又稱為:Sequence Labeling
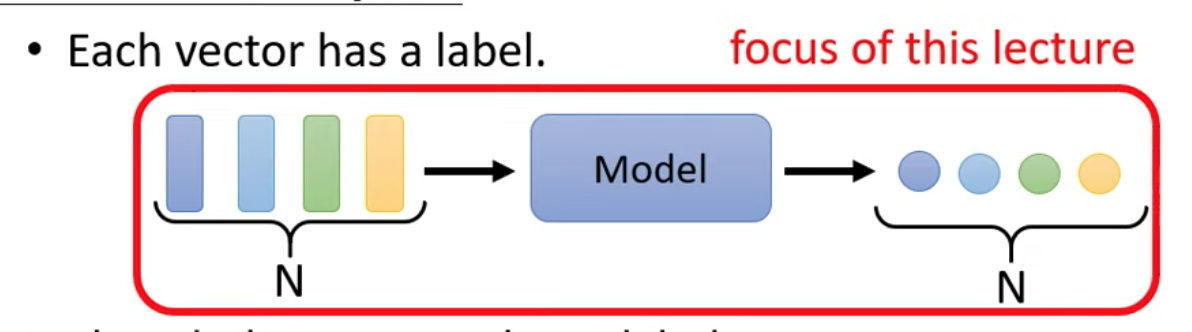
input sequence 與 output sequence 是一對一的對應關係
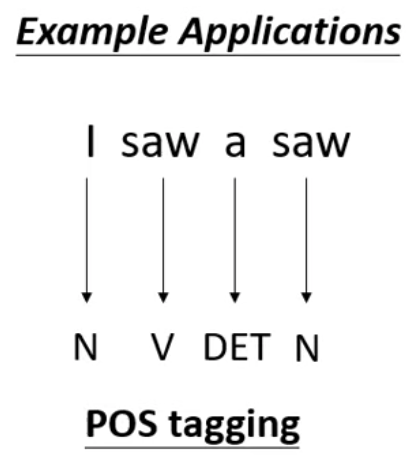
假設 input 一個句子 “I saw a saw” (我看到一個鋸子) 要做到詞性標記問題

我們期待
第一個 saw 要輸出動詞
第二個 saw 要輸出名詞
如果我們把每個 input 都分別丟到 fully connected network 的話,無法做到這樣的事情 (當輸入都是相同的單字 saw 不可能產生不一樣的 output)
因此為了做到這樣的事情,我們可以把上下文的 input 向量都串起來,一起丟到 fully connected network 裡面
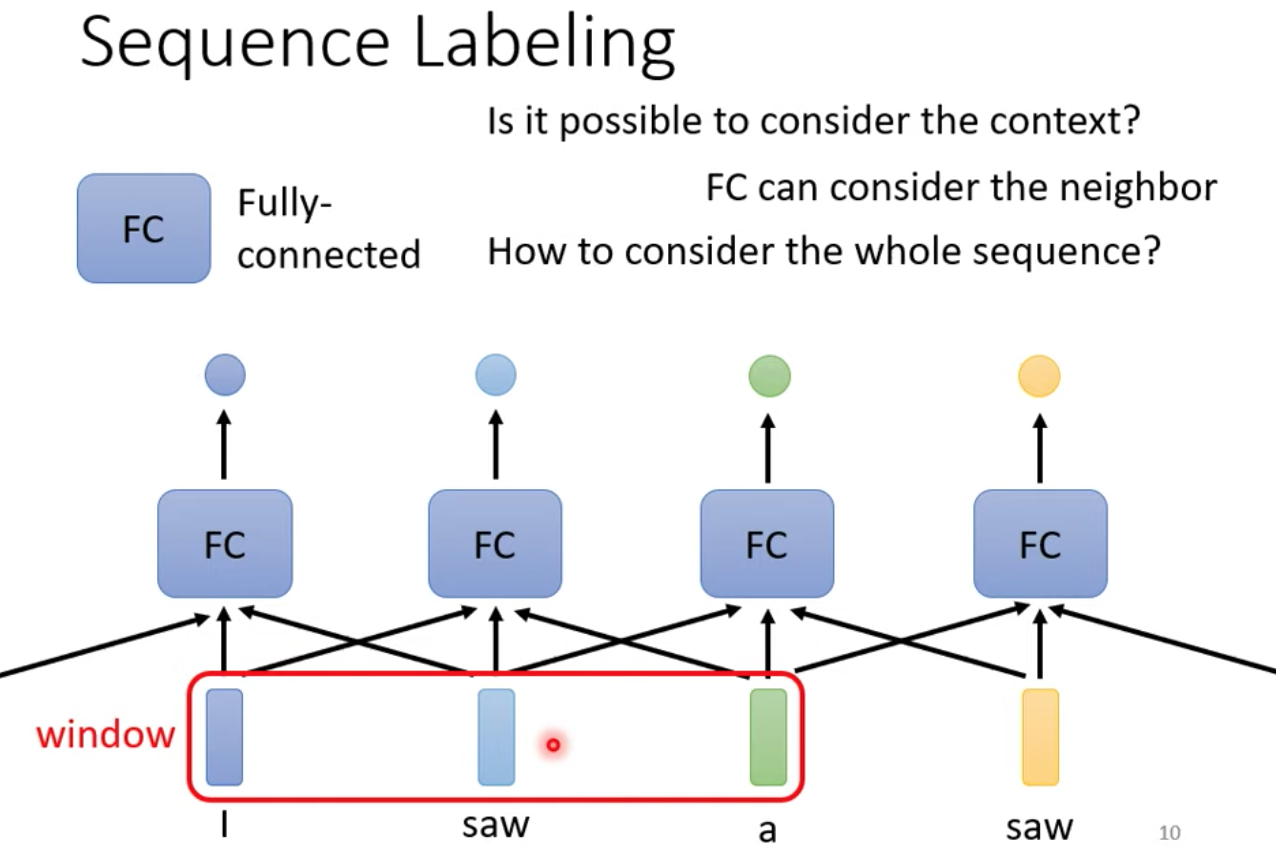
我們可以給 fully connected network 一整個 window 的資訊,讓他考慮上下文相鄰的資訊來產生適當的 output
但這樣的做法還是有極限,如果有個任務,需要考慮整個 sequence 才能解,該怎麼辦呢?
sequence 的長度是有長有短,根本不知道極限在哪
因此需要用到接下來要介紹的 self-attention 的這個技術
Self-attention 架構簡介

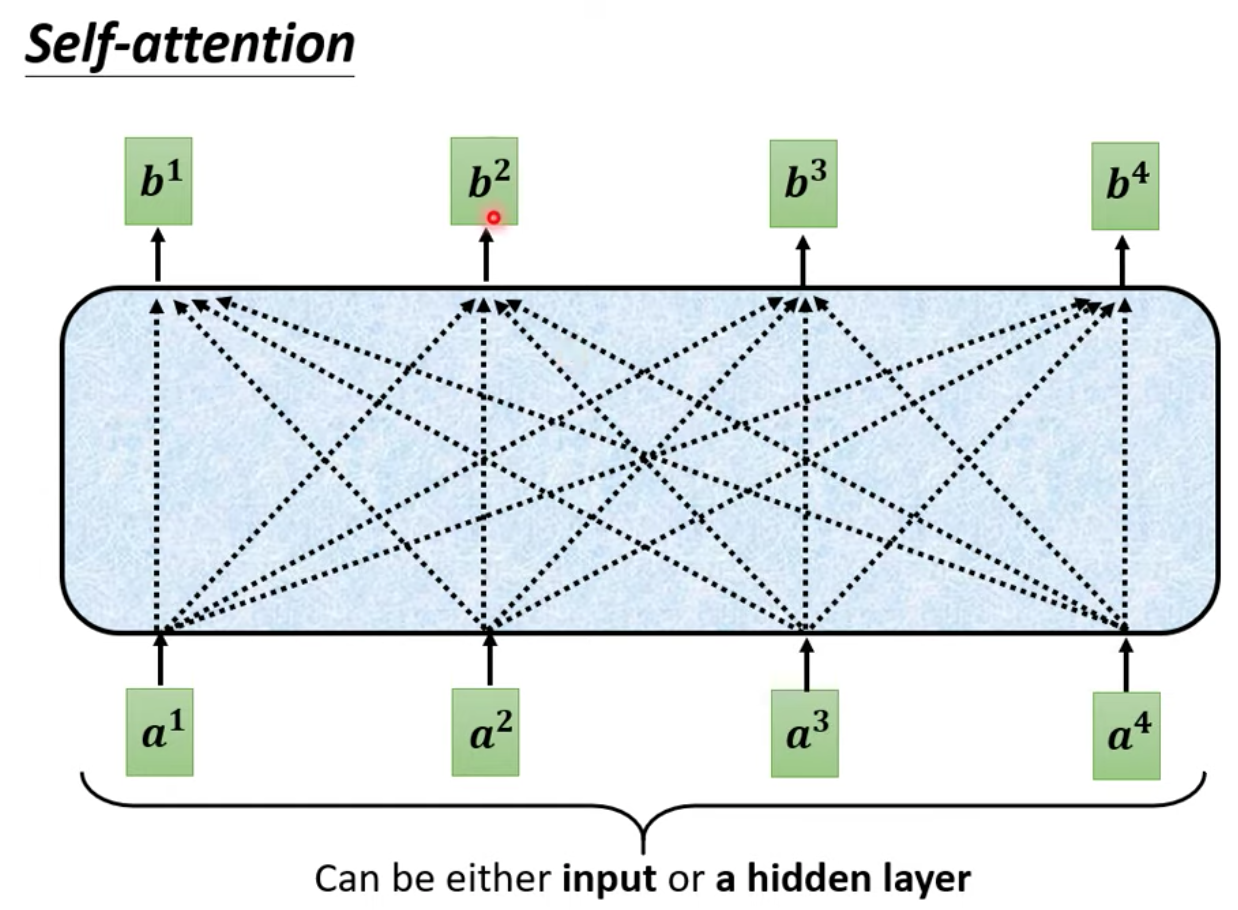
如圖:四個 input 的 vector 過了 self-attention layer 後,分別加了黑色框框,代表著這四個 vector 都已經考慮過整個 sequence 的資訊了
過了 self-attention 後,可以使得每一個 input vector 對應的 output 都考慮過整個 input sequence 當中的所有資訊了,然後再把 output 拿去做後續的處理,像是過 FC
這樣的 Self-attention 架構可以任意延伸擴大,將 attention 跟 Fully connected netword 混搭
例如這樣

接下來介紹 self-attention 的詳細內容
Self-attention 詳細架構
self-attetion 的 input 是一串的 vector 一排 a 向量
output 是另一排 b 向量
每一個 b 都是考慮了所有的 a 以後才產生的
(每一個 output 向量,都是考慮了每一個 input 所產生的)
接下來,來說明怎麼產生 b1 這個向量,知道了 b1 怎麼產生,就同理知道其他的 b2,b3,b4... 向量怎麼產生的
根據 a1 向量,找出整個 sequence 裡面到底哪些部分是重要的資訊!
每一個向量跟 a1 的關聯程度用 ꭤ 來表示
此時,我們需要一個計算模組:兩個向量輸入,輸出 ꭤ 值

ꭤ 的計算方法:
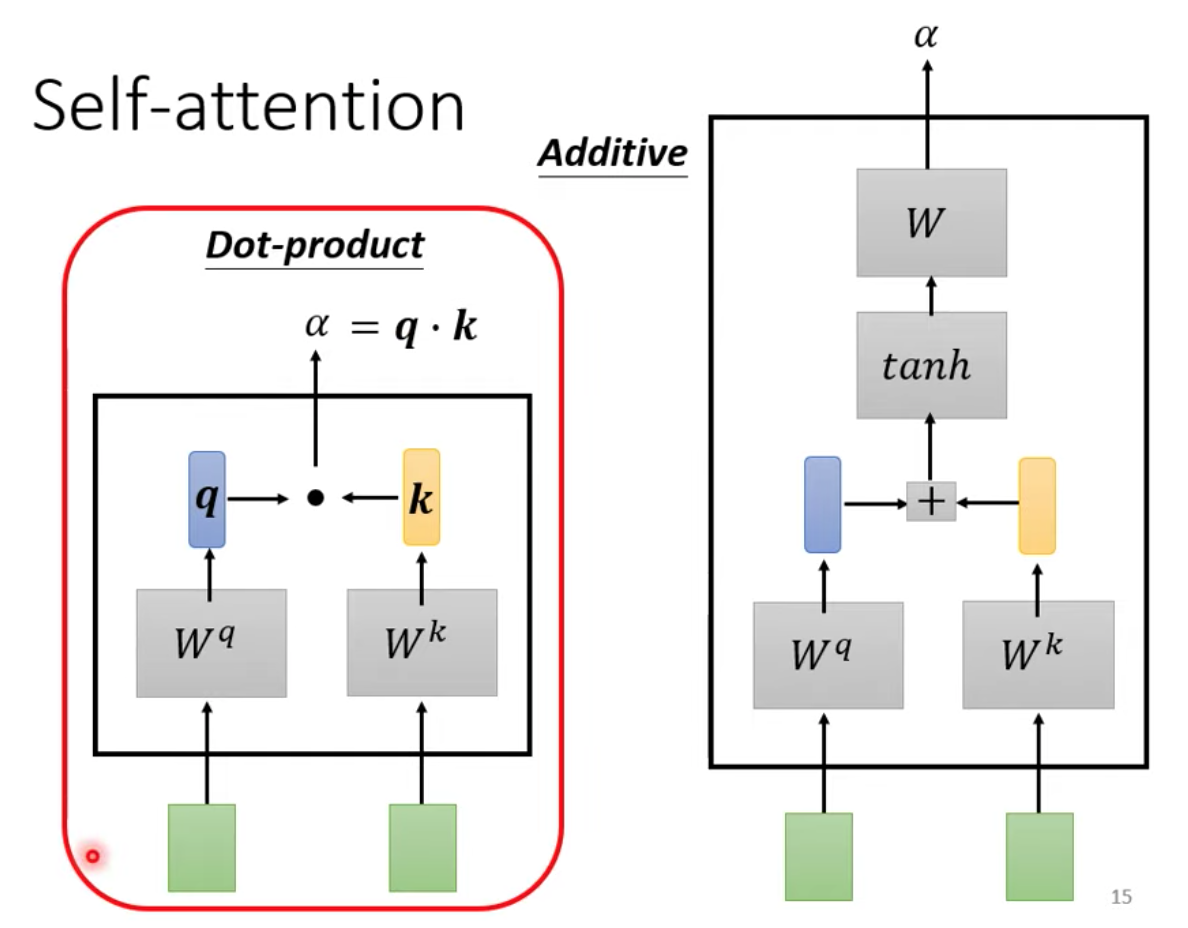
補充說明:

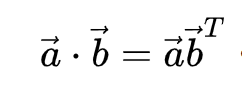


把 a1 跟 a2, a3, a4 分別都去做 ꭤ 的計算,計算出關聯性
我們把 input a1 乘上 Wq 得到 q1 我們把 q1 vector 稱為 query,代表我們要搜尋的目標
把 a2 乘上 Wk 得到 k2,我們把 k2 這個 vector 稱為 key
把 q1 跟 k2 做 dot-product 就會得到 ꭤ(1,2) 這個值我們稱為 attention score
同理 q1 跟 k3, k4 分別可以算出關聯性
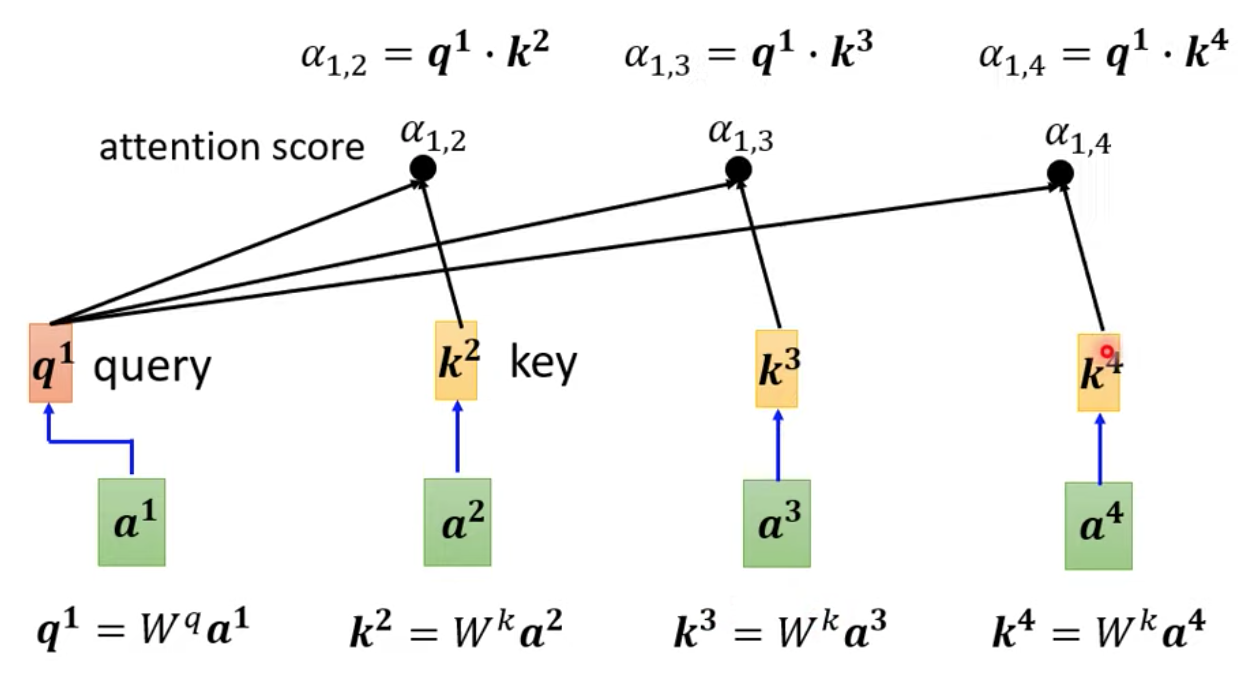
實作上,我們也會把 a1 跟自己做關聯性的運算!

做完 a1 跟每一個向量的關聯性 ꭤ 之後,我們會過一個 softmax 得到 ꭤ’
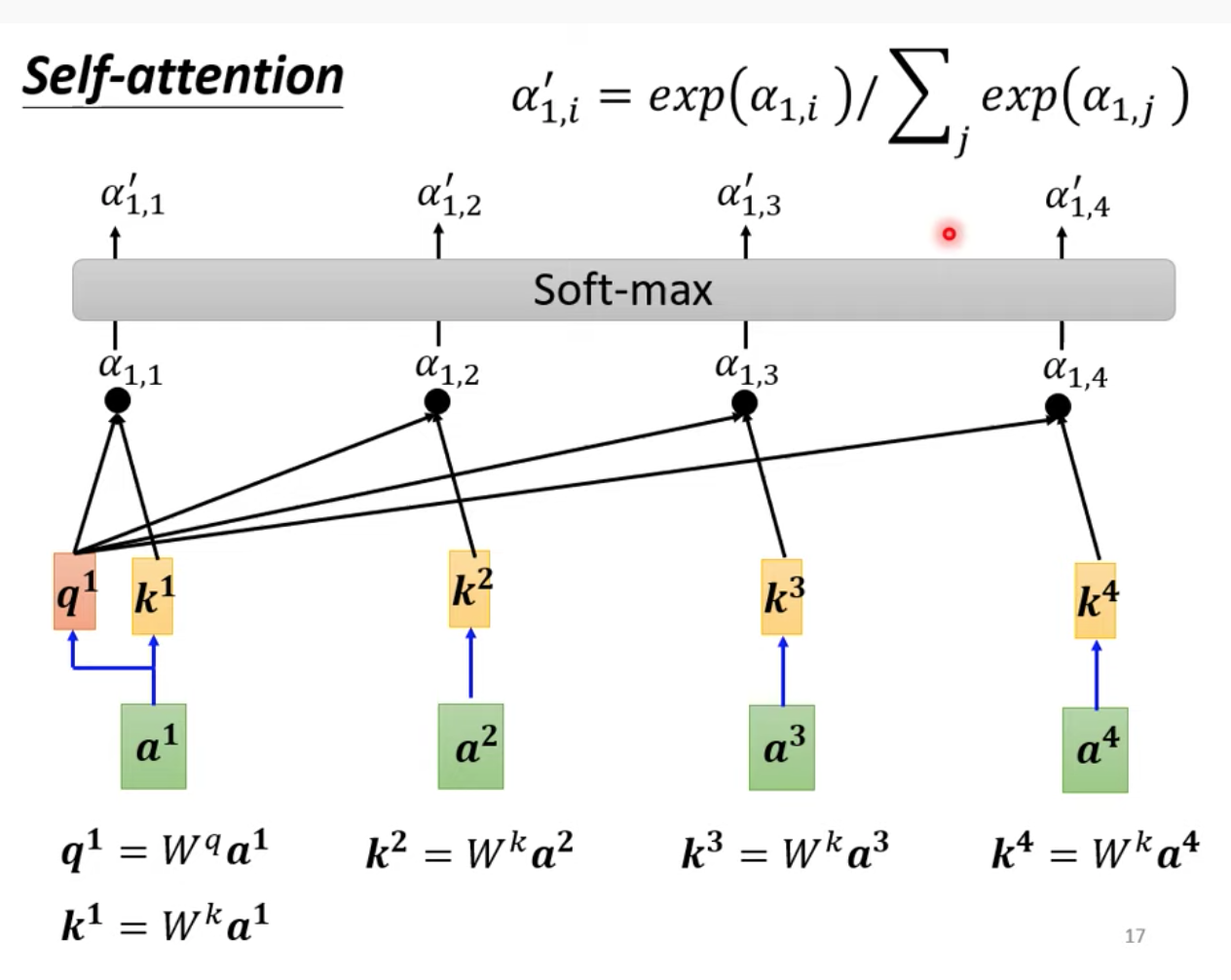
這邊其實也可以不用過 softmax 可以自己試試看,有些實驗中換成 reLU 會得到更好的結果
得到 ꭤ’ 以後,接下來我們就要根據 ꭤ’ 來 sequence 裡面抽取重要的資訊

我們把 a1, a2, a3, a4 乘上 Wv 得到 v1, v2, v3, v4
接下來把 v1 到 v4 每一個向量都分別去乘上對應的 ꭤ’ 全部加起來,就可以得到 b1 值

如此終於完成了 b1 的計算!
同理,b2 也仿照相同的步驟計算出來
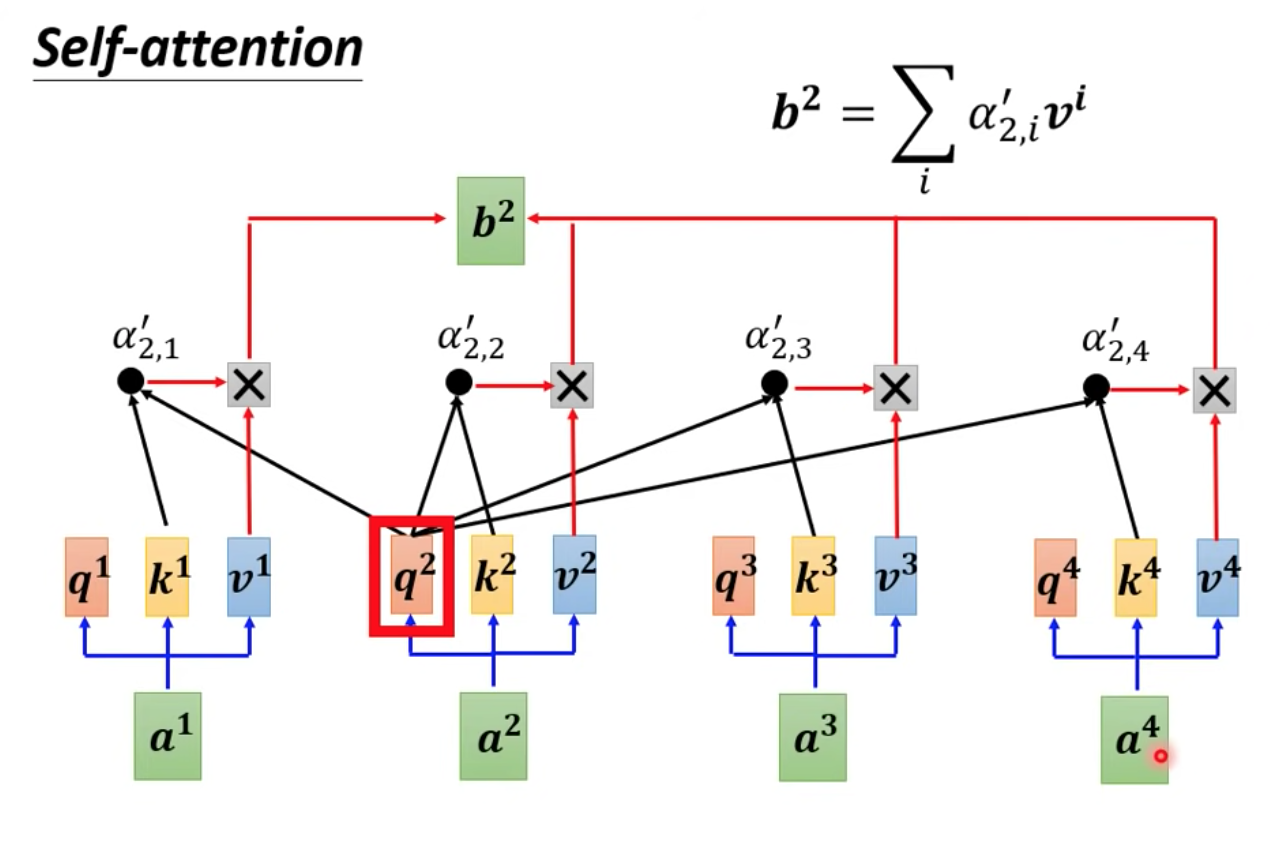
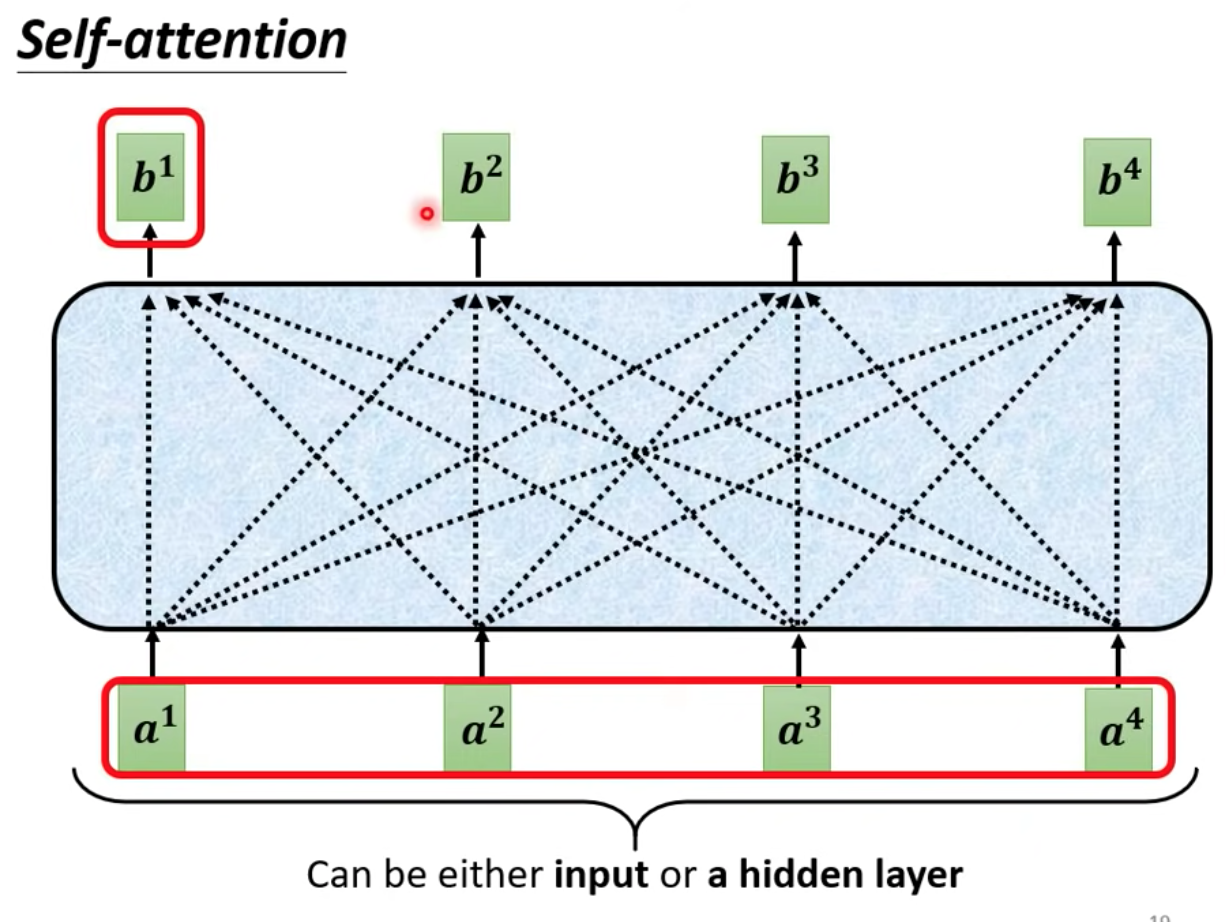
這裡的 b1 ~ b4 的運算是可平行化的!不需要依序運算






請問有程式碼可以看嗎?因為有些看影片我覺得還是沒那麼懂
回覆刪除