[ML 筆記] 自注意機制 Self-attention (下)
Self-attention 筆記(下)
本篇為台大電機系李宏毅老師 Machine Learning (2021) 課程筆記
上課影片:https://youtu.be/gmsMY5kc-zw
延續上一篇 [ML 筆記] 自注意機制 Self-attention (上)
Self-attention 的詳細架構介紹,先複習一下
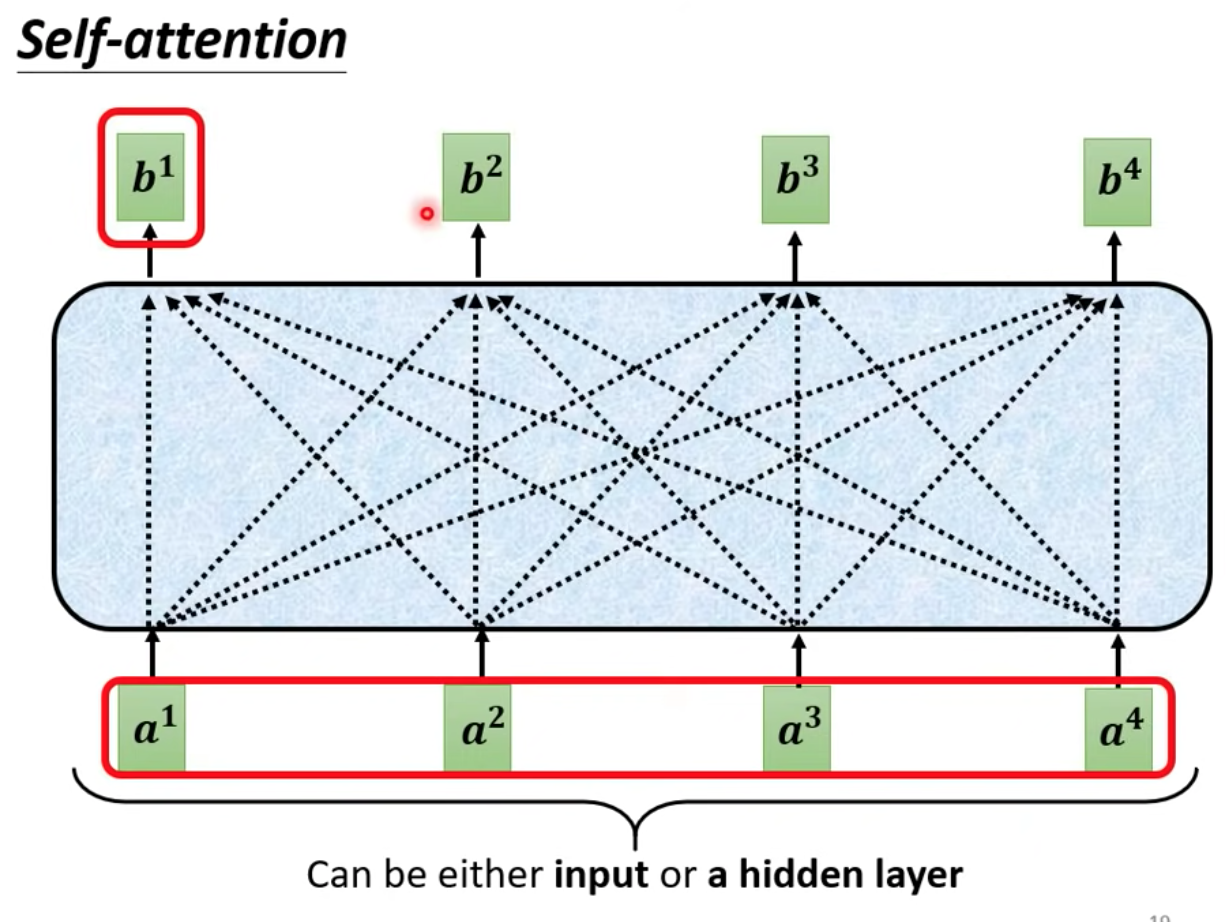
我們的 Self-attention 的 input 是個 sequence (a1 ~ a4) output 端是另一個 vector (b1 ~ b4)
以下是計算出 b2 的過程:
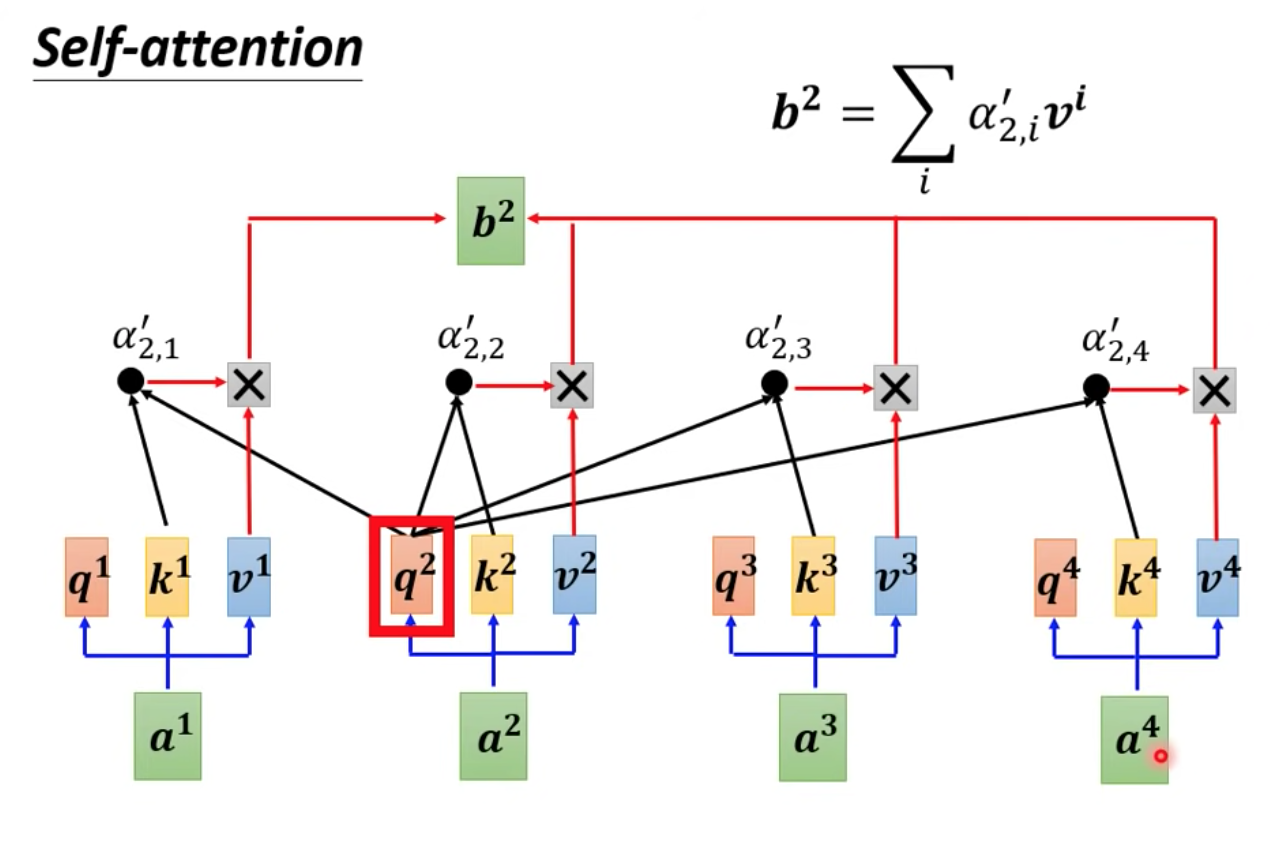
我們把 a2 過一個 Wq 矩陣,算出 q2 ,把 a2 過一個 Wk 矩陣,算出 k2
然後把 q2 跟 v2 做 dot-product,得到 ꭤ’2,2 (這個參數稱為 attention score)
再把 a2 過一個 Wv 矩陣,算出 v2 乘上跟 ꭤ’2,2 得到 b2
我們可以用矩陣的表示法,來描述上述的運算過程
Q 矩陣,代表 q1 q2 q3 q4 這些 vectors
I 矩陣,代表了 a1 a2 a3 a4 這些 vectors
K 矩陣,代表了 k1 k2 k3 k4 這些 vectors
V 矩陣,代表 v1 v2 v3 v4 這些 vectors
Q = Wq x I
K = Wk x I
V = Wv x I

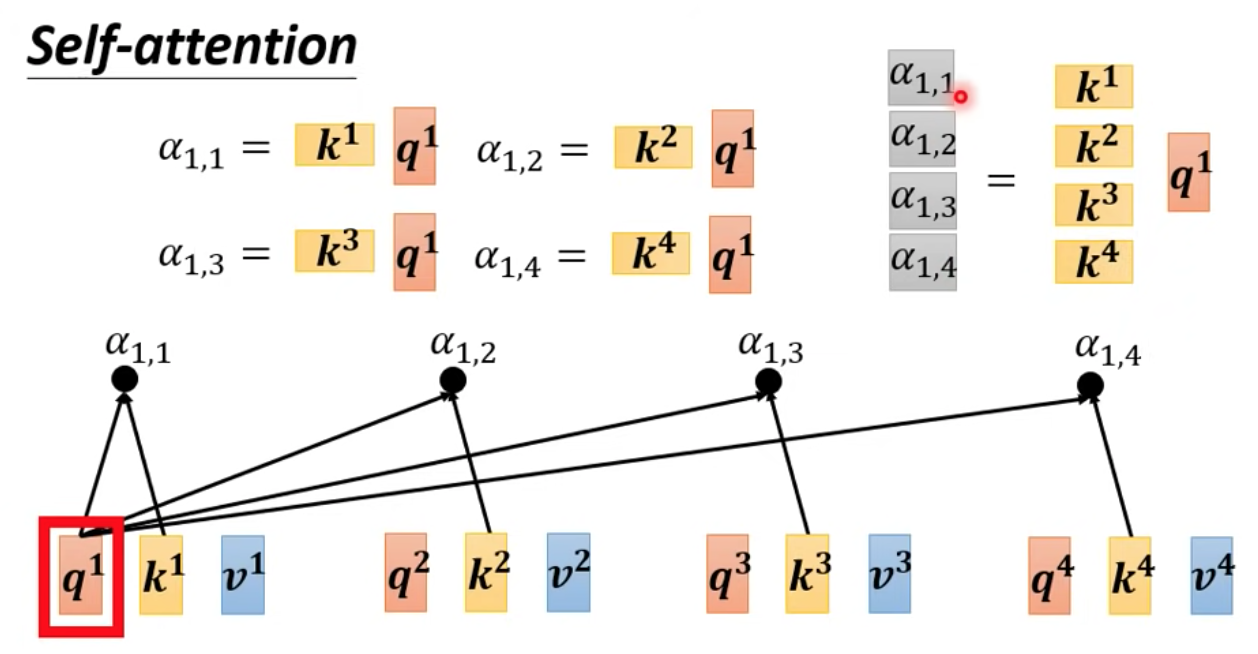
計算 𝛂1,1 ~ 𝛂1,4
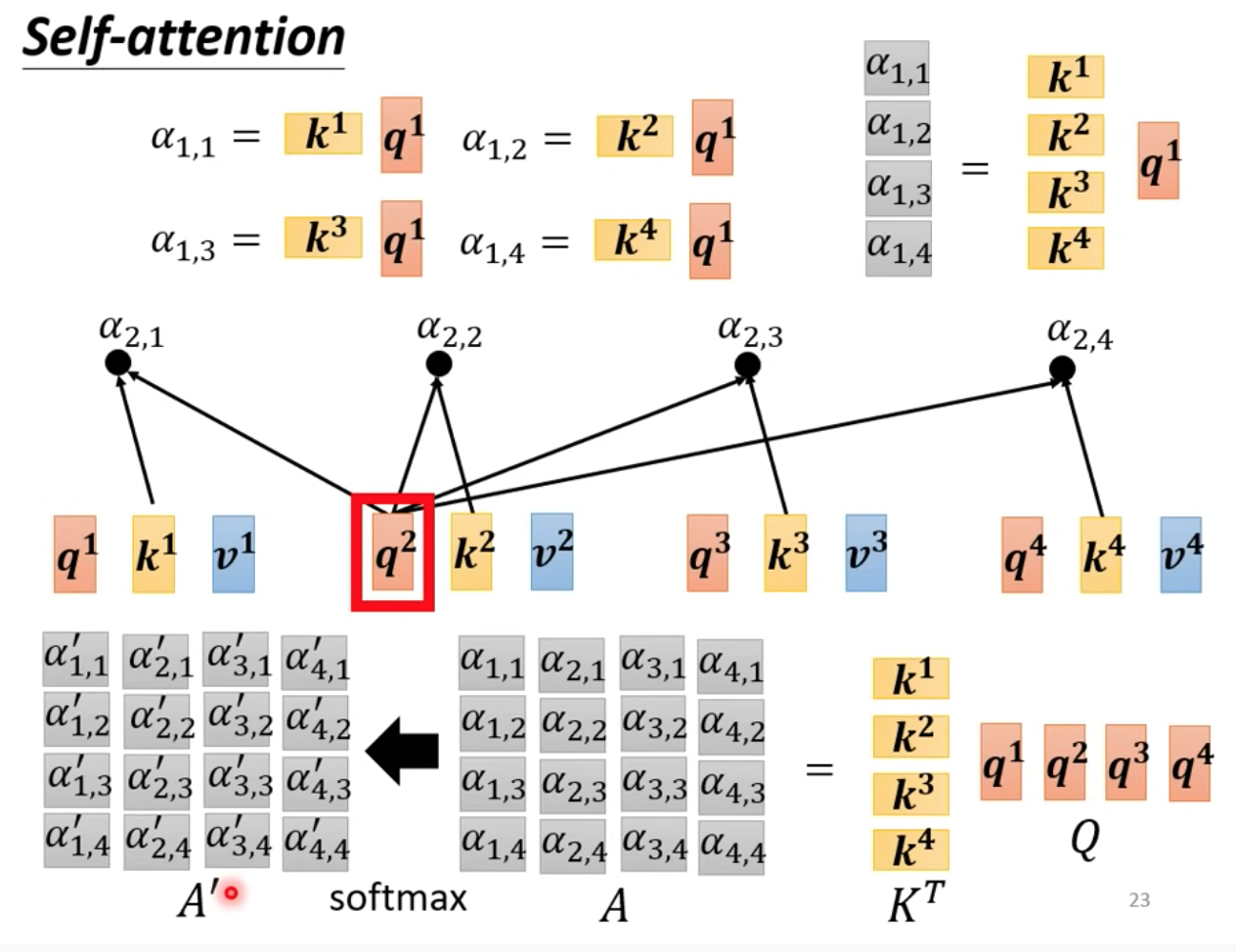
得到過完 softmax 後的矩陣 A’ 後
就可以拿來計算出 b1 ~ b4 值

整個複習一下
I 是 self-attention 的 input
I 經過不同的 W 矩陣運算後,得到 Q, K, V

得到 Q, K, V 之後,可以使用 KTQ 得到 A 矩陣
得到 A 矩陣後過了 softmax 或是其他 activation function 得到 A’
得到 A’ 矩陣後,乘上 V 矩陣就可以得到我們要的 self-attetion layer 的 Output, O
整個過程當中,只有 Wq Wk Wv 是未知的,需要透過 training data 去學起來
其他的運算都是人為已知的設定
Self-attention 進階版本:Multi-head Self-attention
思路:做 “相關” 這件事情,我們可以使用不只一個 q ,可以使用多個 q 來做不同的相關性運算,既然 q 有多個,那 k 跟 v 也會有多個相對應
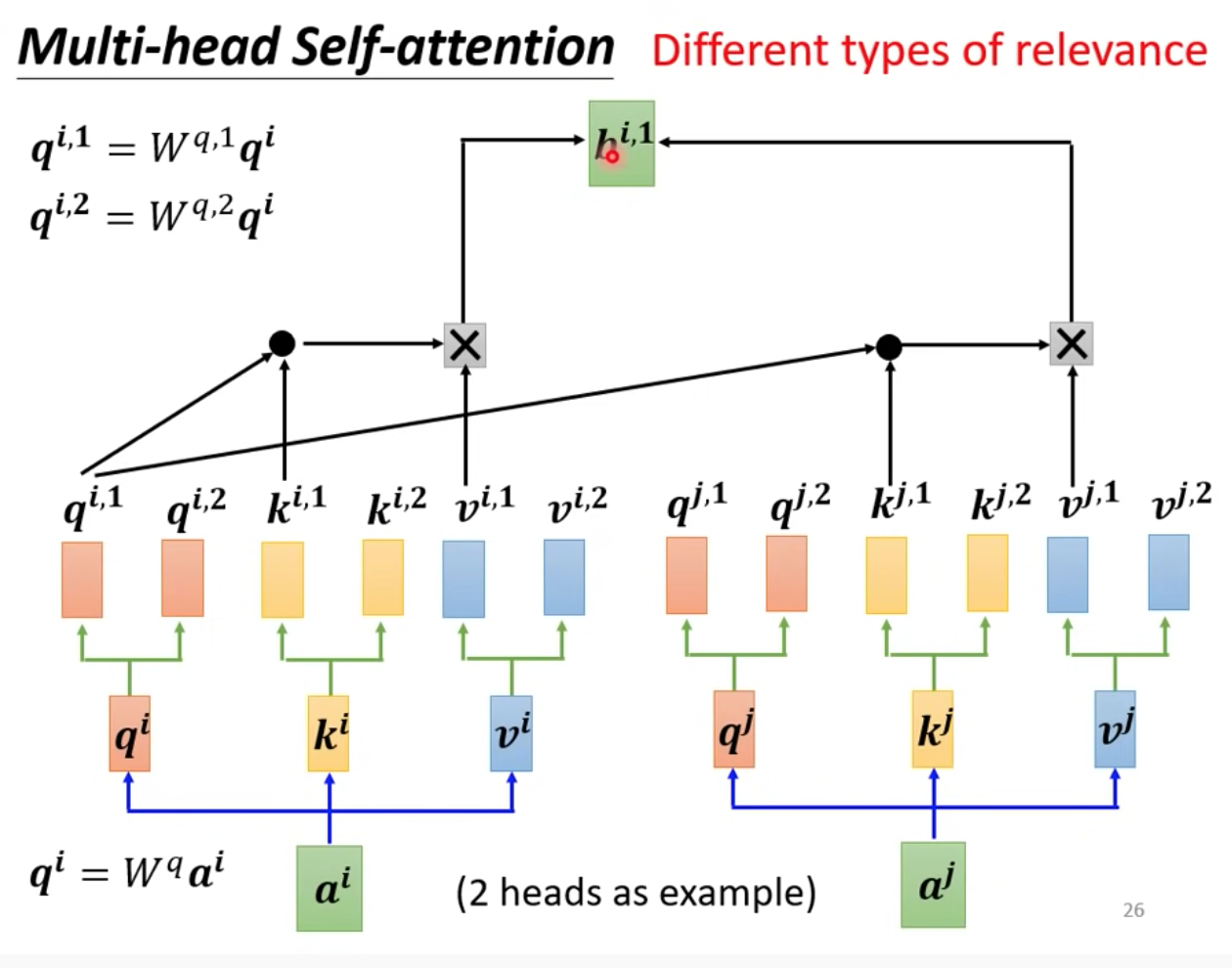
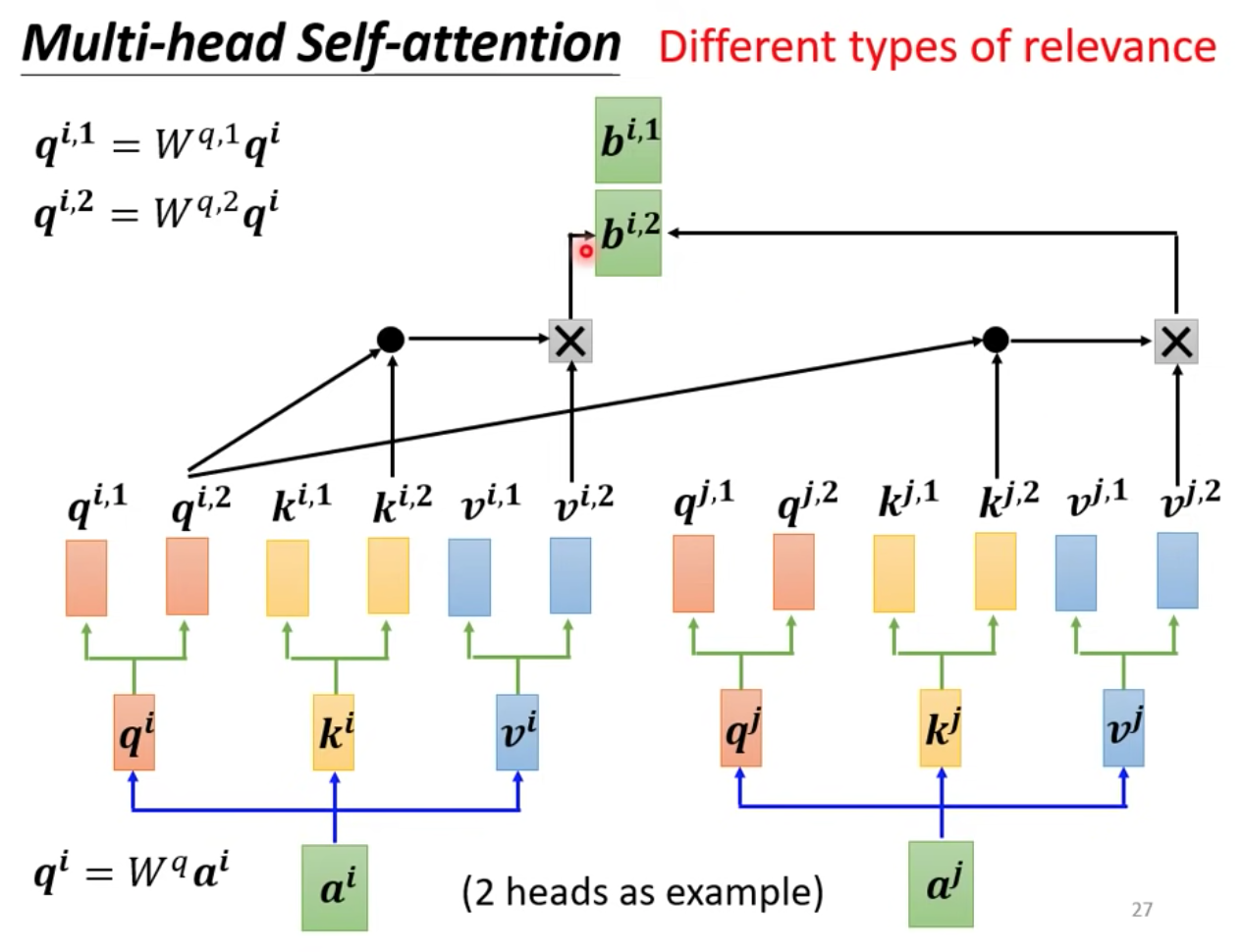
透過不同組的 q,k,v 得到 output bi,1, bi,2 之後,再把這些 output vector 接起來過一個 WO,就可得到 Multi-head Self-attention 的最後 output bi

目前為止,對於 Self-attention 的 Layer 而言,每一個 input 都是獨立的,放在 sequence 當中哪個位置沒有任何差別,因此接下來介紹 Positional Encoding 把位置的資訊塞下去!
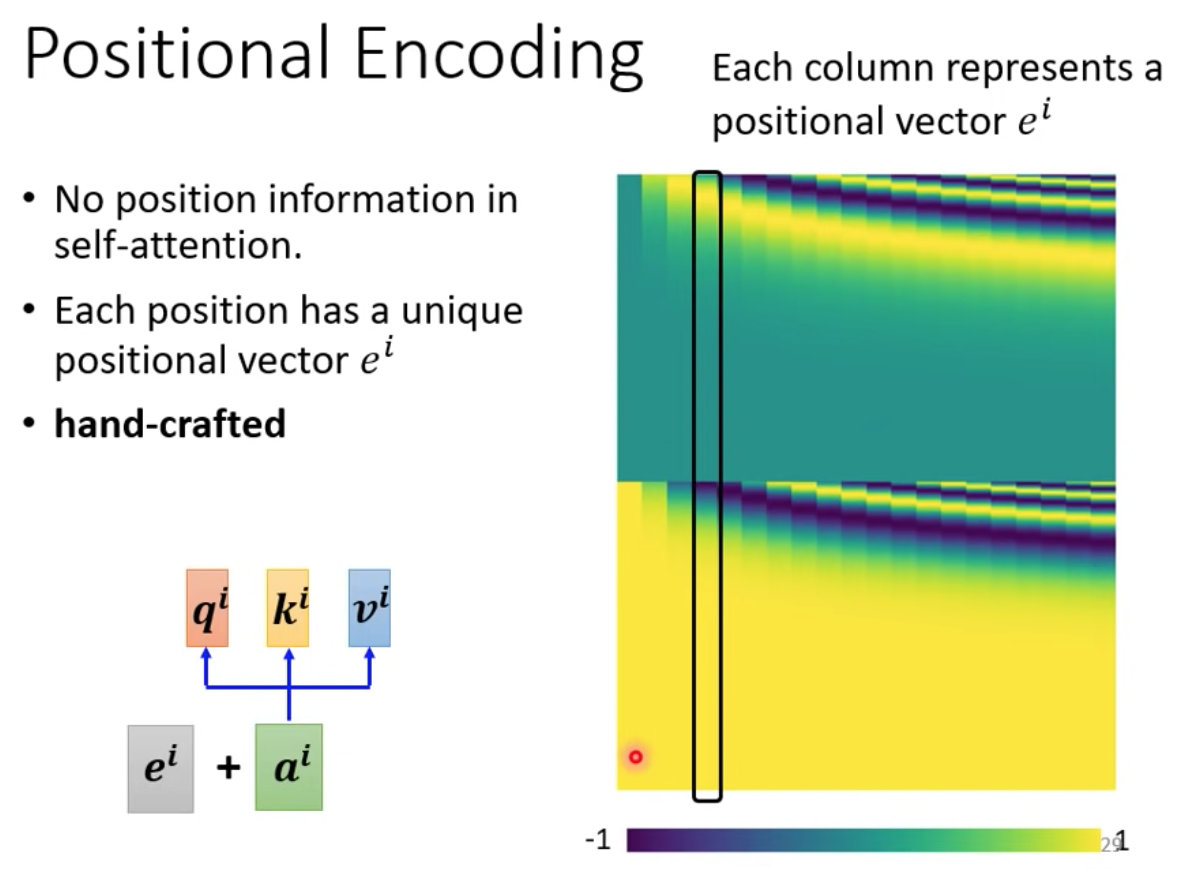
對於每一個不同位置,分別給不同的位置的 encoding ei
再把這些 encoding ei 加到 attention 裡面去
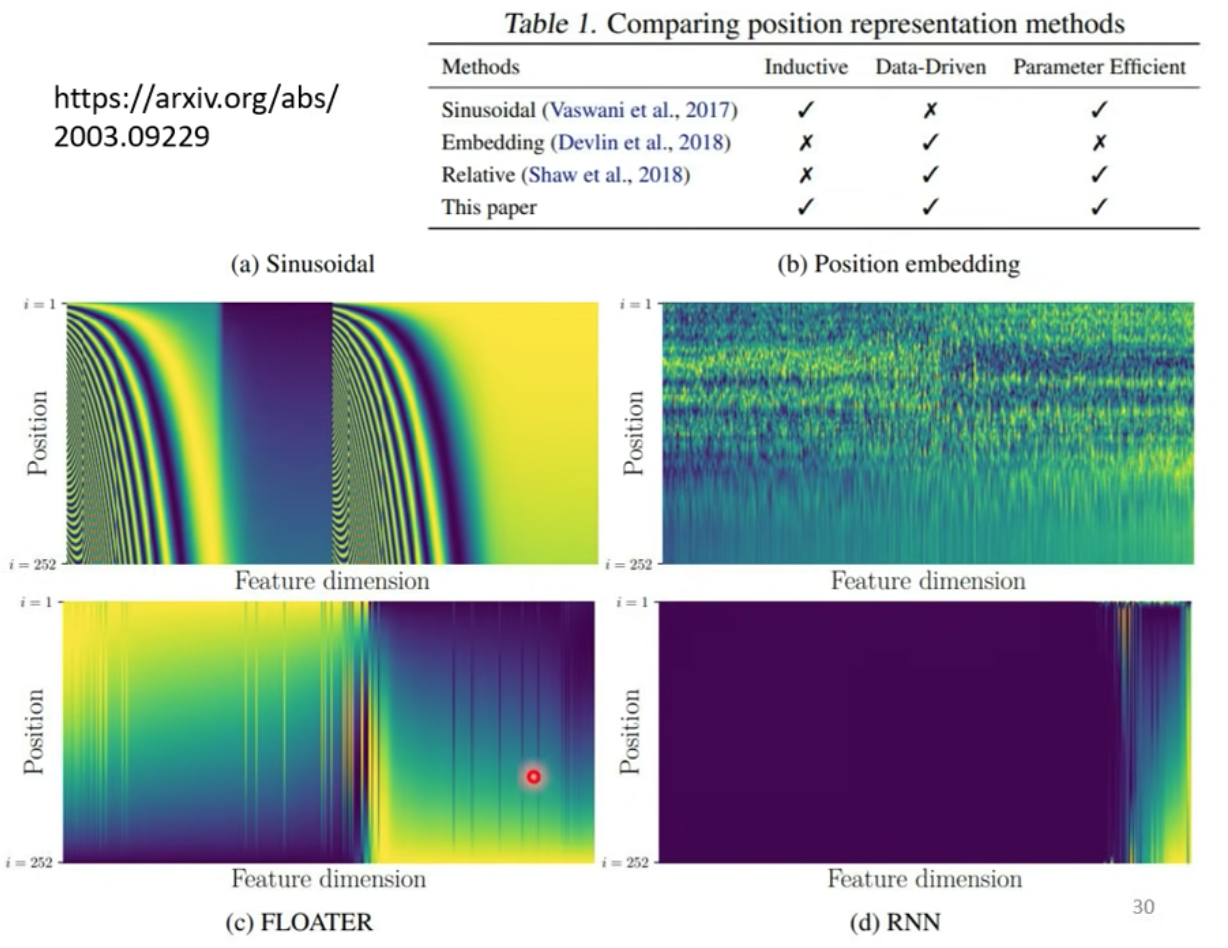
目前大多的 Positional Encoding 是人為設定的,至於有沒有更好的 positional encoding 的方法,尚待研究!
Self-attention 不只可以用在 NLP 應用上,接下來來介紹其他的應用
例如 語音辨識
隨便講一句話,都是上千個向量,Sequence 的數量如果上千的,在做 Attention 的運算時,就會消耗大量的 memory 跟運算資源
因此在做語音的時候有一招叫做 Truncated Self-attention 只看一個小範圍就好,至於小範圍是多少範圍,也是人為設定的

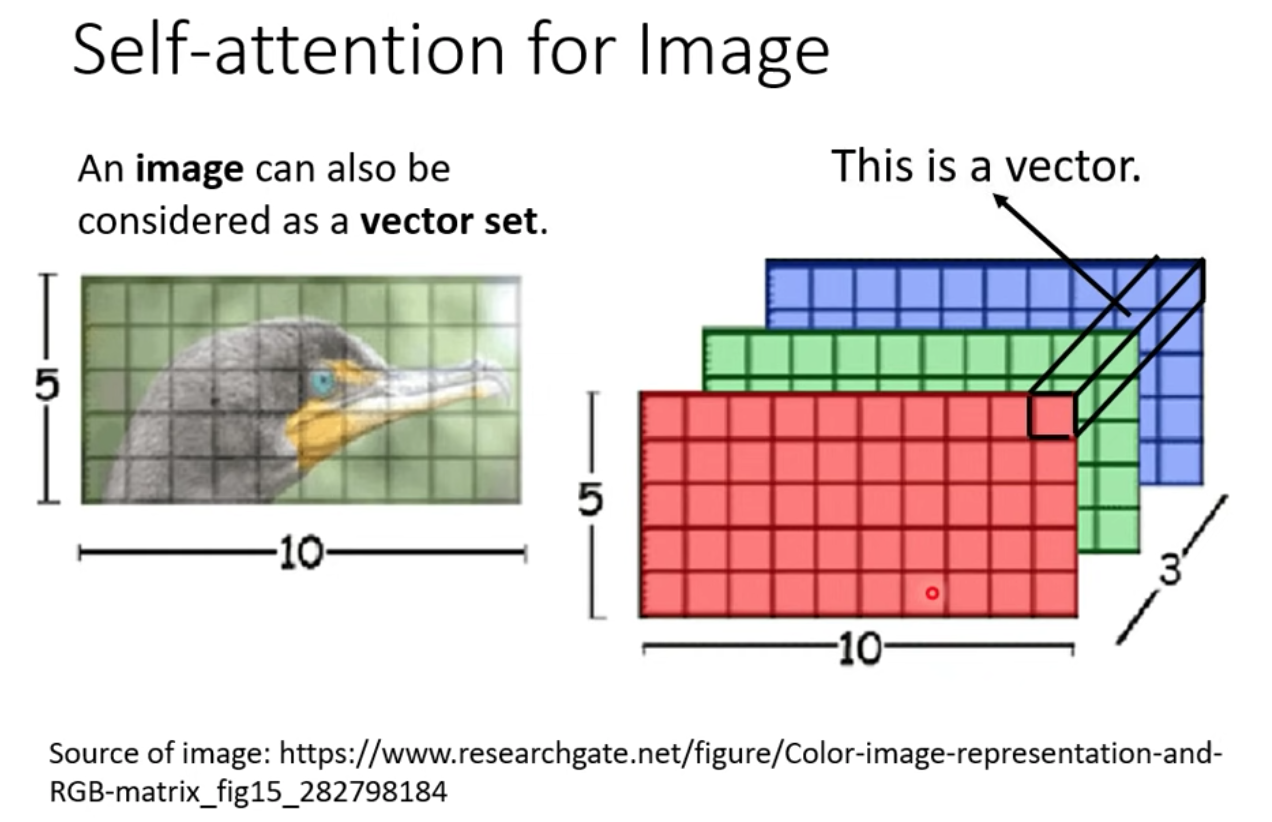
Self-attention 還可以被用在影像上
Self-attention 的輸入是 vector sets,我們要把一張圖片看作是 Vector set 的做法:
把每一個 pixel 看作是一個三維的 vector
使用 self-attention 用在圖片上的例子:
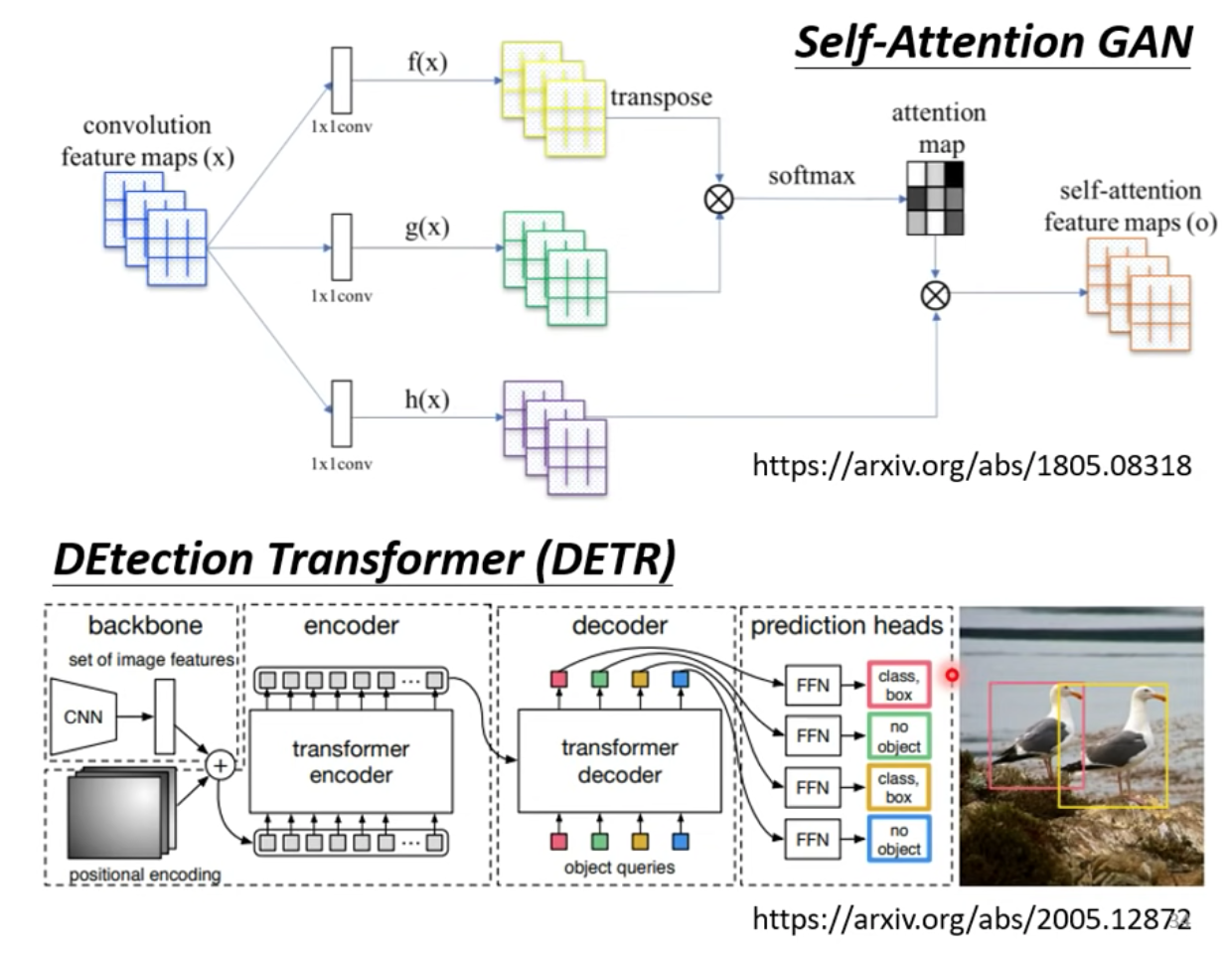
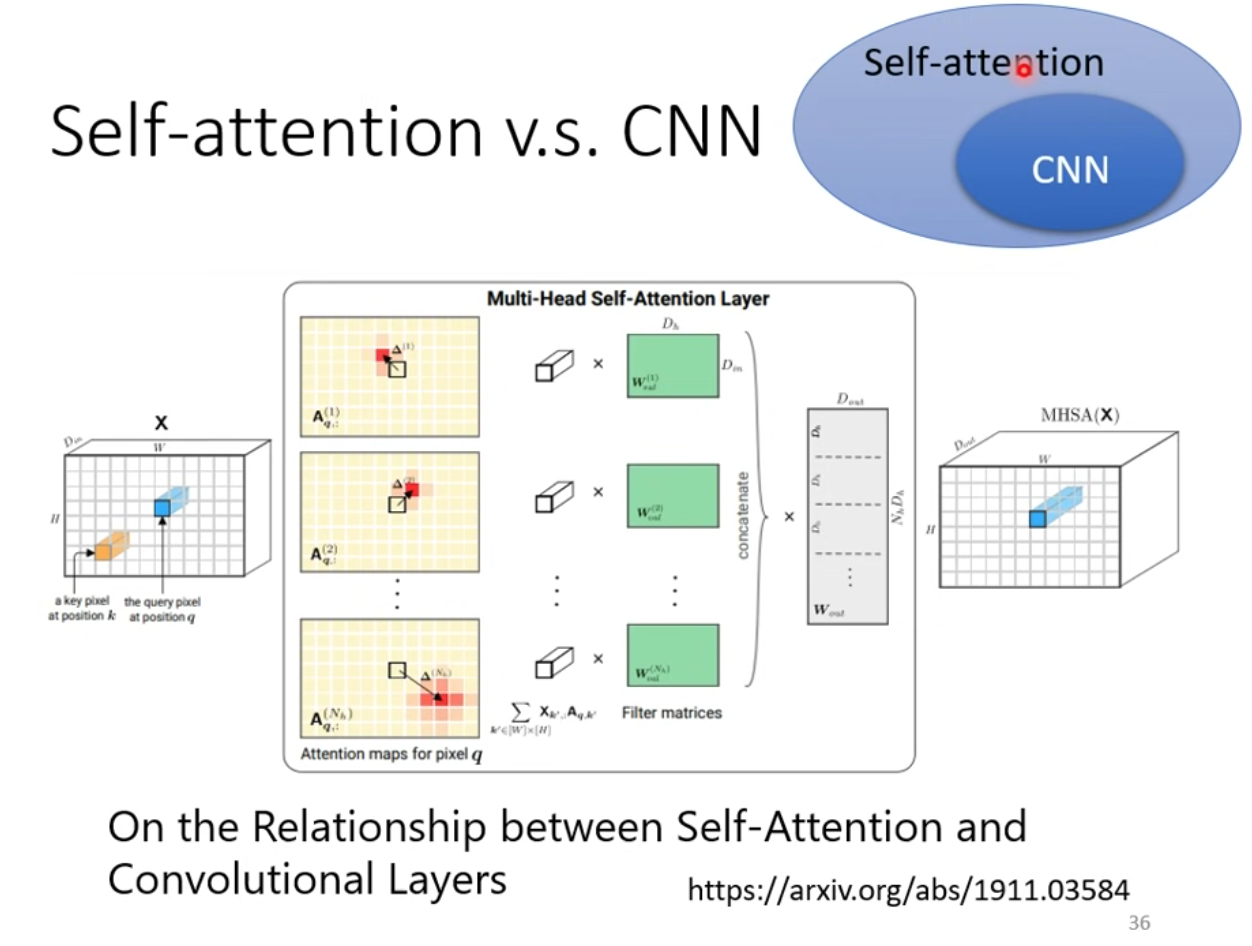
Self-attention 跟 CNN 的關聯性
Self-attention 來處理圖片是,選取一個 pixel 當作 query ,而其他pixel 當作 key 來看該 pixel 跟圖片中其他位置的關係
因此,
CNN 可以看作是一種簡化版本的 Self-attention 因為 CNN 裡面的 receptive field 是局部的,而 self-attention 的 receptive field 是全部的 pixel (整張影像的資訊)
或是可以換句話說 Self-attention 是複雜化版本的 CNN
CNN 裡面每個神經元只考慮 receptive field 裡面的資訊,而 receptive field範圍跟大小事人為決定的
Self-attention 裡面,我們用 attention 去找出相關的 pixel,也就是 receptive field 的範圍是讓機器自動決定的,透過training 過程,在整張圖片當中,機器會自己學出哪些pixel 與 pixel 之間,圖片中哪些範圍是比較重要有關聯的

欲深入研究可以追相關的 paper: https://arxiv.org/pdf/1911.03584.pdf
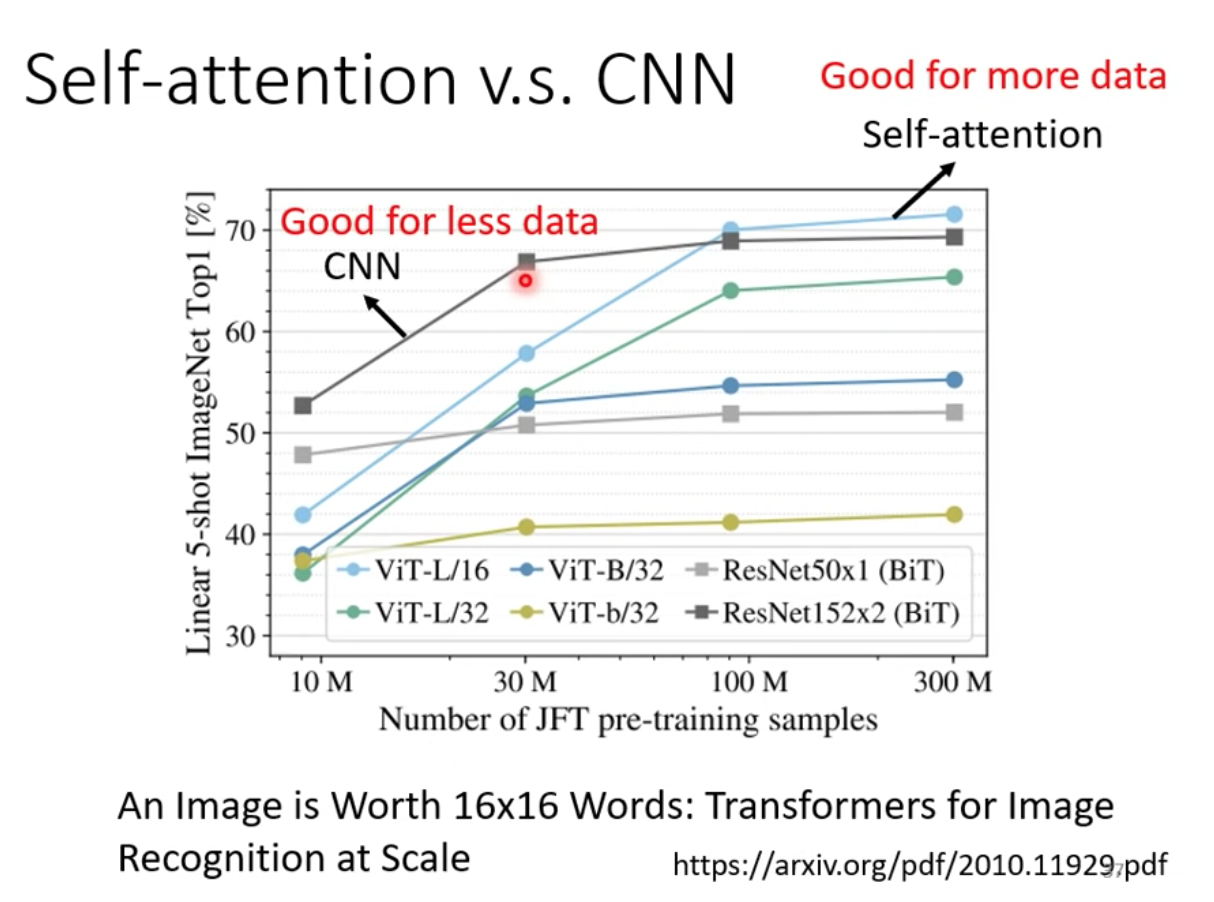
Self-attention 跟 CNN 的比較實驗
在資料比較少時,CNN 訓練起來效果較好,當資料量夠大時,Self-attention 效果超越了 CNN
Self-attention v.s. RNN
簡單快速複習一下 RNN (RNN介紹可以看這篇)
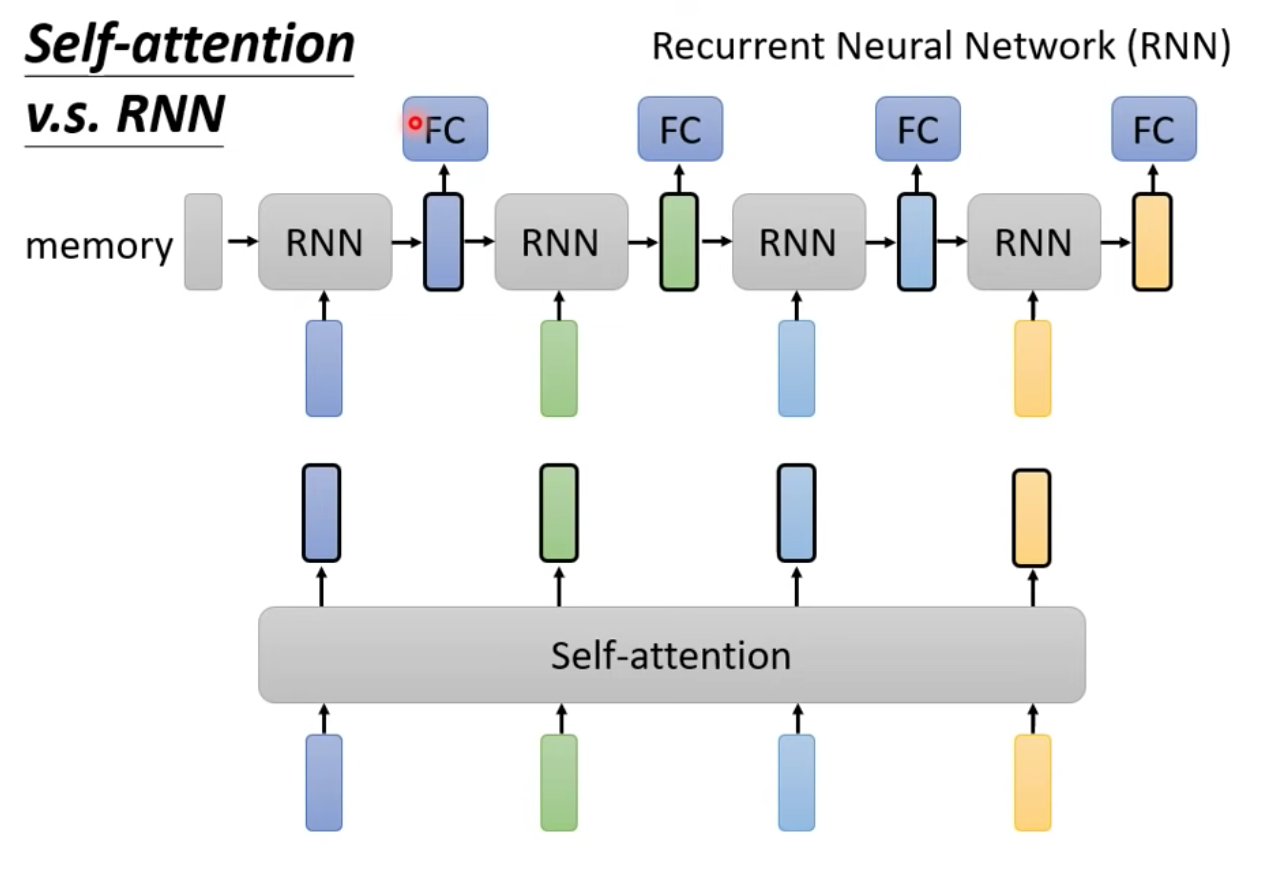
你會發現 RNN 跟 Self-attention 做的事情很像
比較兩者個不同:在單向的 RNN 來說,前面時間點出現的 vector 只考慮了前面時間點的 vector,看不到後面出現的 input
而 self-attention 裡面,每一個 vector 都考慮所有的 input,但其實 RNN 也可以是雙向的,因此使用雙向 RNN 也可以考慮進 sequence 當中的所有資訊
Self-attention v.s. RNN 差異點1
即便是雙向 RNN 跟 Self-attention 最大的差異點在於
如圖:
對 RNN 來說,假設最右邊的紅色的黃色 Vector 要考慮最左邊的紅色框藍色 input vector 必須一直存在 memory 裡面不會被忘掉,才能在最後一個時間點影響到最後一個 vector
而在 self-attention 的架構來說,沒有這個問題,即便在sequence當中離得很遠的兩個 vector,他們還是會被完整地兩兩輕易地抽取出資訊 (attention score)

Self-attention v.s. RNN 差異點2
RNN 無法平行化,因為 RNN 的下一個時間點所需要 input,會需要等前一個時間點的結果出來才能運算下去
Self-attention 當中的運算則是相互獨立的,可以輕鬆地平行化處理所有運算,得到輸出
因此在運算速度上,self-attention 會比 RNN 更有效率
近期很多的應用往往都把 RNN 的架構改成 self-attention 架構
有興趣可以追這篇論文 https://arxiv.org/pdf/2006.16236.pdf






留言
張貼留言