[ML筆記] Tips for Training DNN
ML Lecture 9: Tips for Training DNN
本篇為台大電機系李宏毅老師 Machine Learning (2016) 課程筆記
上課影片:
https://www.youtube.com/watch?v=xki61j7z-30
課程網 (投影片出處):
http://speech.ee.ntu.edu.tw/~tlkagk/courses_ML16.html
上課影片:
https://www.youtube.com/watch?v=xki61j7z-30
課程網 (投影片出處):
http://speech.ee.ntu.edu.tw/~tlkagk/courses_ML16.html
做 Deep Learning 的流程
step 1 定義 set of funcion
step 2 定義 goodness of function
step 3 挑選 best function
→ training
先檢查 training set 的 performance
→ 結果不錯的話
在檢查 testing set 的結果
→ 結果不好 (overfitting)
→ 結果不錯 bingo !
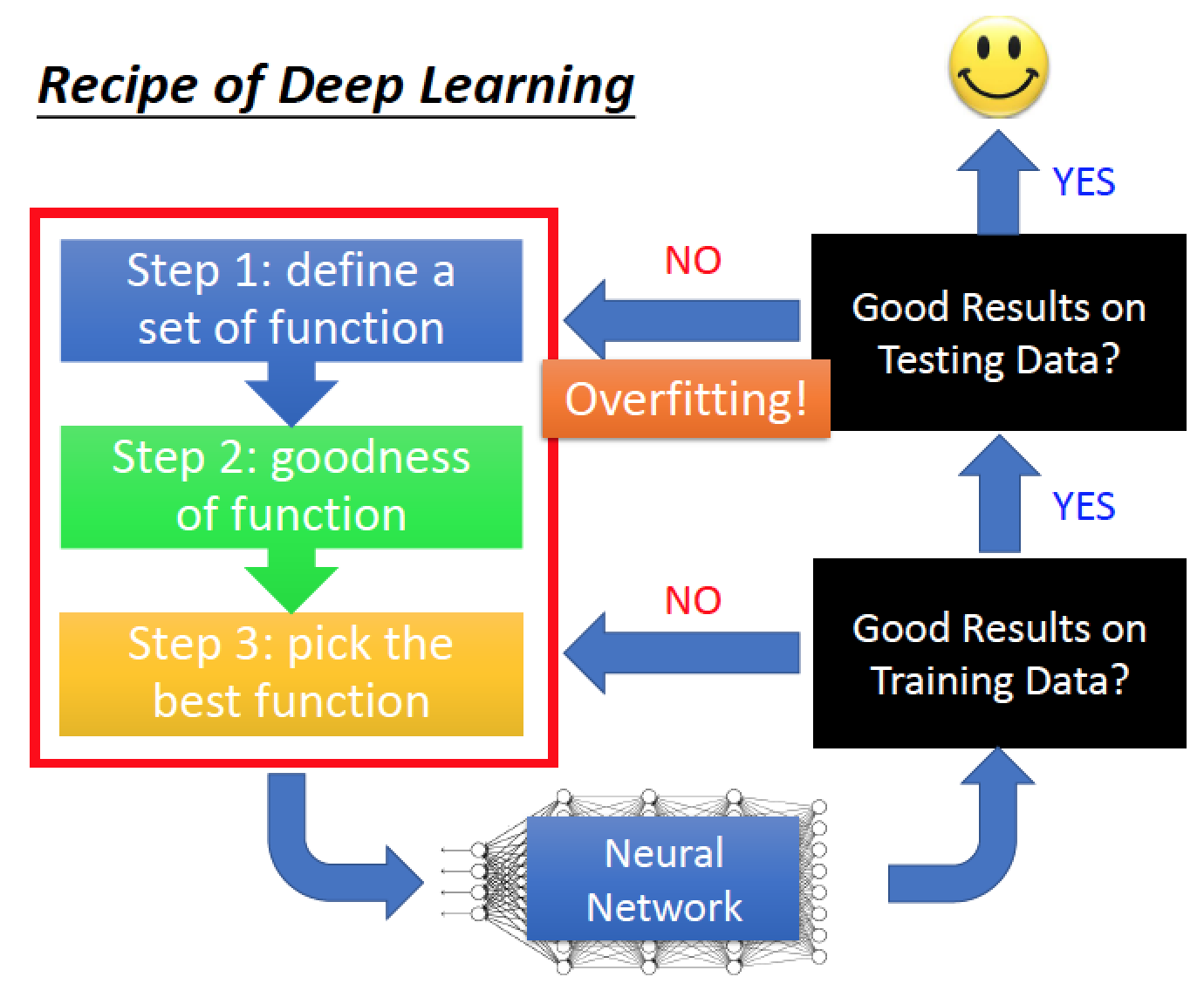
- trainning 結果不好
- testing 結果不好
這兩個問題要分開討論

讀到一個方法時,要先知道他在解哪個症狀
training 結果不好 或是 testing 結果不好!
|  |
針對 trainning 結果不好 的討論
可能是架構設計上的問題
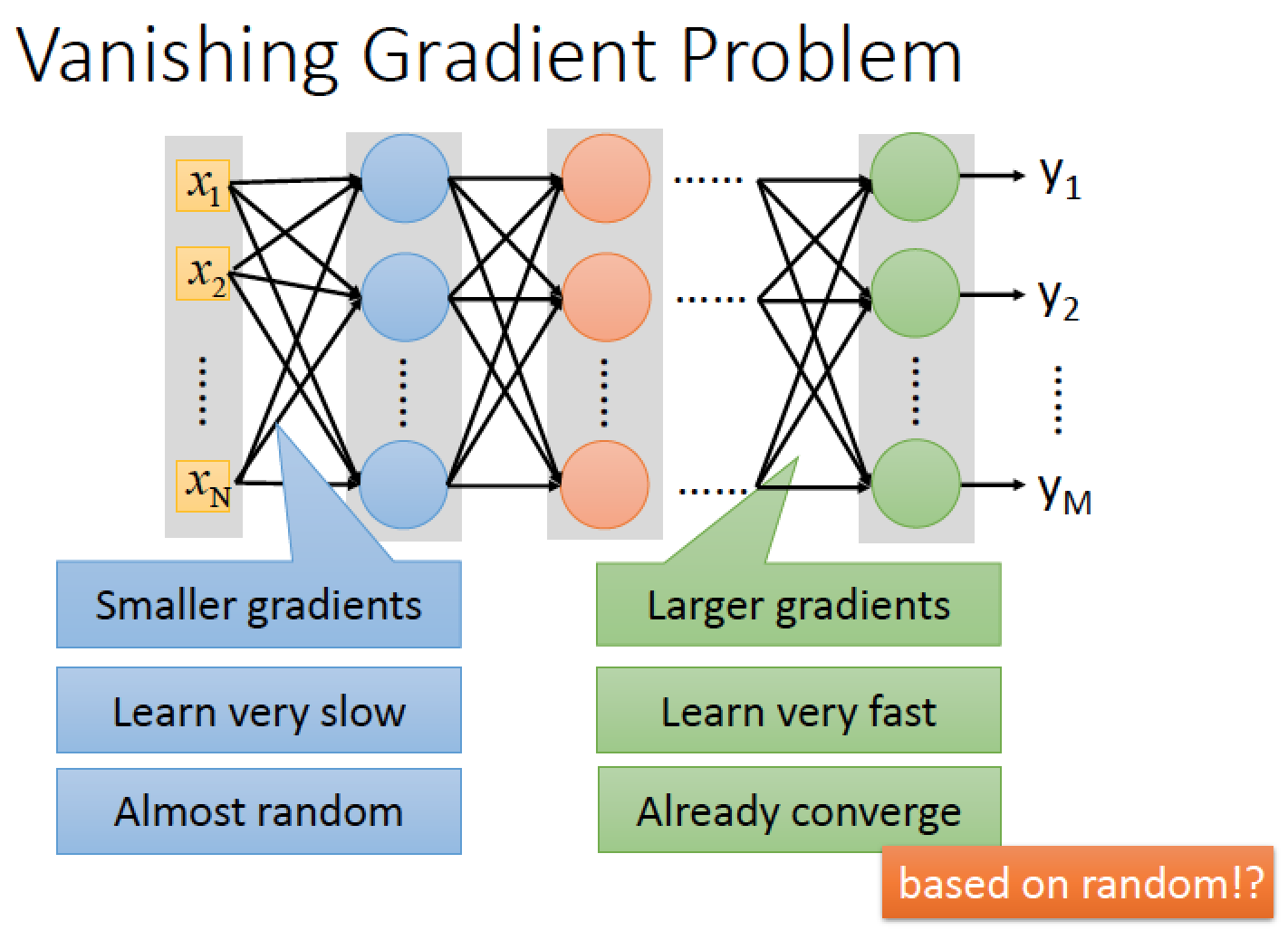
Vanishing Gradient Problem:
input 還是 random 的時候 output 的地方已經收斂了,得到的結果是很差的
為什麼會有這樣的現象發生呢?
因為使用 sigmoid function 有缺點:他會把資料壓縮在 0 ~ 1 之間
就算 input 端的兩個數據差異很大,經過 sigmoid function 後,他們的差距大幅被降低,經過多層後,到達 output 端,他們的差距變得超級小
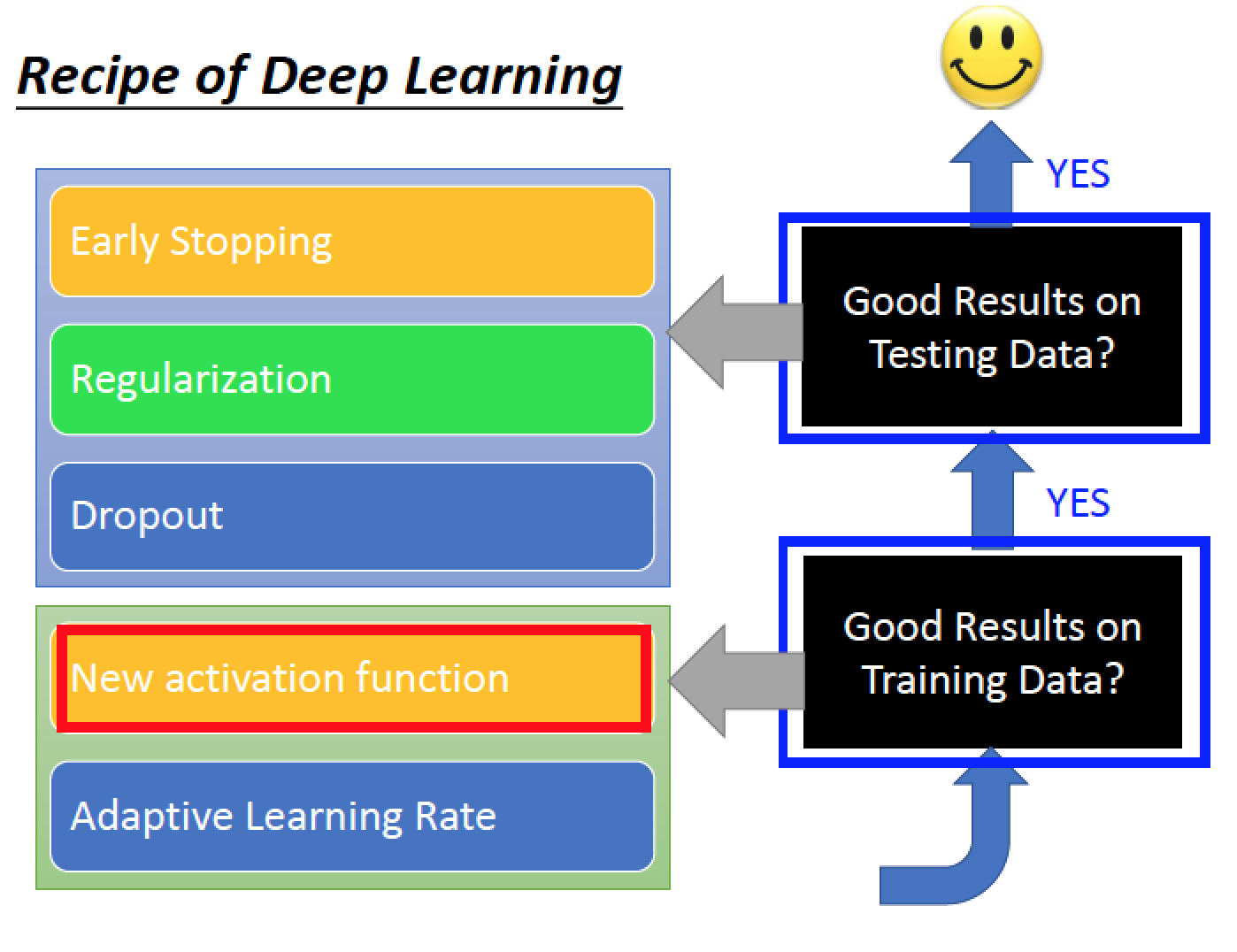
解決方案:改用新的activation function ,例如使用 ReLU
 |  |
ReLU : Rectified(糾正) Linear Unit

簡介:input <= 0 的時候,就是 0 。 input > 0 的時候 input 就是 output !
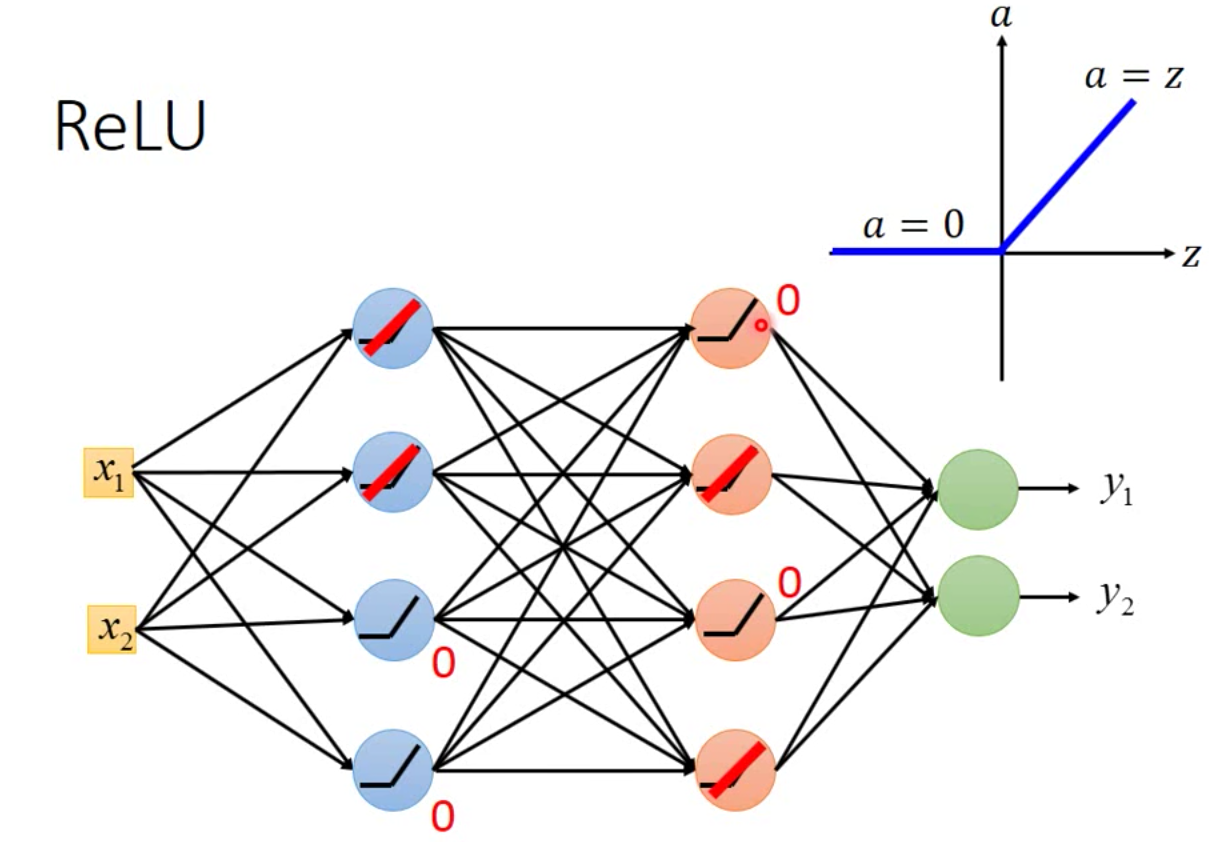
問題:
當我們把 output 是 0 的部分拿掉,整個 network 看起來是一個瘦長的 linear function
雖然 ReLU 是個 Linear function,但是整個 Network 還是 non-linear 的:
當input端沒什麼大的改變時,每一個 neutron 的 operation 是一樣的時候,他是 linear 的,但是input 端出現比較大的改變,neutron 之間的 operation region出現很大的差異時,整體看起來就是 non-linear 的
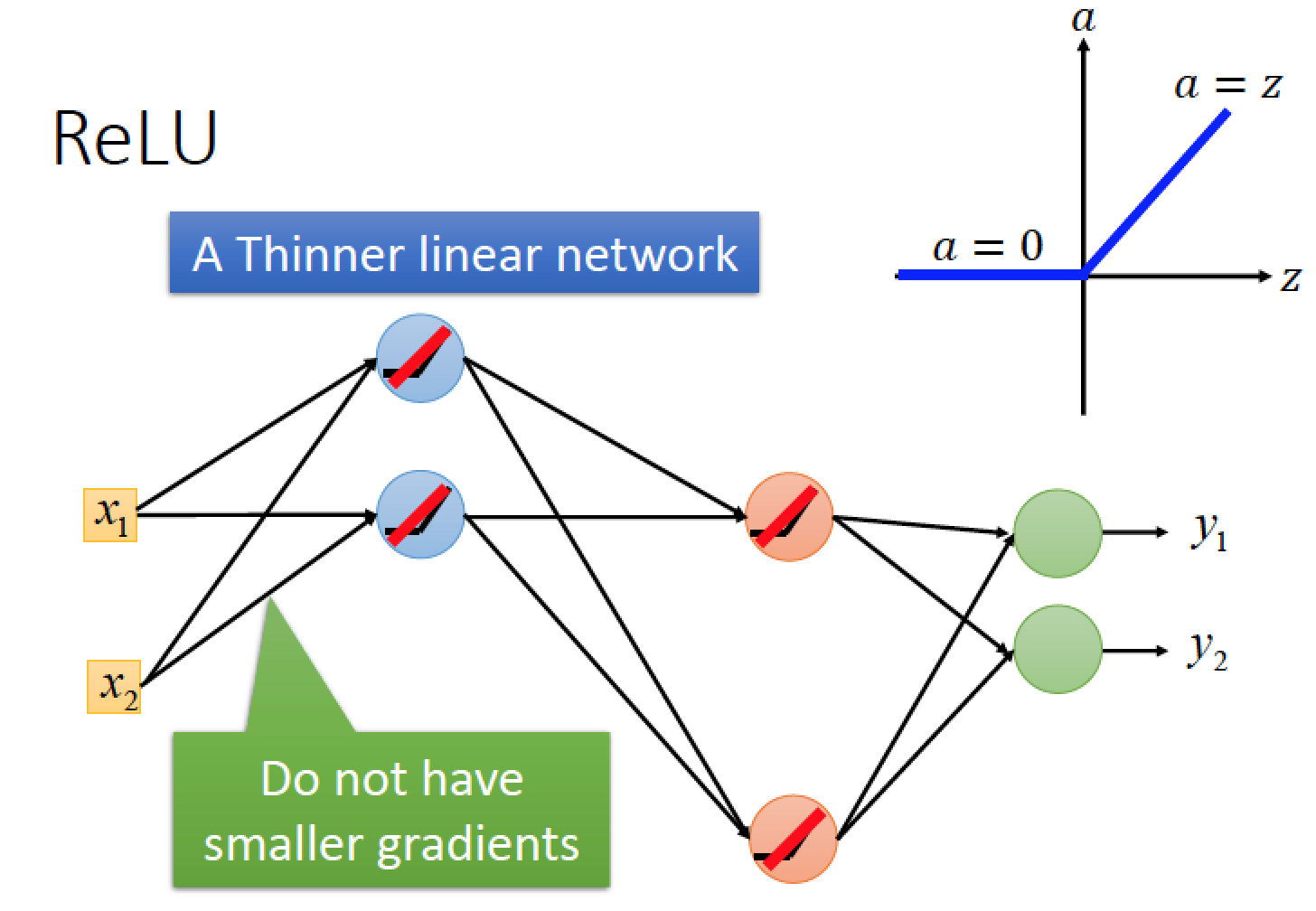
問題2:
ReLU不可微分 怎麼辦?
簡單觀察,當 ReLU 結果 = 0 微分就是 0
當 ReLU 結果 > 0 微分就是 1
ReLU 的變形
想法:
設計成 input < 0 的時候,output 還是要有微小的值
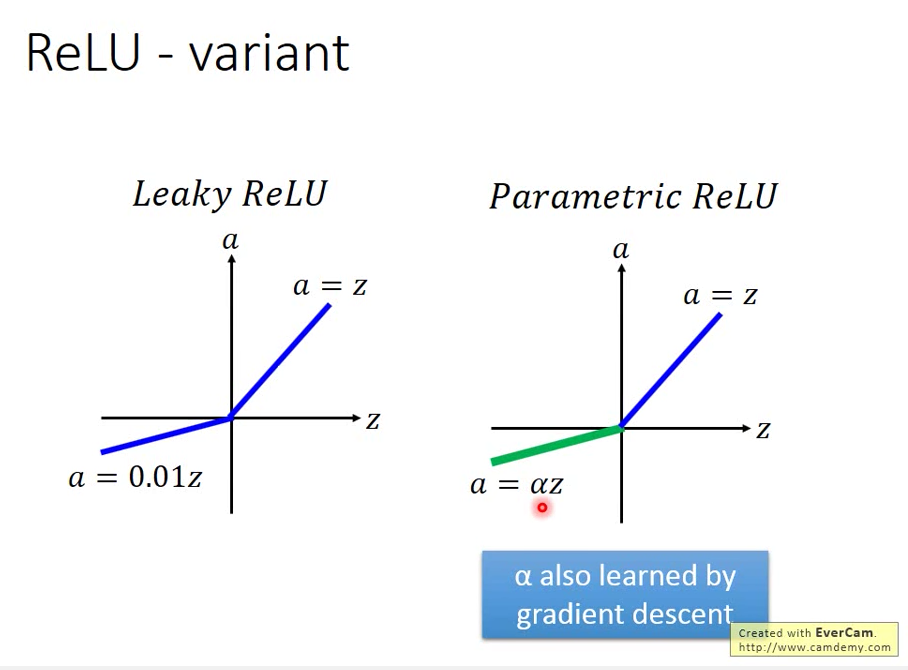
上圖右邊的倍數 可以透過data學出來
更進階的變形:Maxout network

想法:
我們改用新的策略自動 “學” 出 activation function
例如 input 端 x1,x2分別乘上不同 weight 相加後產生若干組數據 group 起來,從每一組當中挑選最大的傳到下一層,依此類推...。在此,哪些 value 要被 group 起來是事先決定的!
當然,一組可以不止 2 個 element 依NN設計者的設計來訂定
Maxout Network 是有辦法做到像 ReLU 做的事情,可以模仿 ReLU activation function
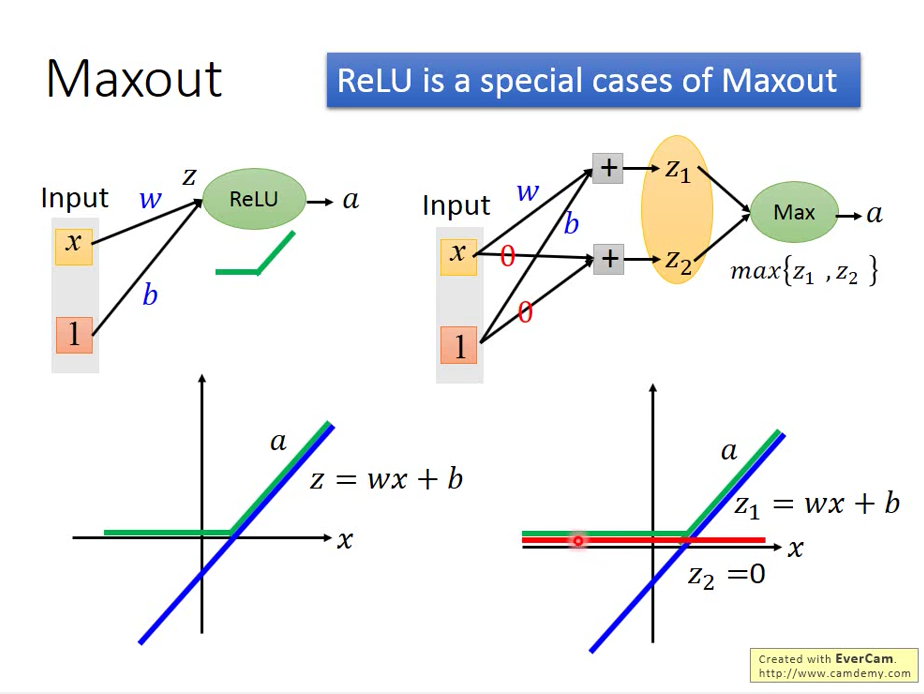
例如上圖右,我們設計z1,z2
z1前面的 weight 跟 bias 分別為 w, b
z2前面的 weight 跟 bias 都為 0,所以 z2=0
則跟去取 Max 的條件下,當z1>z2就取 z1,當z1>z2就為 0
達到 ReLU 的效果
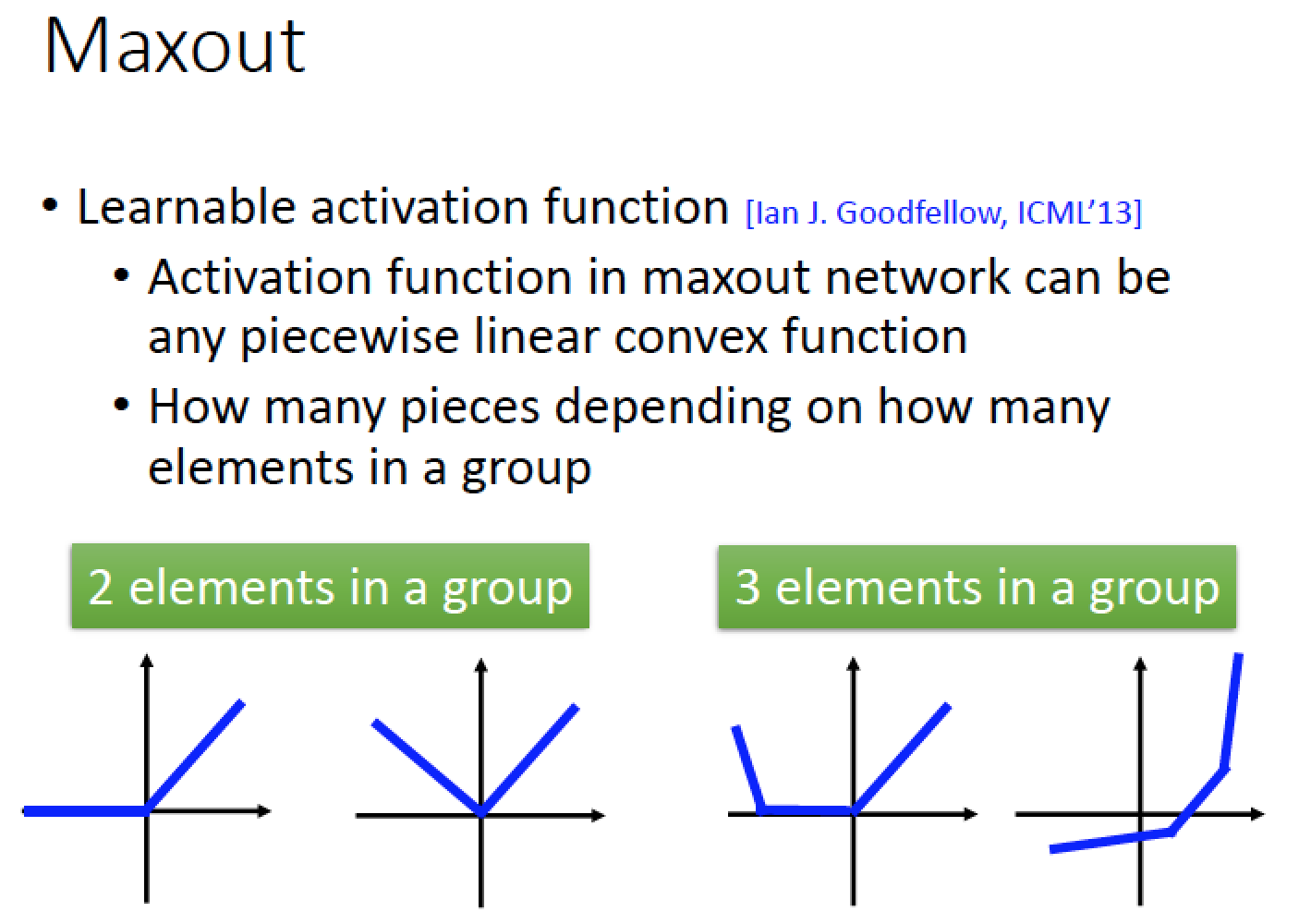
Maxout Network 也可以做出更多不同的 activation function

例如
z1前面的 weight 跟 bias 分別為 w, b
z2前面的 weight 跟 bias 不是 0,設計成 w ', b '
這個 activation function 可以根據不同的 w, b , w ', b ' 針對每一個 neutron 跟 data 去 Learn 出合適組合!
所以這個 activation function 是可以學習出來的!
接下來要面對的問題就是,這個東西怎麼 Train ?

因為是 maxout 都是選比較大的值,上圖紅色匡起來部分,所以沒被選到的先不看,得到下圖,呈現一個細長的 linear network
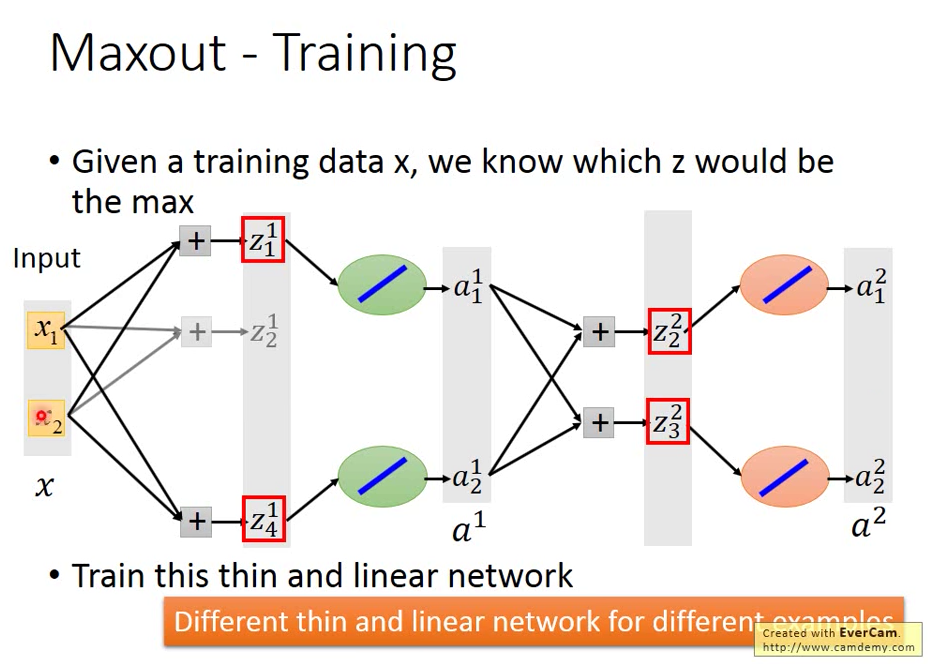
則我們 tain 到一個細長的 linear network 上的參數
問題:那沒被 train 到的那些怎麼辦呢?
這不是個問題,因為當我們 input 不同的 data 丟進去,經過 weight 跟 bias 運算得到 max 值,maxout 選出來組合的也會不同,network structure 不斷地變換,所以每一次都可能 train 到不同的組合
Adaptive Learning Rate
→ Adagrad

每一個 parameter 都有不同的 learning rate
把一個固定的 learning rate 除以[ 過去所有 gradiant 值的平方和開根號 ]
就可以得到新的 parameter
考慮兩個參數 w1 w2
w1 平常 gradiant 比較小,代表他比較平坦,所以給他比較大的 Learning rate
w2 平常 gradiant 比較大,代表他比較陡峭,所以給他比較小的 Learning rate
我們之前在做 linear regression 時看到的 optimazation 的 function (loss function) 是 convex 的形狀,
但是實際上在做 deep learning 時,Loss function 可以是任何形狀
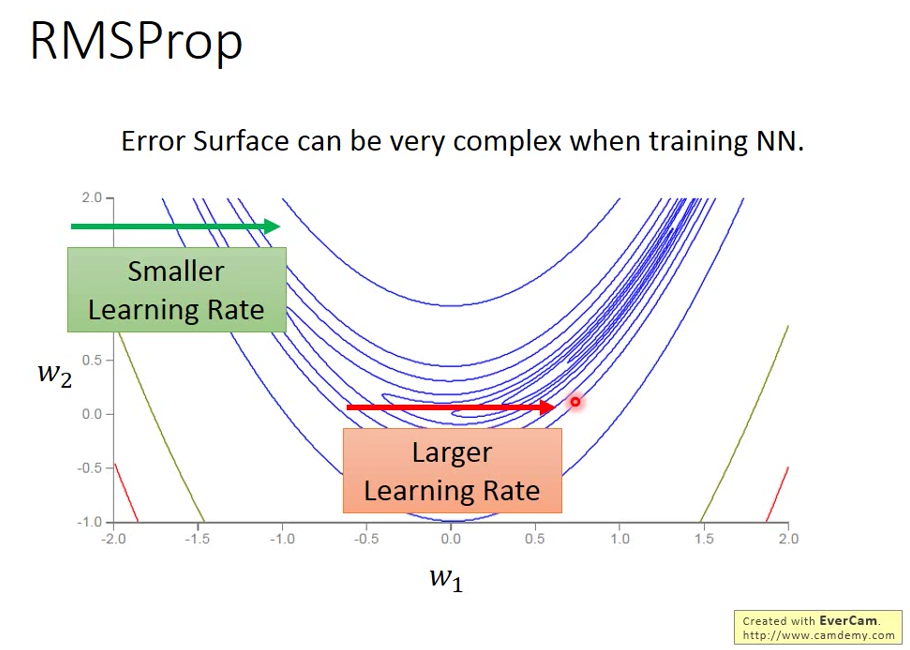
就算在同一個方向上,我們的 learning rate 也必須要快速的變動
可能在一個區域很平緩,需要比較小的 Learning rate,但是到另一個區域就變得很陡峭,需要比較大的 Learning rate。
此時我們需要一個比 adagrad 更有彈性的方法 → RMSProp
RMSProp 是這樣做的
第一個時間點時,得到 g0
第二個時間點時,要把第一個時間點得到的 sigma () 做平方比例調配開根號
的值可以自己設定

跟 adagrad 最大的不同就在於可以手動調整
如果 條小一點 例如 0.1 代表我們比較相信新的 gradiant 值,比較少參考過去的 gradiant
另一個問題:
在做 Learing 時,有可能會卡在 local minimum 或是 saddle point
→ 可以用 Momentum 來解!
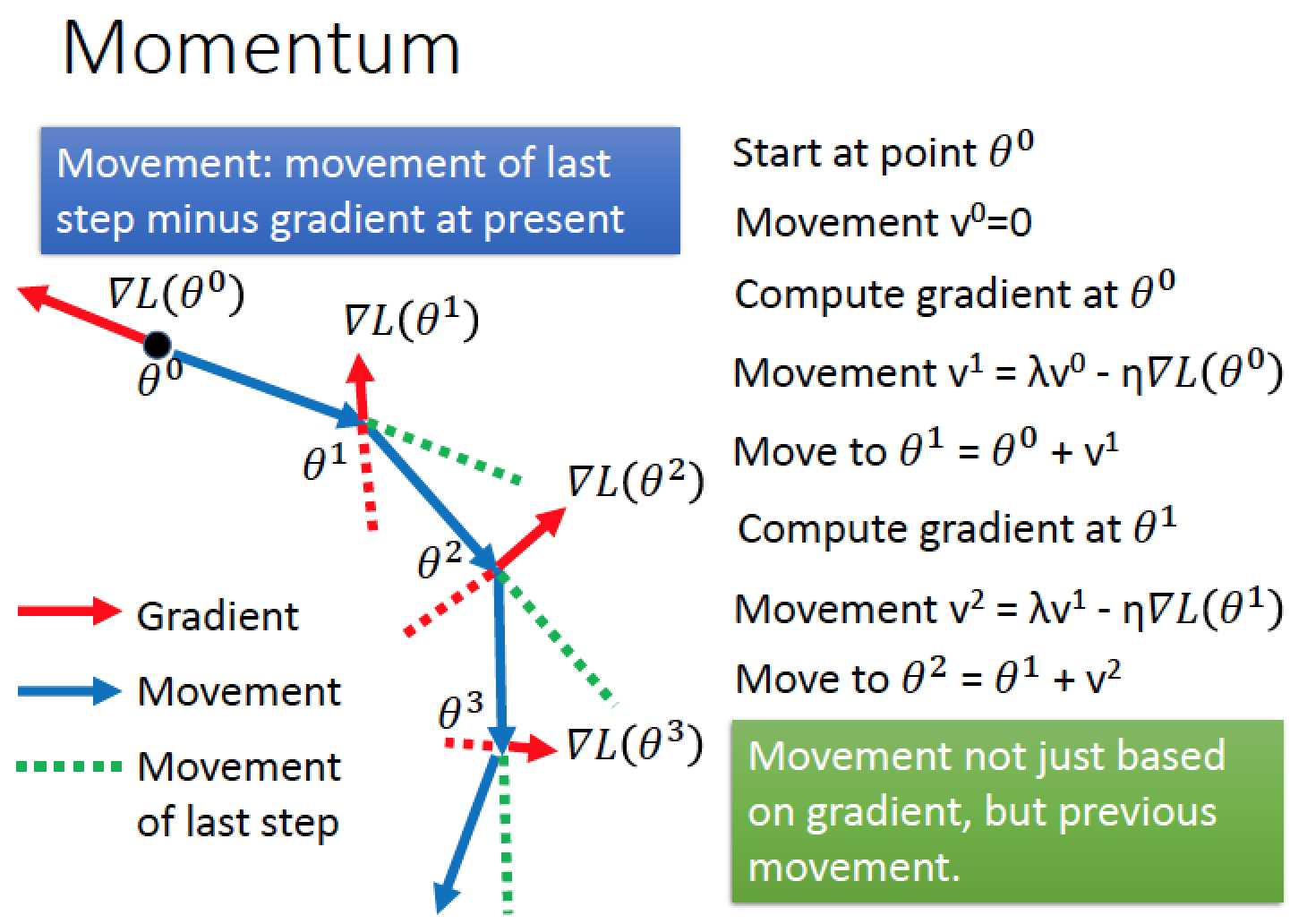
Momentum
概念:想像有一顆球從左上角上坡上滾下來
因為有慣性,就算走到 local minimum 的地方,也會衝上坡,然後可以到達下一個下坡!
所以我們要做的事情就是把 momentum 的特性塞到 gradient descent 裡面!

想法:讓原來走的方向對於參數有一定的影響力!
每次移動的方向為前一個時間點的 movement V0 + gradinet 的結果!

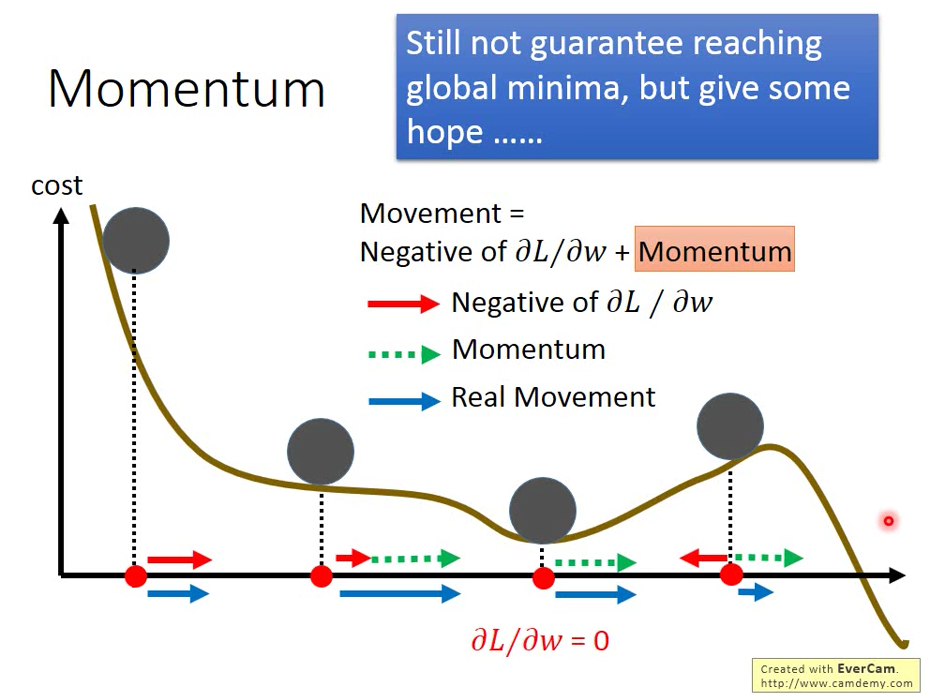
在 local minimum 得地方,gradiant = 0 但是 momentum 是往右走,所以最後總和是往右走
所以加上 momentum 的機制有機會讓我們跳出 local minimum 找到 global minimum
Adam 就是 RMSProp + Momentum

剛才講的都是 traning data 上結果不好怎麼辦
接著我們來探討在 training data 夠好,但是在 testing data 上結果不好的話該怎麼辦


常常在 train 時,training set loss可以調得很低,但是低到某個時間點時,testing set 的 loss 就開始又上升了
Early Stopping 的機智就是,找出 testing set loss function的最低點 停在那邊!
我們這裡在討論的所謂 testing set 並不是實際的 testing set ,因為我們不會知道真正的 testing set 的變化,所以實作上這裡指的 testing set 是我們自己從切出來的 validation set
KEY: 從 training set 當中先切出一部分當成 validation set 來做 Early Stopping
另一個做法是 Regularization
重新定義了 loss function

加上一項 regularization,不考慮 bias,因為我們加上這個是為了讓我們的 function 更平滑
L2 的意思是 我們加上的 Regularization 項裡面,是取過去所有的 weight 平方和
所以也會有 L1,指的就是單純的取絕對值後相加

把上述的 loss function 微分得到 update 的式子
整理後發現,前面這一項 接近零,1 - 接近零的數值就變成接近1 的值;譬如說 0.99
每次在 update 參數就先乘個 0.99 左右的倍數,所以越到後面,我們的 weight 越來越接近 0
後面那一項是關鍵
如果我們使用 L1 Regularization 會得到這麼式子呢
取絕對值 → 大於零的微分 = 1
小於零的 → 微分結果就是 = -1
 sgn = sin function
sgn = sin function
如果 W 是正的,後面藍色那一項就是 +1
如果 W 是負的,後面藍色那一項就是 -1
不管 W 多大多小,對於 L1 來說,減掉/增加的值都是固定的!
使用 L1 training 得到的結果會比較 sparse
Comment & Discussion:
Regularization 做的事情,要達到的目的,其實就是讓我們的參數不要離 0 太遠
這件事情也可以透過 減少參數更新 (update) 的次數來達到
所以 Regularization 的重要性沒有很高

人腦面的神經元,發育時會長出很多連結,但是隨著歲數的增長,使用與學習的狀況,沒有用到的連結就會漸漸 decay 掉, regularization 就是在模擬這樣的情況!
Dropout

Training 時每次 update 參數之前,都會 sample 一次
所以沒有取到的神經元不看,得到一個比較瘦長的 network,再去 train 比較細長的 network
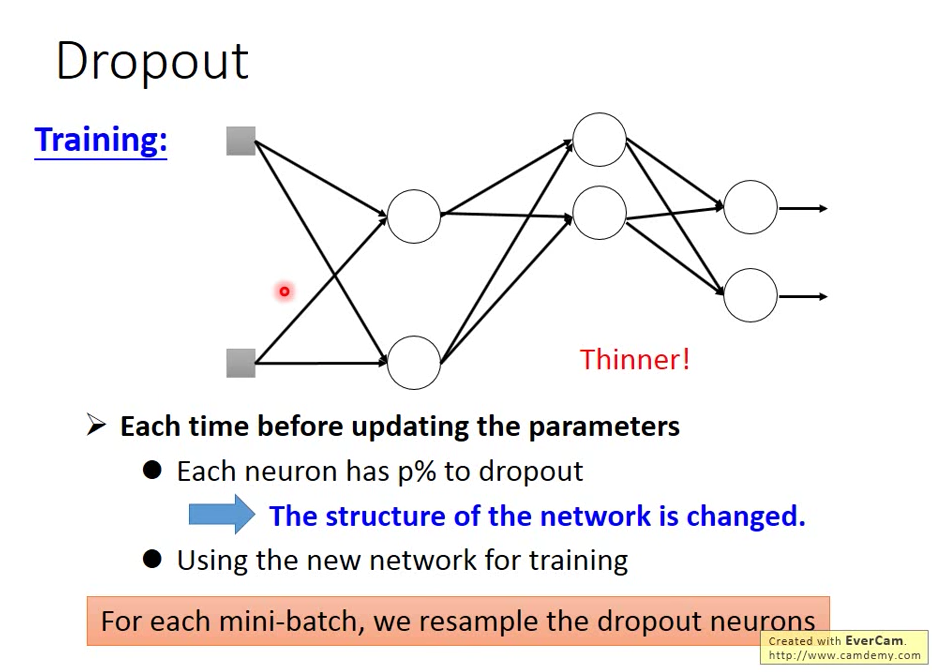
每一次 update 參數之前都要重新 sample 一次
所以每一次丟掉的神經元都不一樣,得到的神經網路的路線都不一樣!
每個神經元有 p% 的機率會被丟掉!
加上 dropout 的時候,training 上的 performance 會變差,因為neutron沒有全部用到,但是用 dropout 的目的就是想提升 testing 的 performance
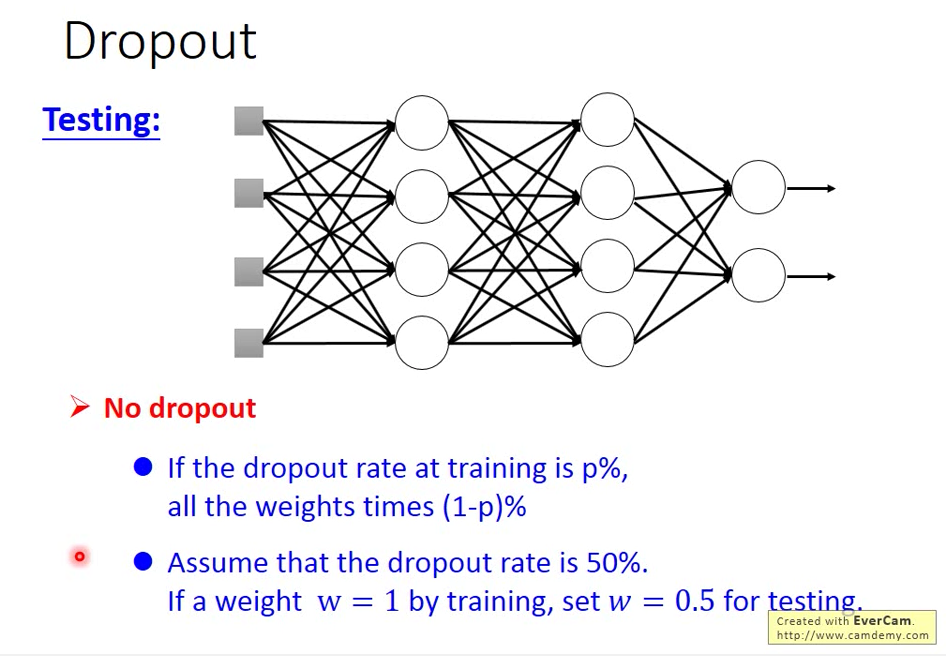
Testing 要注意兩件事:
1. Testing 時不做 Dropout,所有 Neutron 都要使用!
2. 假設 Training Dropout rate 是 p% ,在 testing 時的所有 weight 乘以 (1-p)%
→ 假設 Dropout rate 是 50%, 在 training 的時候 learn 出來的 weight = 1,Testing 的時候,使用的 weight 是 50%
[NOTE]
在 Training 的時候做 Dropout 來訓練,但是在 Testing 的時候不做 dropout 用全部的神經元一起去 testing
Dropout 為什麼有用?
直觀的理解:
 | 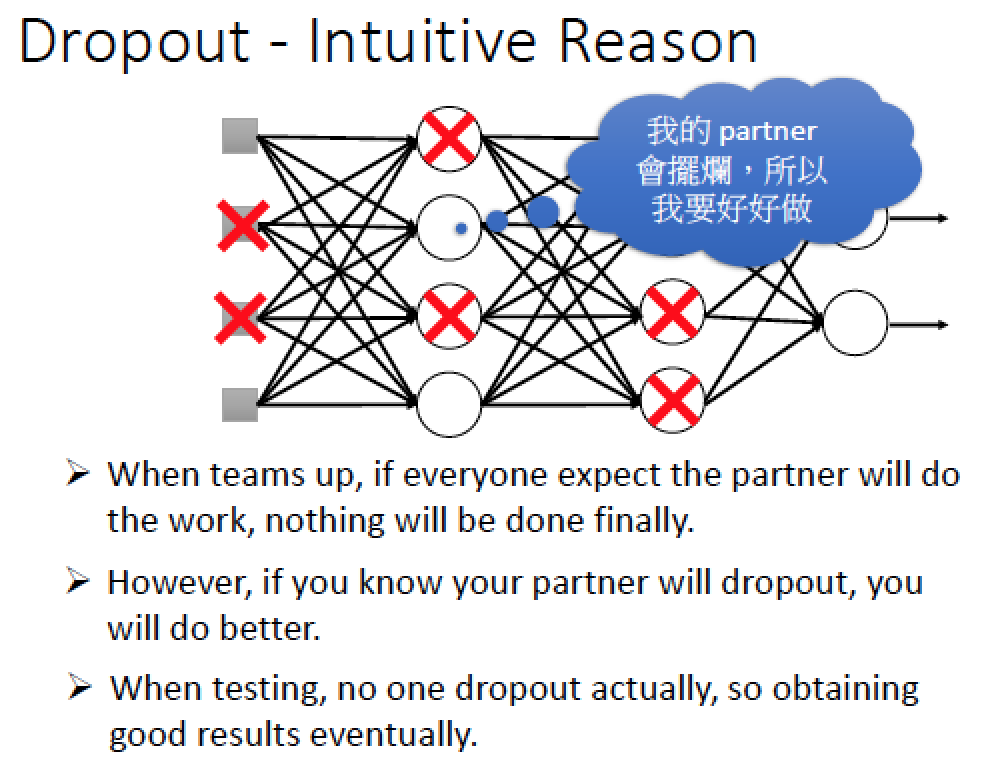 |
訓練時在腳上綁些重物練習,在實際比賽戰鬥時,拿下重物,就會變強
每一個 Neuron 就想像成一個學生,再一起做 Final Project 時,我們會 carry 擺爛的人
但是考試時,大家都會卯起來做,就會變得很強 @@|||
解釋:為什麼Dropout 時 training 跟 testing 用的 weight 不一樣
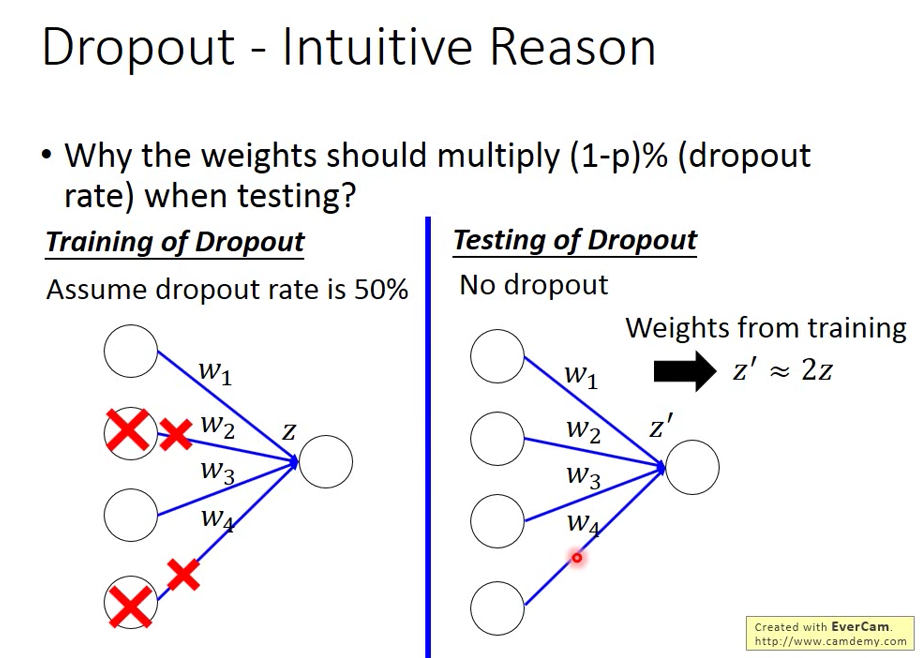 | 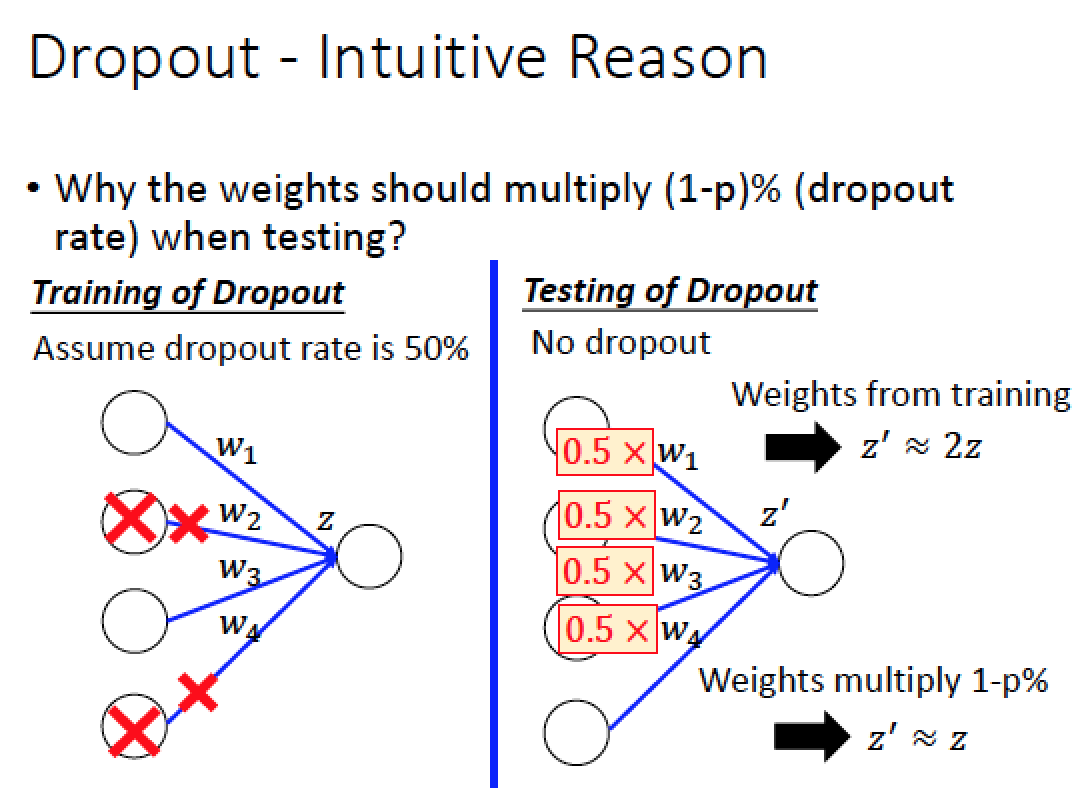 |
如果 dropout rate 50%
Training 的時候 期望會丟掉一半的 Neutron
Testing 的時候,他是沒有 dropout ,所以會全用
所以才要把所有在 Training 使用的 weight 全部乘以 0.5 這樣 Training 跟 testing 才會 match
Dropout 是一個終極的 ensemble 的方式

我們從 Training Set 裡面拿出很多 subset 出來 train 很多 model,分別得到很多 Network 個結果,雖說每一個 model variance 可能很大,但是把很多 Model 平均起來 bias 就很小

我們拿出很多個 minibatch 各產生一組 Network 來 Train
雖然說一個 Network Structure 只用一個 batch 來 train
但是一個 Weight 可能被很多不同的batch train 到!

Dropout 的機制下我們總共 Train 了 2M 這麼多組一大把的 Network
Testing 的時候,可以把 data 分別丟到每一個 Network 然後把結果取平均
但是實作上無法這麼做,因為 Network 太多了,運算量太大
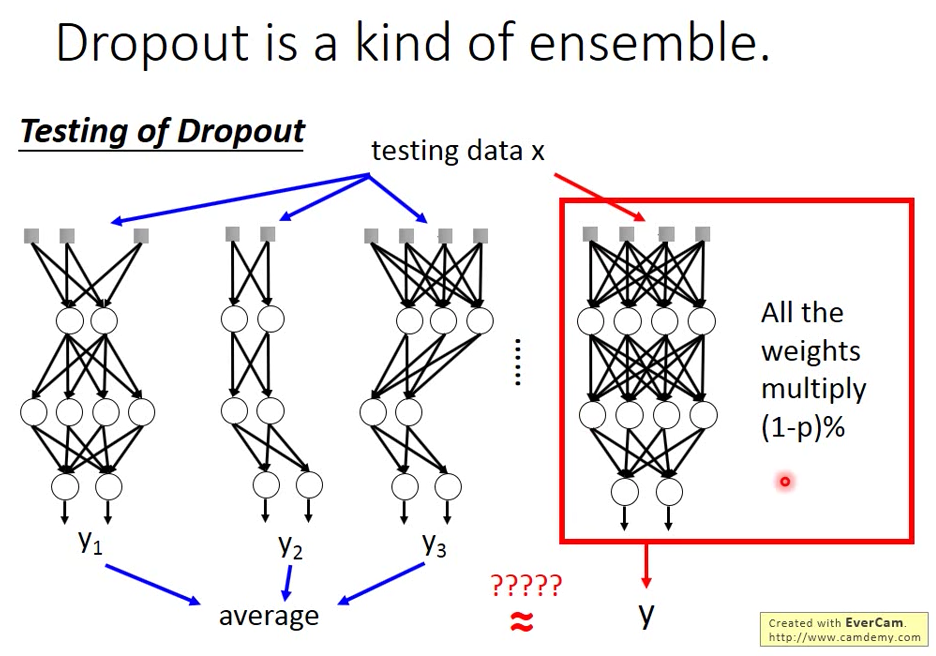
所以在實作上,我們把完整的 Network 不做 Dropout 然後把 Weight 乘上 (1-p) %
神奇的是在於,這樣的結果跟我們 一個一個分別丟進 dropout network 後在算平均的結果是相近的!
為什麼這樣結果會相近呢?
舉個例子說明:
假設我們有個 Neutron 長這樣
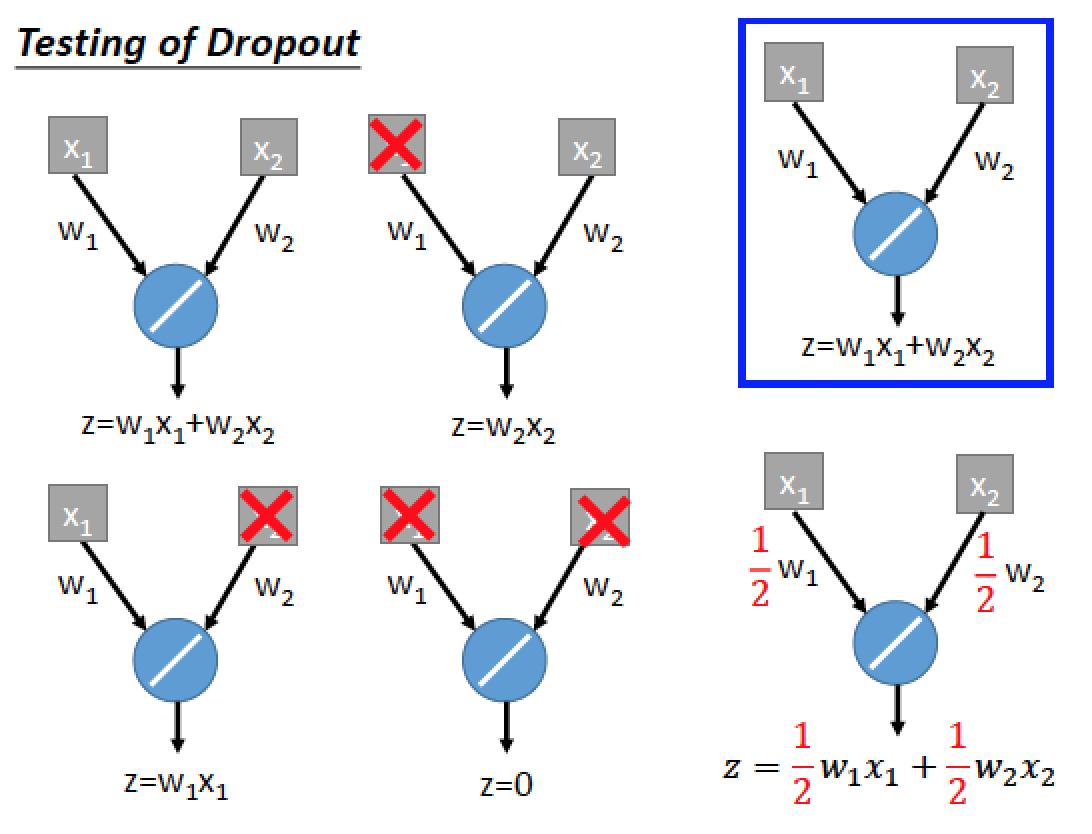
根據 Dropout 的機制
兩個 input 有選跟不選的可能,共有四種,我們把算出來的結果平均起來
恰好跟不做 dropout 的情況下,直接把 weigth 乘上我們 dropout 機率 ½ 的結果是一樣的!
上式只有在 linear network 的情況下才成立!
如果 neutron 裡面的 function 是 sigmoid function 的話,就不相等
如果 neutron 裡面的 function 是 sigmoid function 的話,就不相等
所以當我們的 function 接近 linear 的時候,Dropout 的效果最好!
結論 Dropout 用於使用 ReLU 或是 Maxout 這種 Linear 的 Network 上效果較好!







留言
張貼留言