[ML筆記] Regression part 1 - Case Study
ML Lecture 1: Regression - Case Study
本篇為台大電機系李宏毅老師 Machine Learning (2016) 課程筆記上課影片:
https://www.youtube.com/watch?v=fegAeph9UaA
課程網 (投影片出處):
http://speech.ee.ntu.edu.tw/~tlkagk/courses_ML16.html
回歸 (Regression) 怎麼做呢?
step1: 找一個 Model => 找一個 Function Set
舉例:寶可夢的cp值
y= b + w * x
w: weight
b: bias
y: function 的 output → 進化後的 cp 值
x: function 的 input → 現在的 cp 值
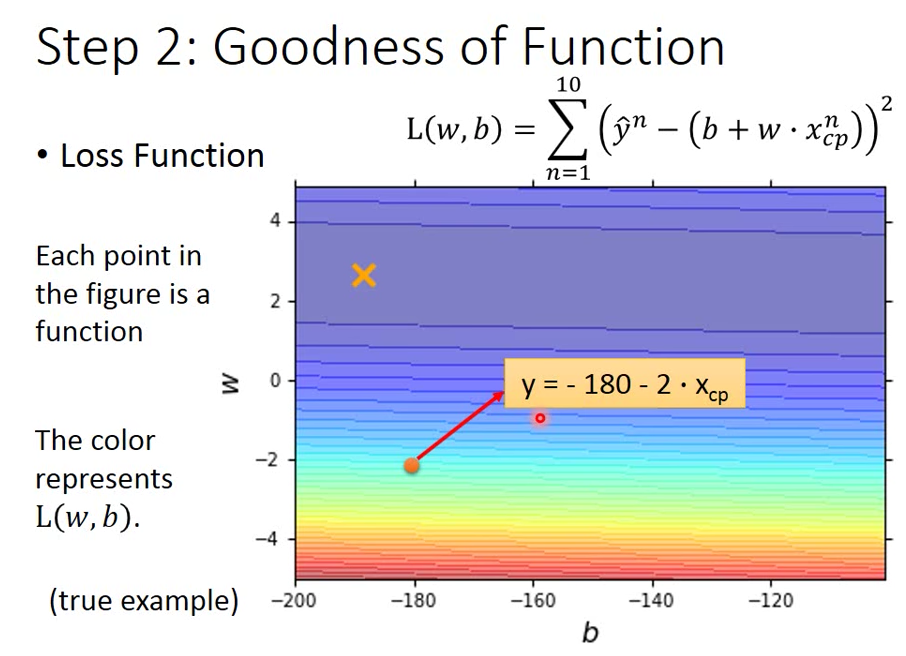
step2: 定好 Loss function 計算 Goodness of function
定義 L(f)=L(w,b)
input: a function
output: how bad is
L(f) 是我們定義的 Loss function 很直觀的就是我們進化後的真實 cp 值減掉我們預估出來的 cp 值,得到誤差值
上面的式子 n=1 ~ 10 是指我們有 10 筆 testing data
找到 loss 最低的就是最好的 w, b 參數組合
step3: 挑選一個最好的 function
Best function

可使用 Gradient Descent 的方法
利用微分得到斜率,來得知下一個點,一步一步得到斜率最低的點
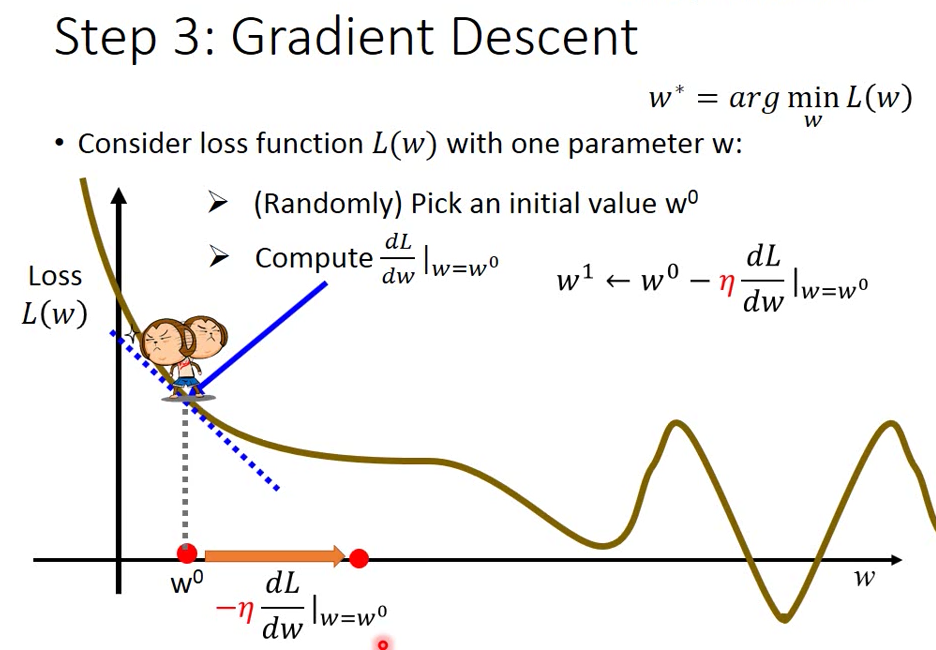
參數更新的幅度(踏一步的距離)取決於兩個因素
- : 讀音 “意塔 yita” 代表 Learning rate
- 微分值大小,如果 dL/dw 小,則踏一步就會改變很多
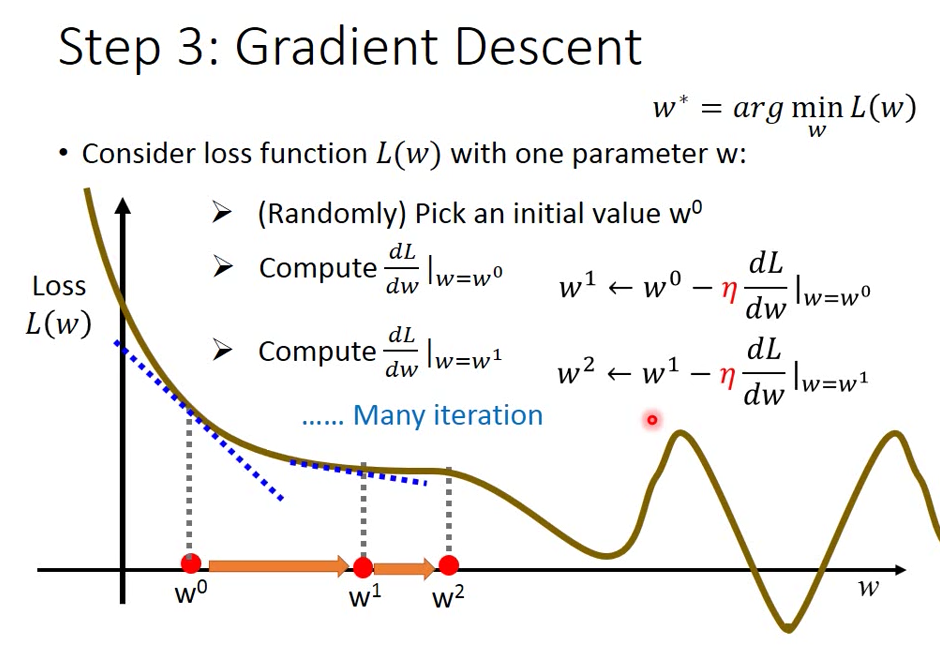
所以做 Gradient Descent 的步驟
隨機挑選兩個 w 跟 b 計算
Lw與Lb
得到
w1=w0-Lw |w=w0, b=b0
b1=b0-Lb |w=w0, b=b0
得到 w1, b1後,在迭代繼續求 w2, b2
w2=w1-Lw |w=w1, b=b1
b2=b1-Lb |w=w1, b=b1
我們做完以上的 gradient descent 的運算找出一組 b, w值
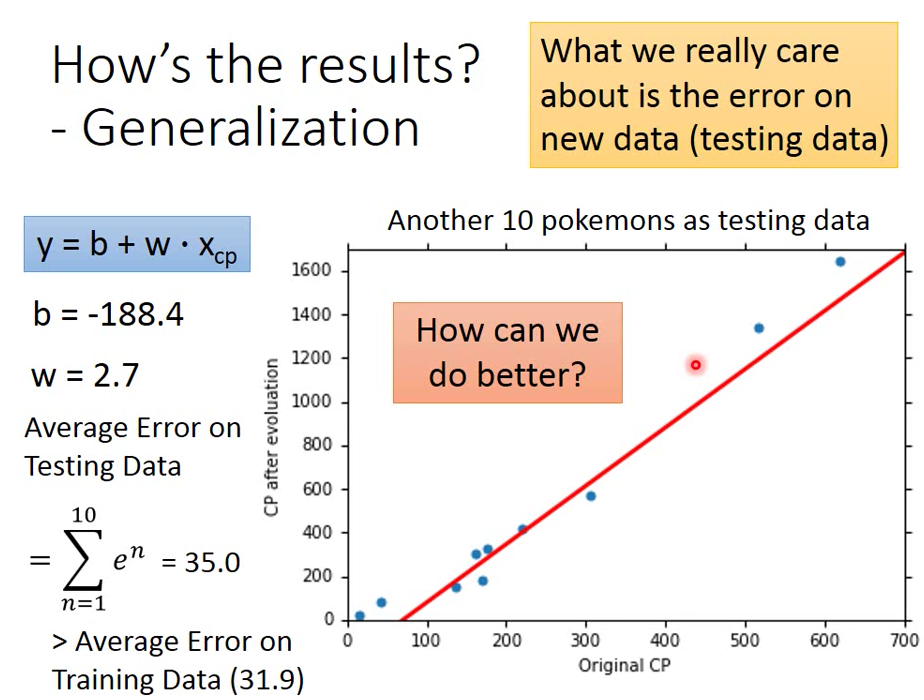
在 training data 上的 error 總和是 31.9
我們在用十筆新的 data 當作 testing data 得到的 error 總和是 35
那我們如何能夠做得更好呢? → 那就重新設計我們的 Model
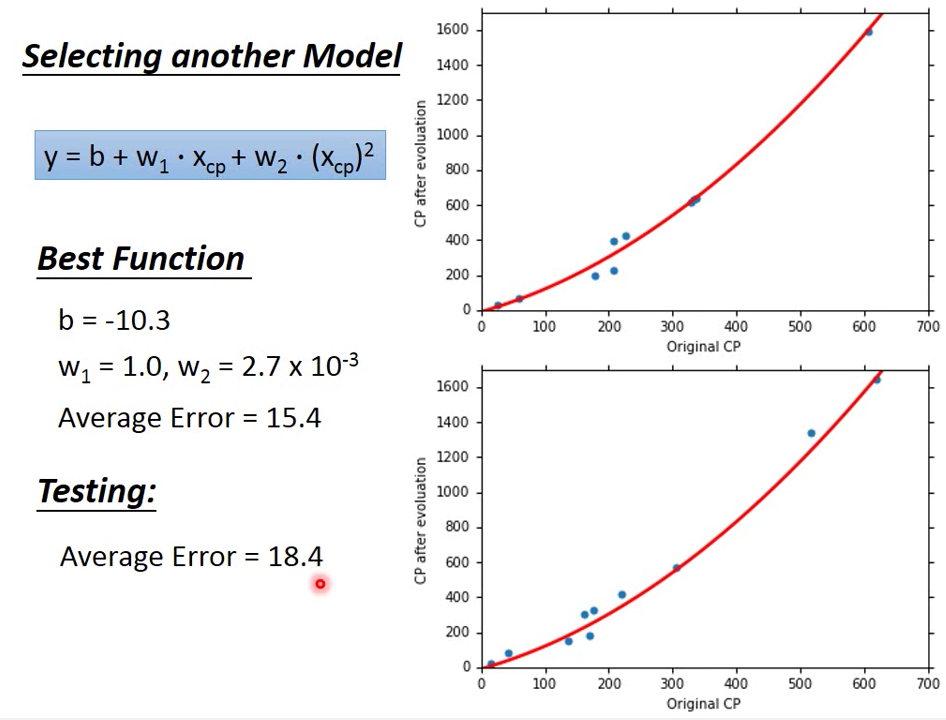
使用二次式 Model 來預測
| 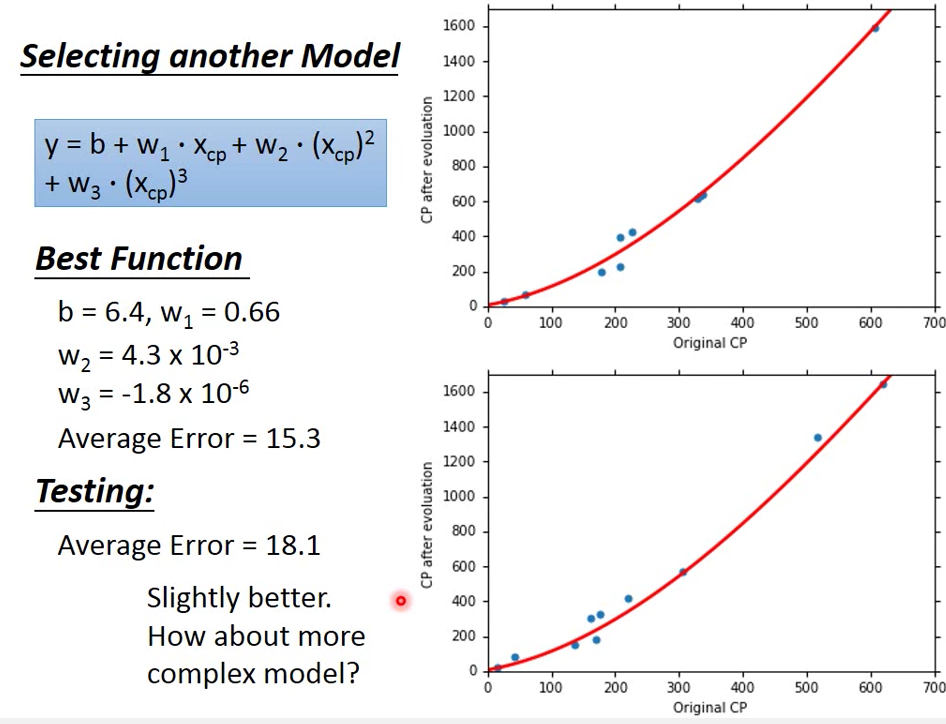
使用三次式 Model 來預測
|
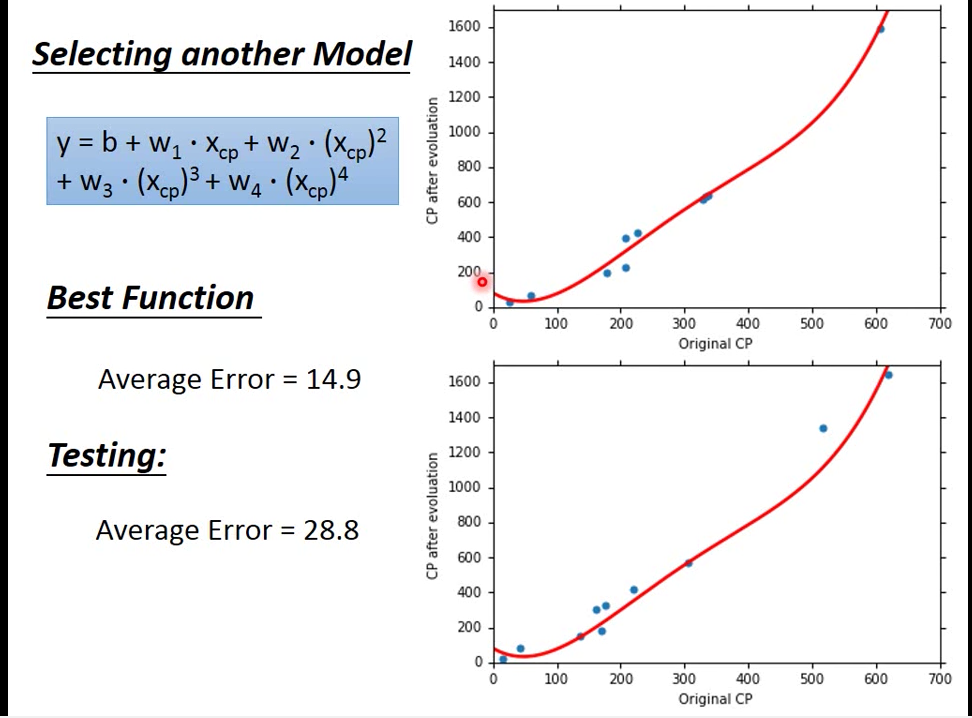
使用四次式 Model 來預測
| 
使用五次式 Model 來預測 test 時爆炸了
|
結論

雖然越複雜的 Model 可以在 Training Data 上可以得到更好的結果
但是越複雜的式子在 Testing Data 不一定能夠得到比較好的結果
所以上例當中,四次式 model 即 五次式 Model 的結果就是 overfitting

當我們搜集的 data 更多的時候,我們發現進化後的 cp 值也會受到物種的影響

所以需要重新設計一下我們的 function set
 |  |
把左邊的條件加上對於每個物種都 fit 一個 linear model
右邊是把左邊的 if 條件,改採用 delta function 來實作
我們要使用夠多量的 training data 來找出一個剛剛好的最適合 Model!
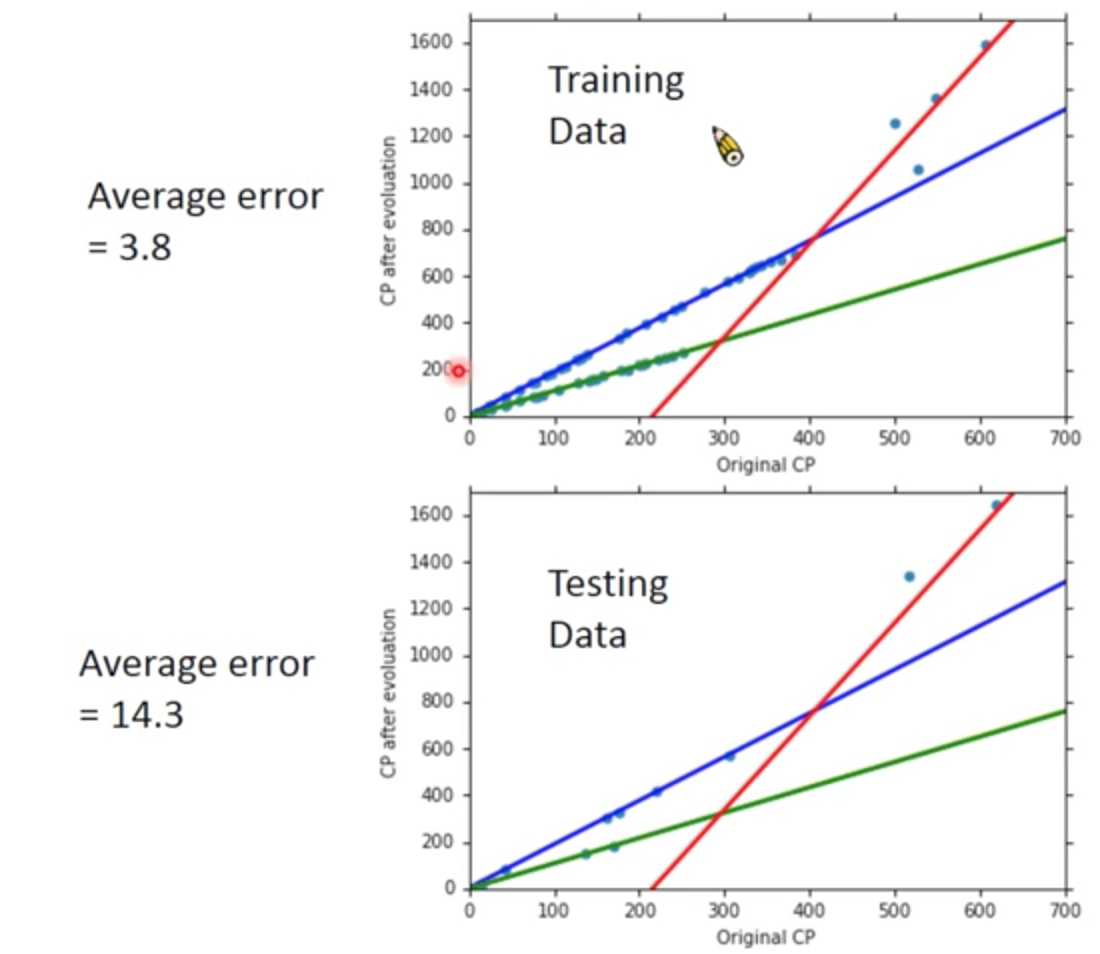
目前為止,加上各種物種的條件判斷後,error 又更低了,但是還是有些可以更好
或許寶可夢進化後的 cp 值,還跟hp值有關,或寶可夢的身高體重有關
所以我們就把所有的條件,再加進來,製造一個更為複雜的 model
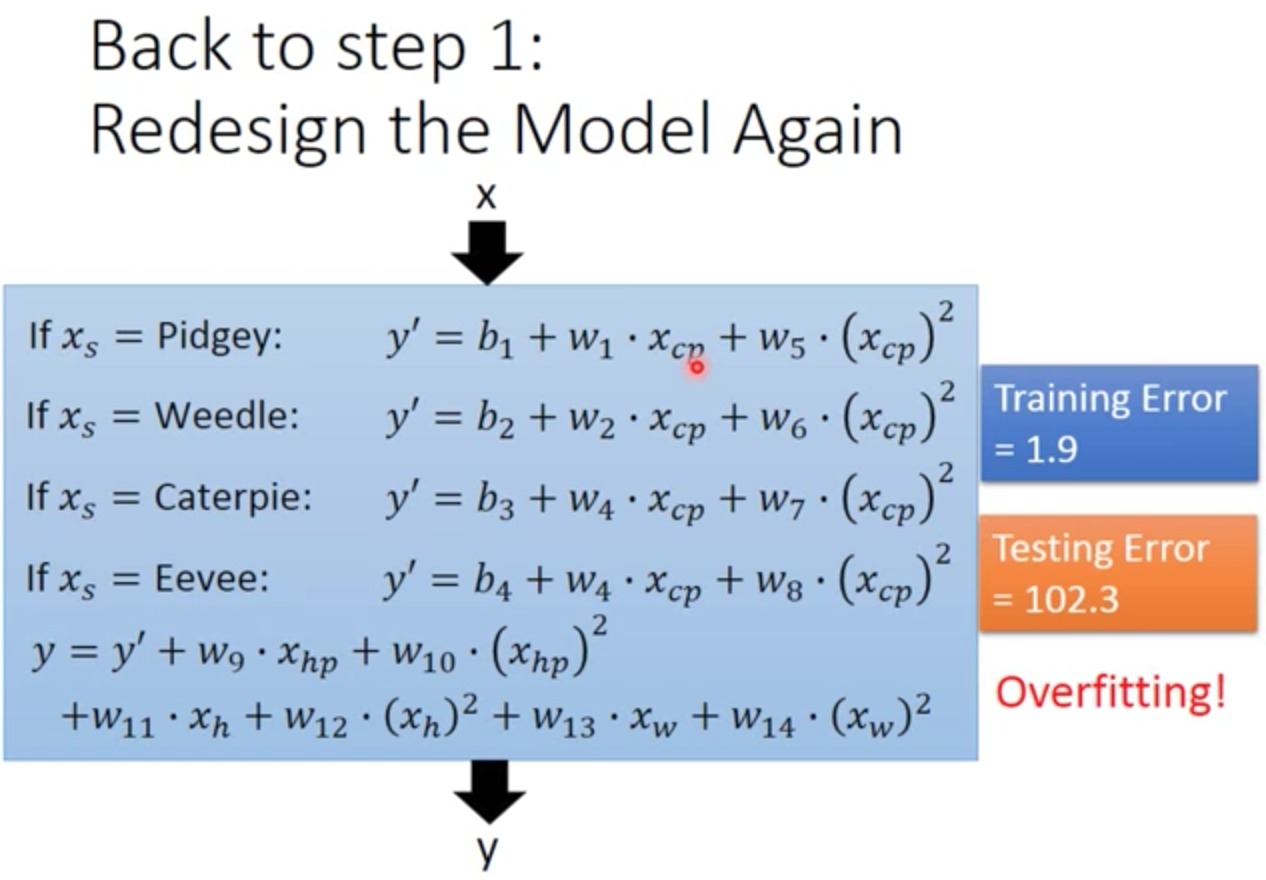
當我們採用了更複雜的 model 去考量時,發現 Training Error 又降低了
但是 Testing Error 增加不少,發生 overfitting 的情形!
如果我們是大木博士的話,對寶可夢的特性很了解,可以知道哪些 feature 可以捨棄掉,但是我們不是大木博士怎辦呢?
→ 使用 Regularization!
Regularization: 重新定義 Loss function 的內容,讓我們找到更好的 Model

regularization 想法,當 wi 幾近零,輸入變化對於輸出變化的影響就會比較小,會得到比較平滑的 function
| 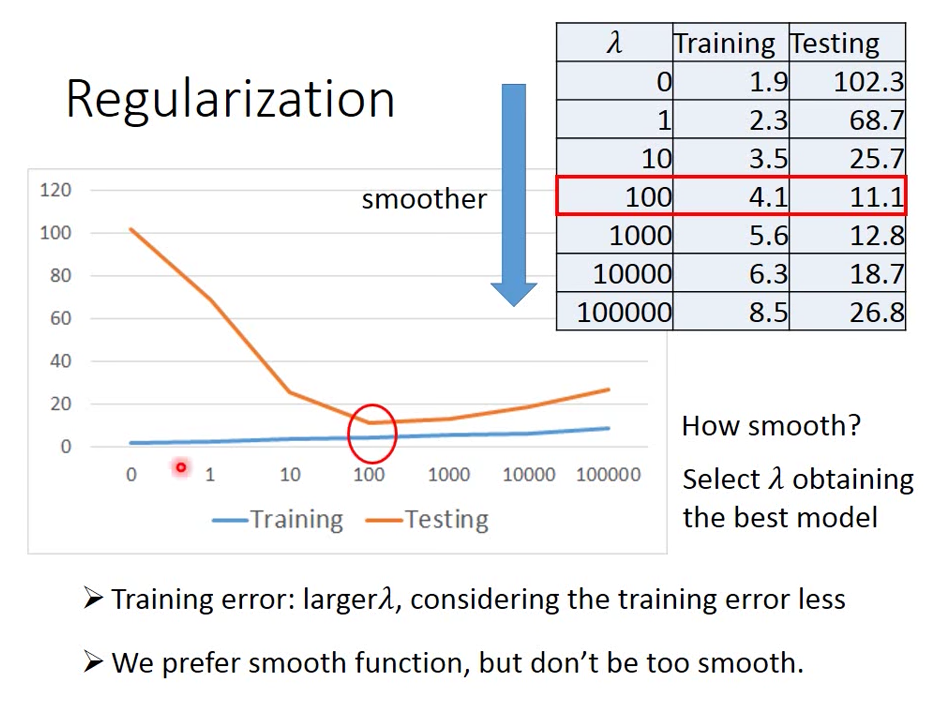
實驗結果顯示,當 lamda 值越大,Regularization 影響力越大,function 越平滑,Testing Error 越小
|
在 Loss function 加入一個額外的(wi)2項 (做 regulariztion)
後面這個參數越小,代表他是比較平滑的 Model
想:
輸入地方如果加上一個 xi,則輸出的地方就會加上一個 wi * xi
所以如果 wi越小,則輸出對於輸入就不敏感 sensitive 得到比較平滑的 function
所以加上的概念就如上表右圖,當越大時,考慮 smooth 的影響越大,我們越傾向考慮 w 本身的數值,而漸少考慮 error 值,考慮 error 比較少,所以我們在 training data 的 error 就會比較大,但是在 testing data 得到的 error 可能會比較小,對於 noise 比較不 sensitive
所以我們喜歡比較平滑的 function,但是我們又不想太過平滑,所以調整出一個適合的 就可以用來調整這件事!
Tips:
在做 regularization 這件事,是不考慮 bias 這項的,因為調整 bias 這項對於 function 的平滑程度是沒有關係的






留言
張貼留言