[ML 筆記] Transformer(下)
Transformer 筆記(下)
本篇為台大電機系李宏毅老師 Machine Learning (2021) 課程筆記
上課影片:https://youtu.be/N6aRv06iv2g
延續上一篇:[ML 筆記] Transformer (上)
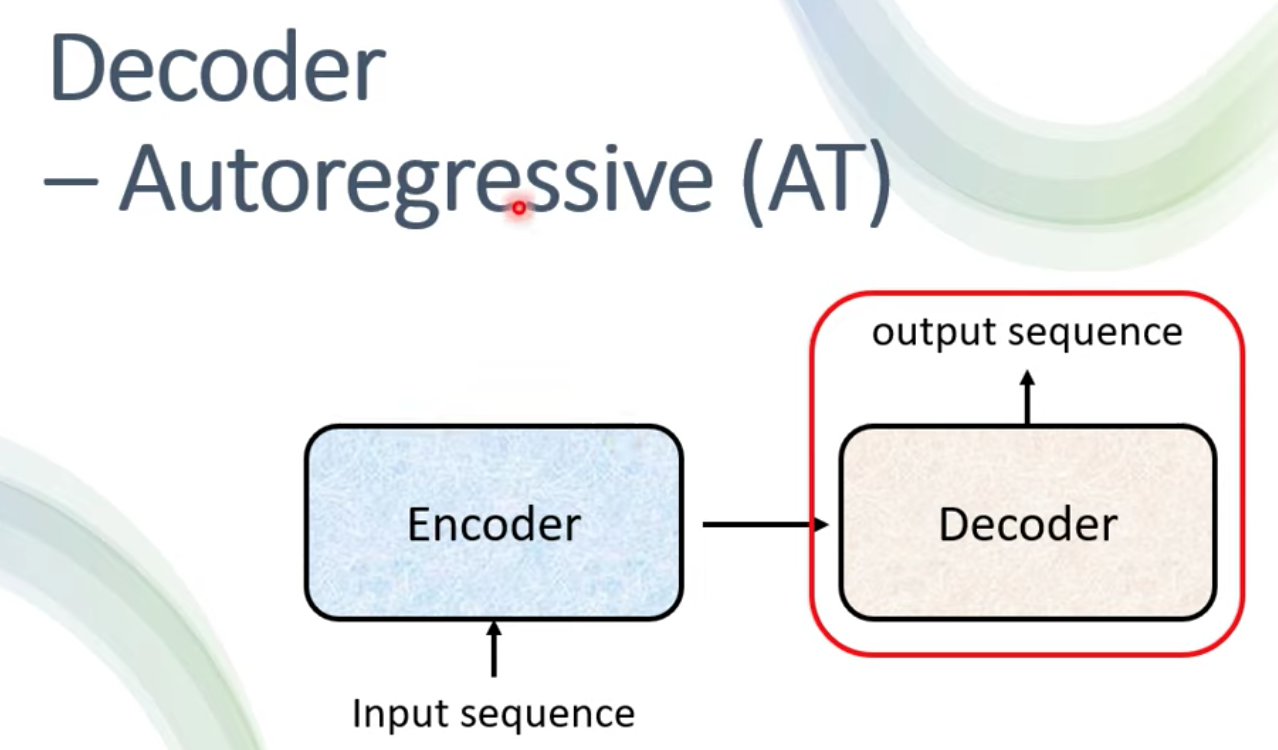
我們這篇來介紹 Transformer 裡面的 Decoder 部分
Decoder 其實有兩種,我們先來介紹一個比較常見的 Autoregressive (AT) Decoder
(以下討論以語音辨識為例)
我們把 Encoder 的輸出接到 Decoder 裡面後,來探討,decoder 要怎麼產生輸出
首先,會有個代表 “開始” 的特殊符號 BEGIN (special token) 讓 Decoder 知道從這開始
接下來 Decoder 會吐出一個向量
這個向量長度很長 例如這個 Size 長度 V 可以是中文所有方塊字(例如5000個字)
而不同的語言,輸出端的單位都不一樣
例如英文,可以輸出所有可能的詞彙 (想必量超大,可能會有各式各樣的詞彙組合)
中文,可以用中文的方塊字的數目,當作單位 (例如5000個常用單字)
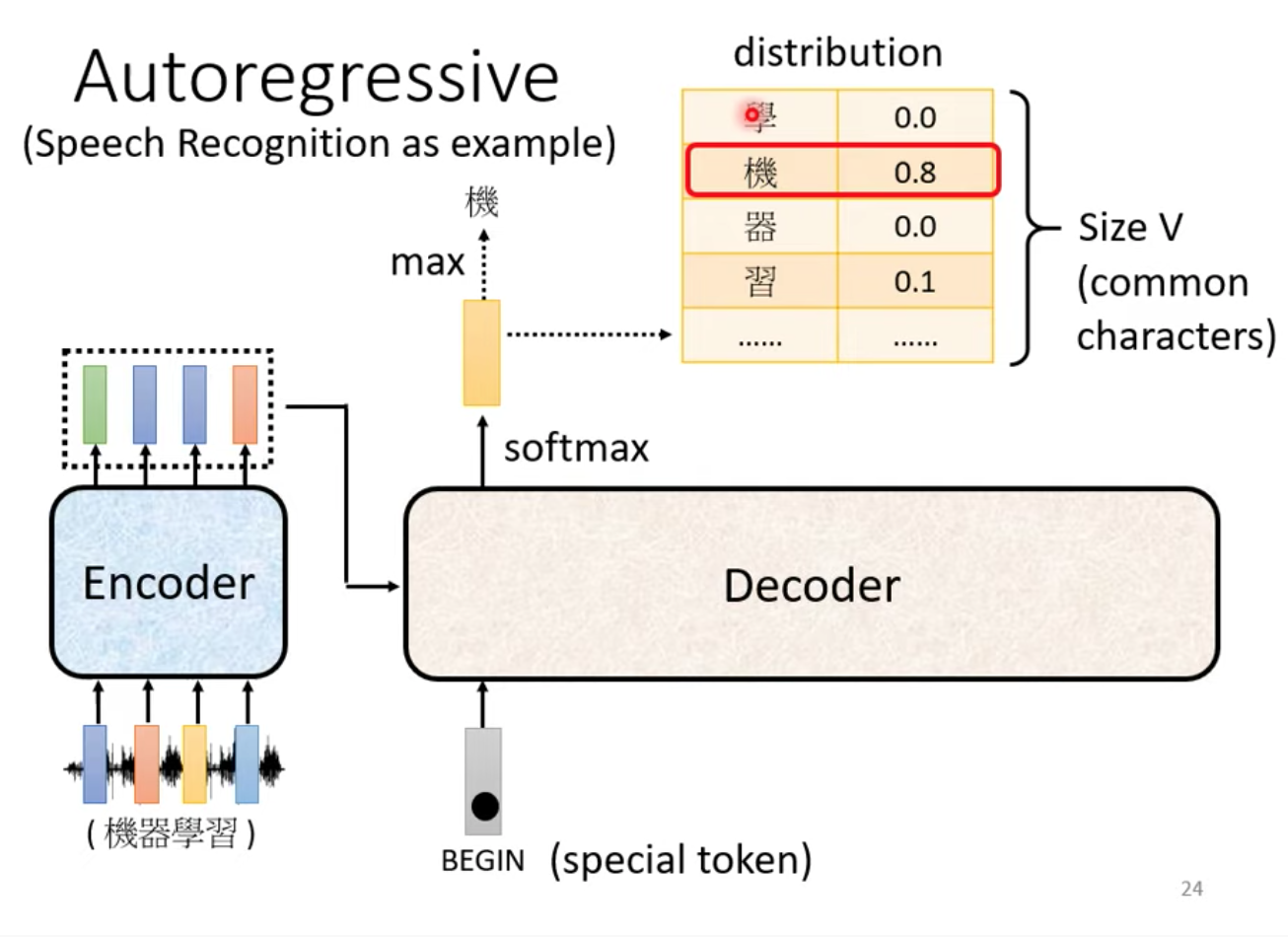
BEGIN 過了 Decoder 輸出前我們會過個 softmax 讓輸出的機率總和為一
圖中的例子,我們得到 “機” 這個字得到的分數最高,所以我們第一個輸出字為 “機”
接下來
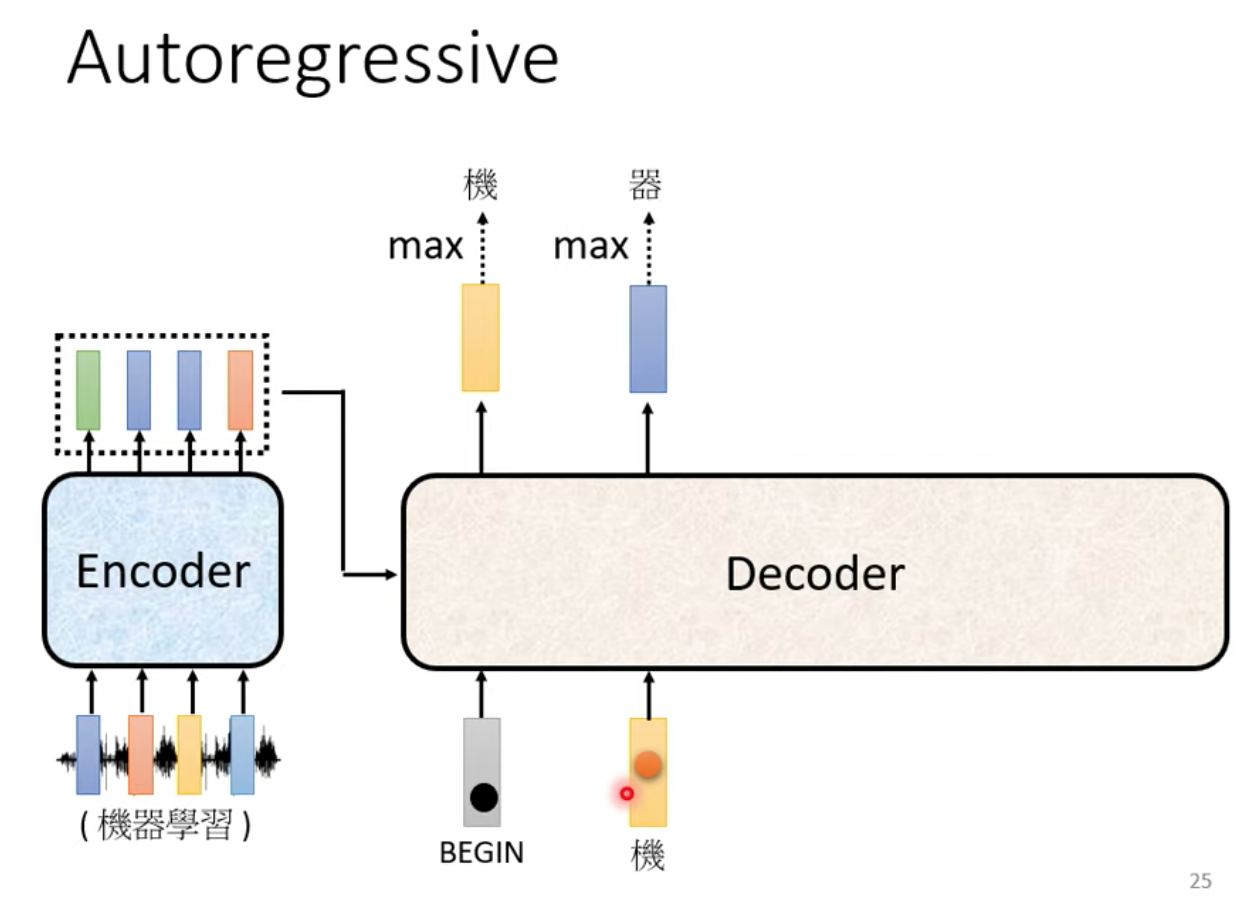
我們把 encoder 的輸入、BEGIN 跟 “機” 一起丟到 Decoder 裡面,決定接下來要輸出什麼
運算出來後我們得到 “器” 這個字
接下來,我們把 encoder 的輸入、BEGIN、“機” 跟 “器” 一起丟到 Decoder 裡面,決定接下來要輸出什麼,如此一直重複動作
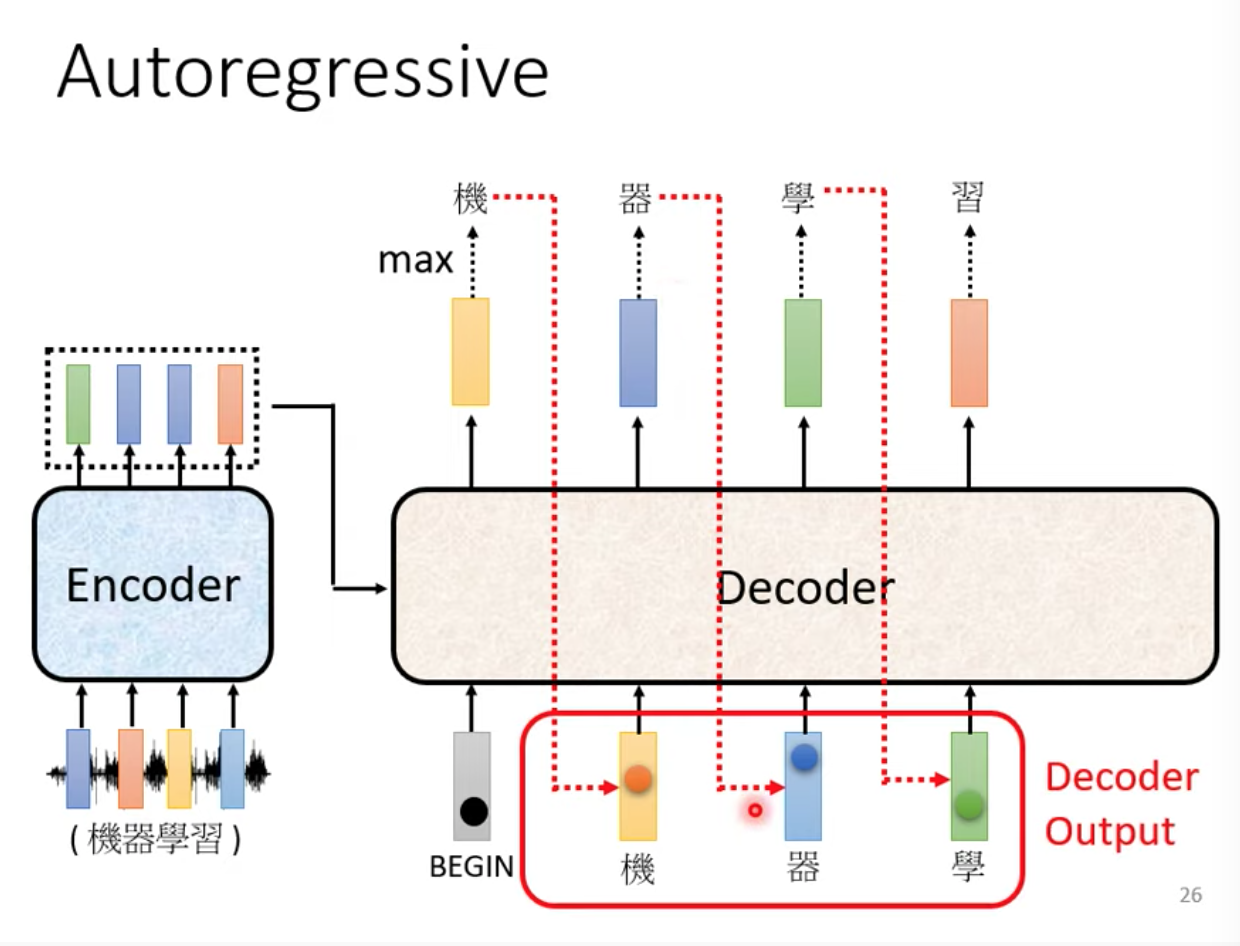
Decoder 會把自己前一個時間點的輸出,丟到 input 裡面產生輸出
在這個架構下,可以觀察出,如果 Decoder 過程中其中一個字弄錯了,就可能連帶地影響到接下來輸出的正確性,造成一步錯步步錯的窘境
關於這個問題等等來討論
接著我們來看 Decoder 內部的詳細架構
Decoder 的內部架構
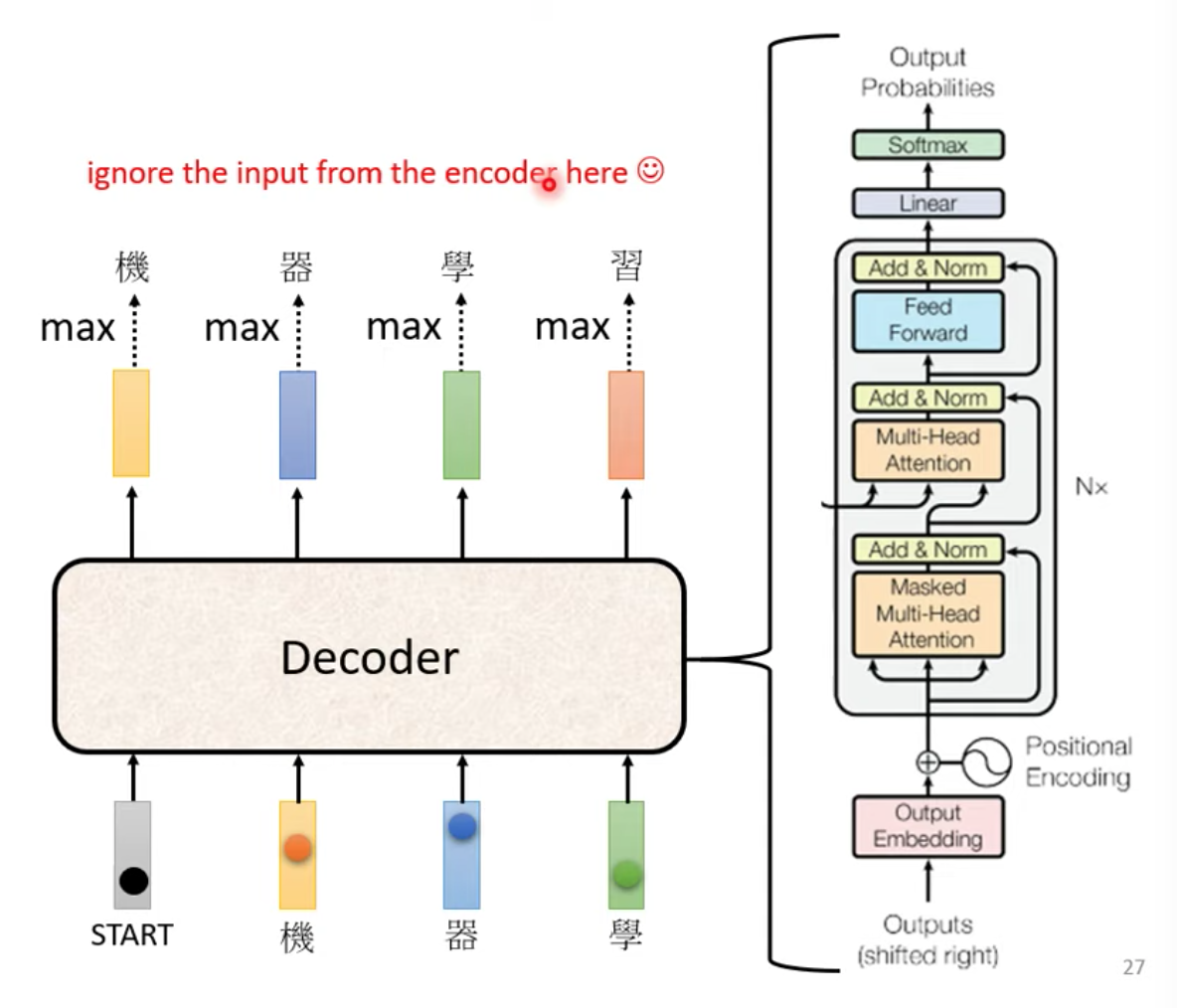
看起來有點複雜
我們先把 Encoder, Decoder 放在一起稍微比較一下
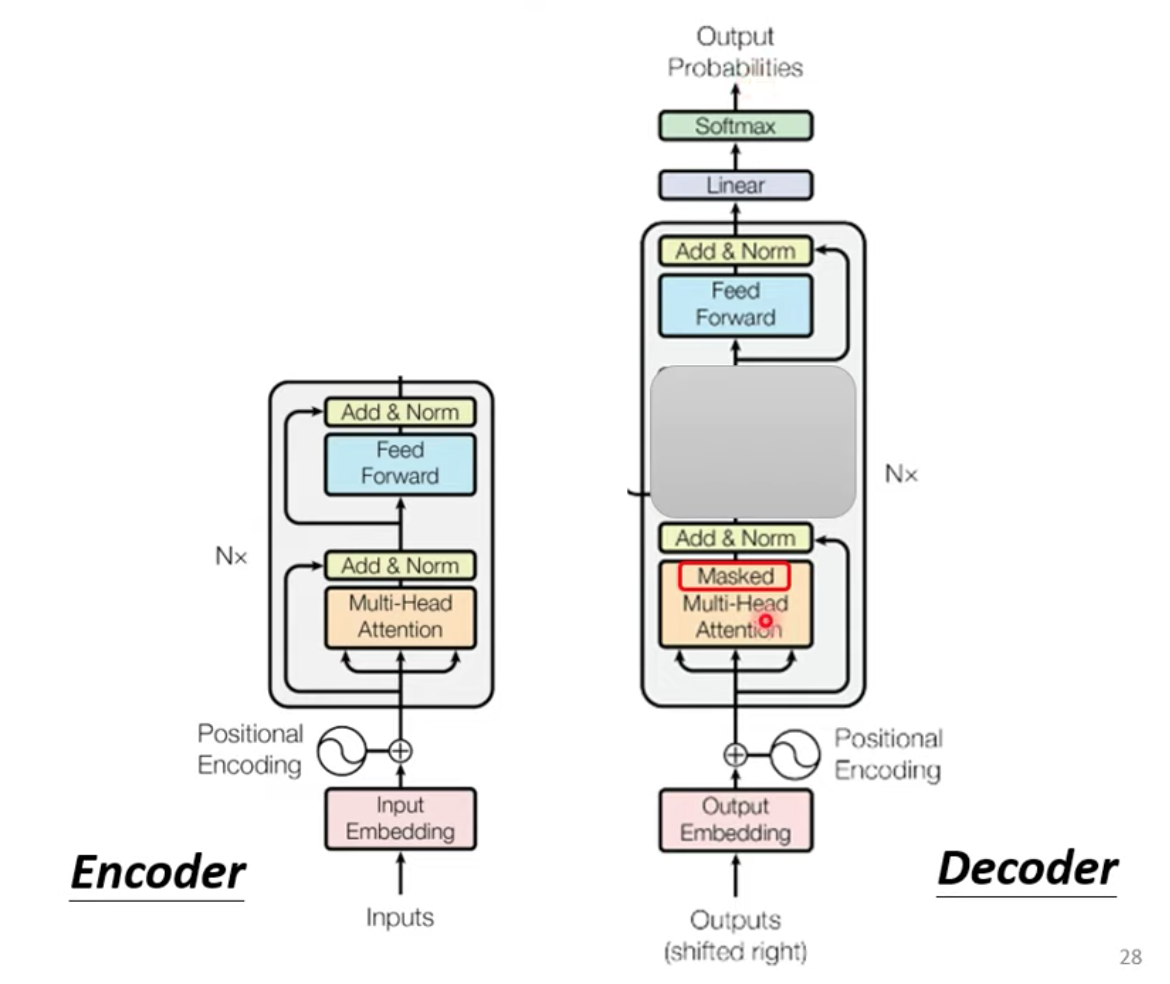
如果把 Decoder 中間那一塊先用灰色遮起來不看的話,
可以發現 Encoder 跟 Decoder 架構基本上是一樣的,
只有在 Decoder 的 Multi-Head Attention 的地方多加了一個 Masked
那所謂的 Masked 是什麼意思呢?
Masked self-attention v.s. Self-attention
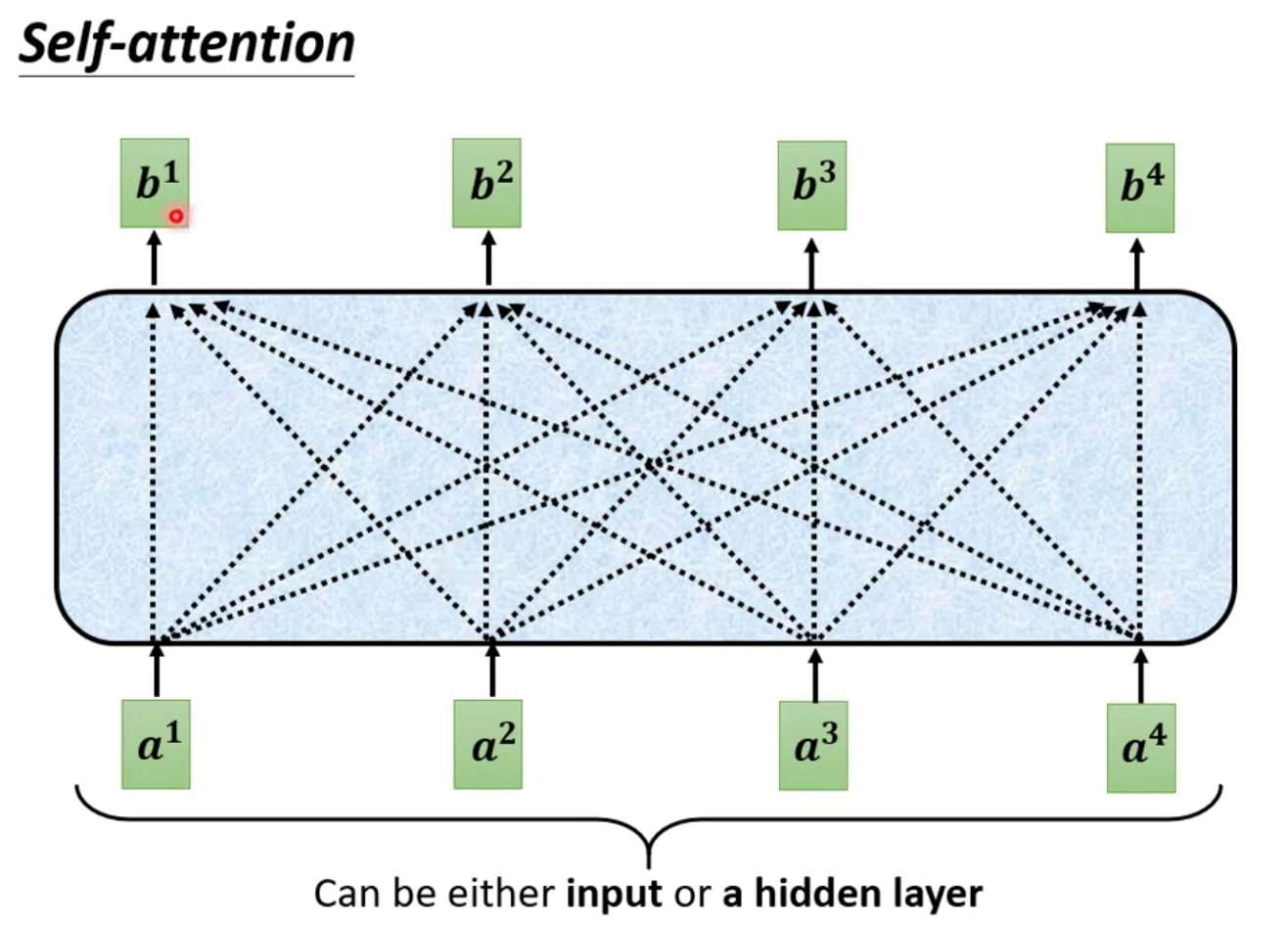
如上圖:在原本的 Self-attention 設計中,b1 ~ b4 都考慮了所有的 a1 ~ a4 的資訊

而在上圖中的 Masked self attention 機制下,當我們要產生 b1 的時候,只能可慮 a1 的資訊
產生 b2 的時候,只考慮到 a1 跟 a2 的資訊,產生 b3 的時候,只能考慮到 a1 ~ a3 的資訊
依此類推
用下一張圖再講得更具體一點,
當我們要產生 b2 的時候,我們只考慮 a1 跟 a2 產生的 q1 q2 去計算 attention

Why masked? (想想為什麼需要加 Masked呢?)
其實非常直覺,因為在 Decoder 端,我們收到 Encoder 端 outout 的資訊是 先有 a1 才有 a2 … 因此我們無法同時拿到全部 a1 ~ a4 所有資訊
另一個重要的問題就是:Decoder 必須自己決定輸出的 sequence 長度
But 輸出的 seq 長度究竟要多少呢??
我們目前的運作機制裡面,機器不知道到底何時要停下來

我們要特別準備一個特殊符號 END 讓 decoder 可以停下來
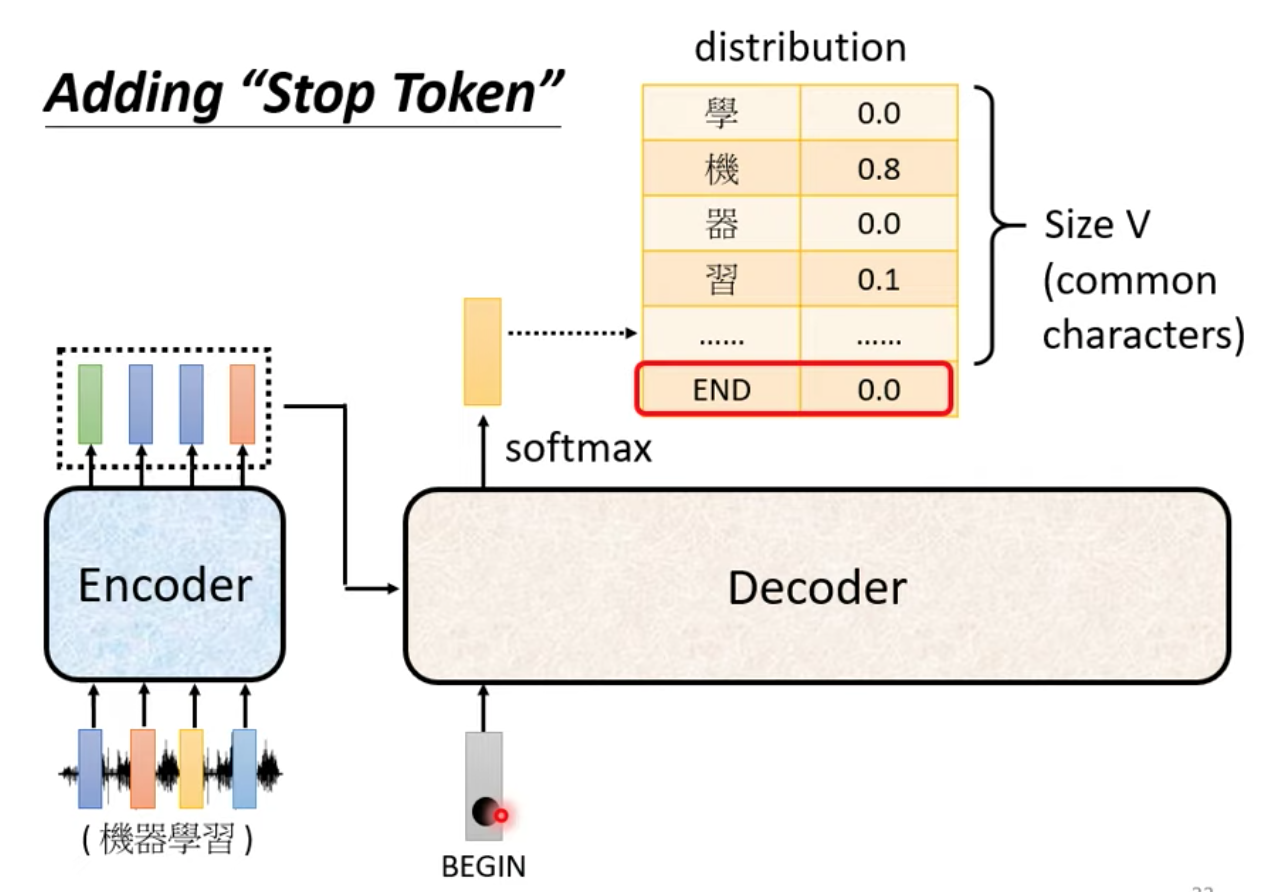
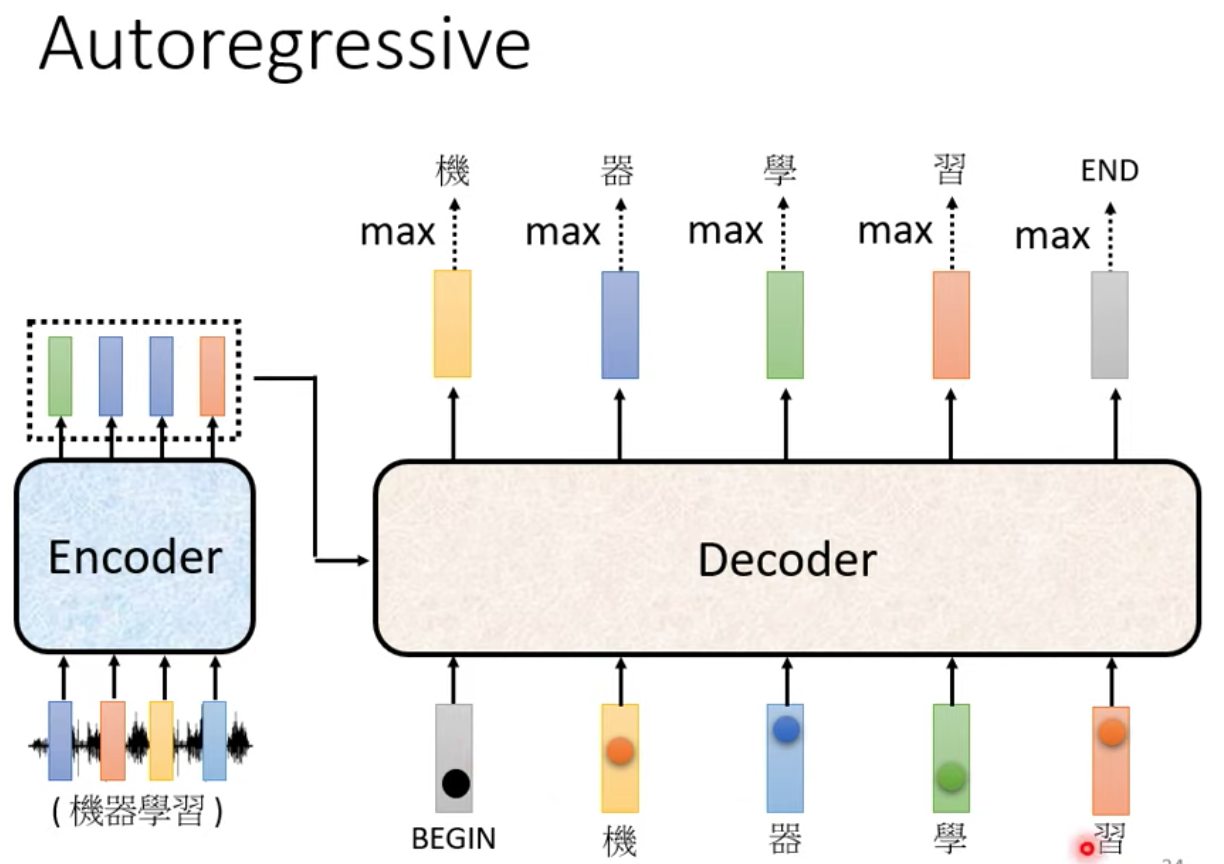
當機器讀到 BEGIN 與 機 器 學 習 這四個 input 的時候,可以使得 END 的機率值是最高的,輸出 END 作為 output sequence 的結尾!
NAT
接下來,來簡短地講一下 Non-autoregressive model (NAT)

Autoregressive (AT) V.S. Non-autoregressive (NAT)
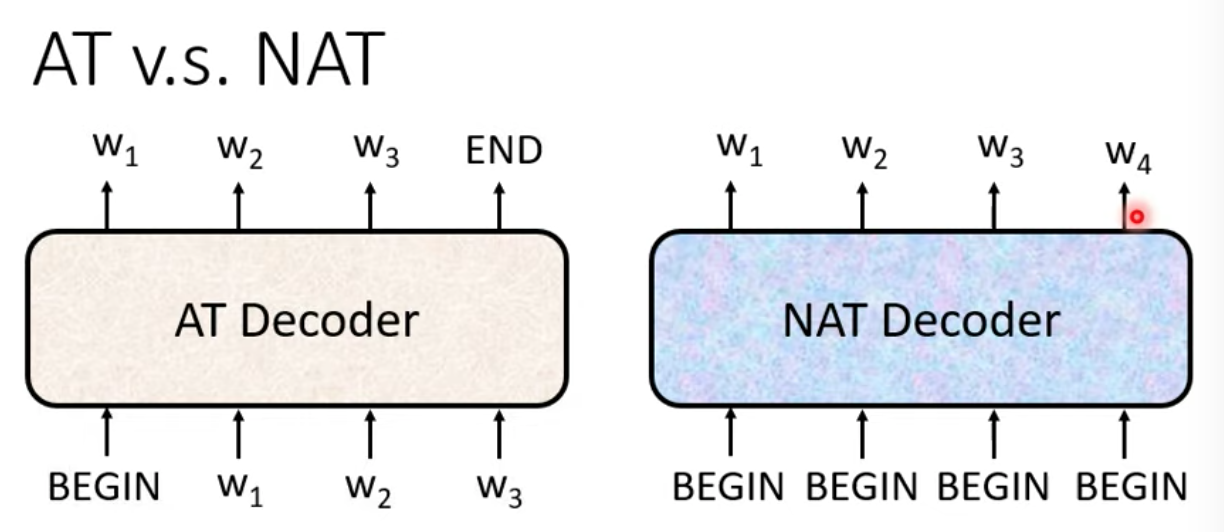
AT: 先輸入 BEGIN 出現 w1 再把 w1 當作輸入,依序做到出現 END 為止
NAT: 一次就把整個句子產生出來,input 四個 BEGIN token 一次輸出一串句子就結束了
在這邊可能會有個疑問,我們怎麼知道要丟幾個 BEGIN token 進去 NAT 裡面呢?
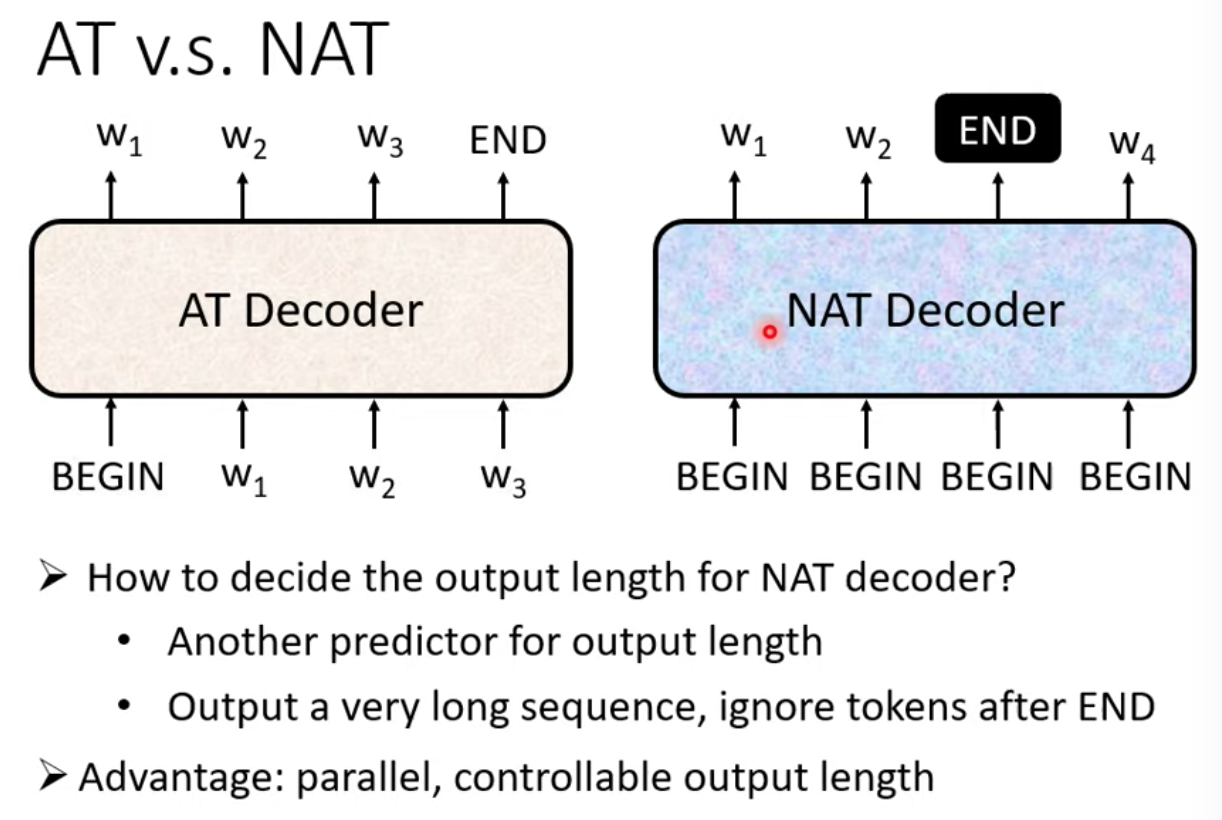
* 可能的解法是 train 一個 classifier 來決定要丟幾個 BEGIN token 進去 NAT 裡面
* 另一種可能的解法是 不管三七二十一,一次丟大量的 token 進去,看 NAT 要丟出怎樣的 output ,再從 output 當中找到 END 的 token 把 output 截斷在那邊
NAT 的優勢:可平行化,比較能夠控制它輸出的長度,但 NAT 的 performance 往往不如 AT
例如 train 一個 classifier 來決定 NAT 輸出的長度要多少
接下來要講 Encoder 跟 Decoder 之間,資訊是怎麼傳遞的?
Cross attention 是連接 Encoder 跟 Decoder 之間的橋樑
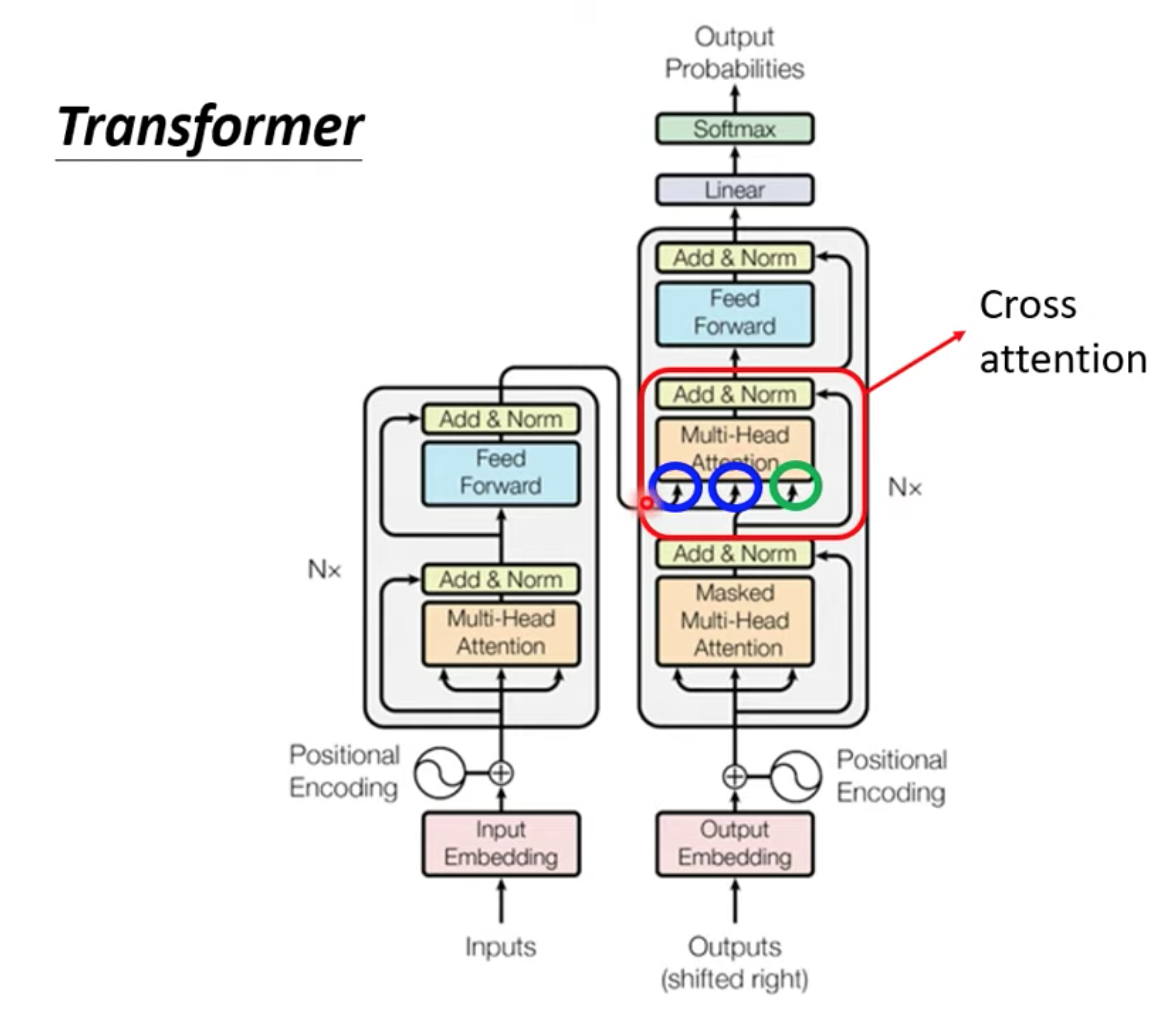
可以看到有兩個輸入來自 Encoder 一個輸入來自 Decoder
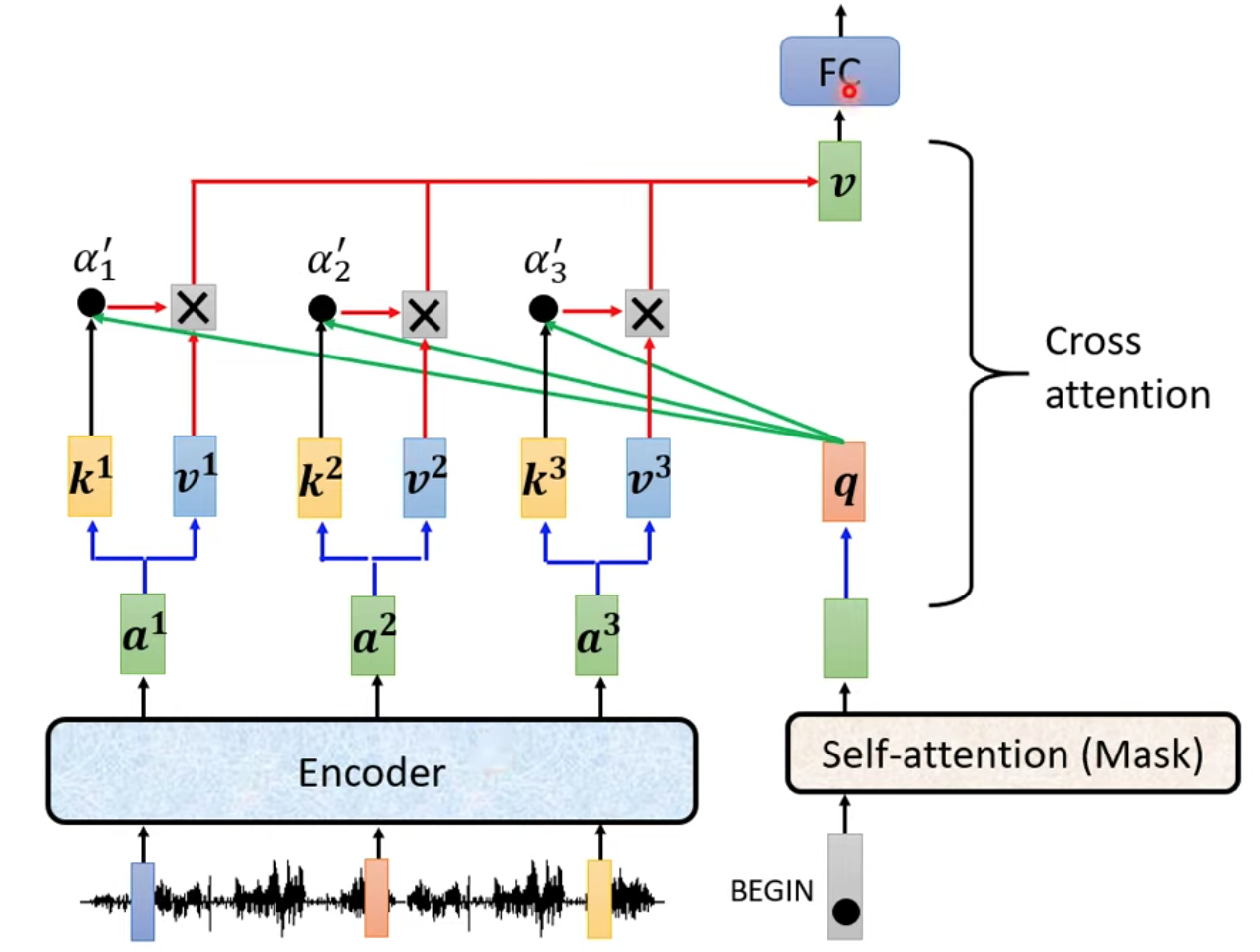
Encoder 處理完 input 之後輸出 a1 a2 a3 向量經過不同的矩陣 W 產生三個 key: k1 k2 k3 跟 v1 v2 v3
BEGIN 經過 Decoder 得到一個向量(圖中綠色),在經過一個矩陣 transfrom 後得到一個 query q 向量
然後把 k1, k2, k3 跟 q 去計算 attention 分數,過了一個 softmax 得到 𝛼1’ 𝛼2’ 𝛼3’
再把 𝛼1’ 𝛼2’ 𝛼3’ 乘上 v1, v2, v3 後把他們 weighted sum 加起來得到最後的 output v
這個 output v 會丟到 FC 做後續的處理
Decoder 憑著產生一個 q 去 Encoder 那邊把資訊提取出來,當作接下來 Decoder 裡面 FC 的 input
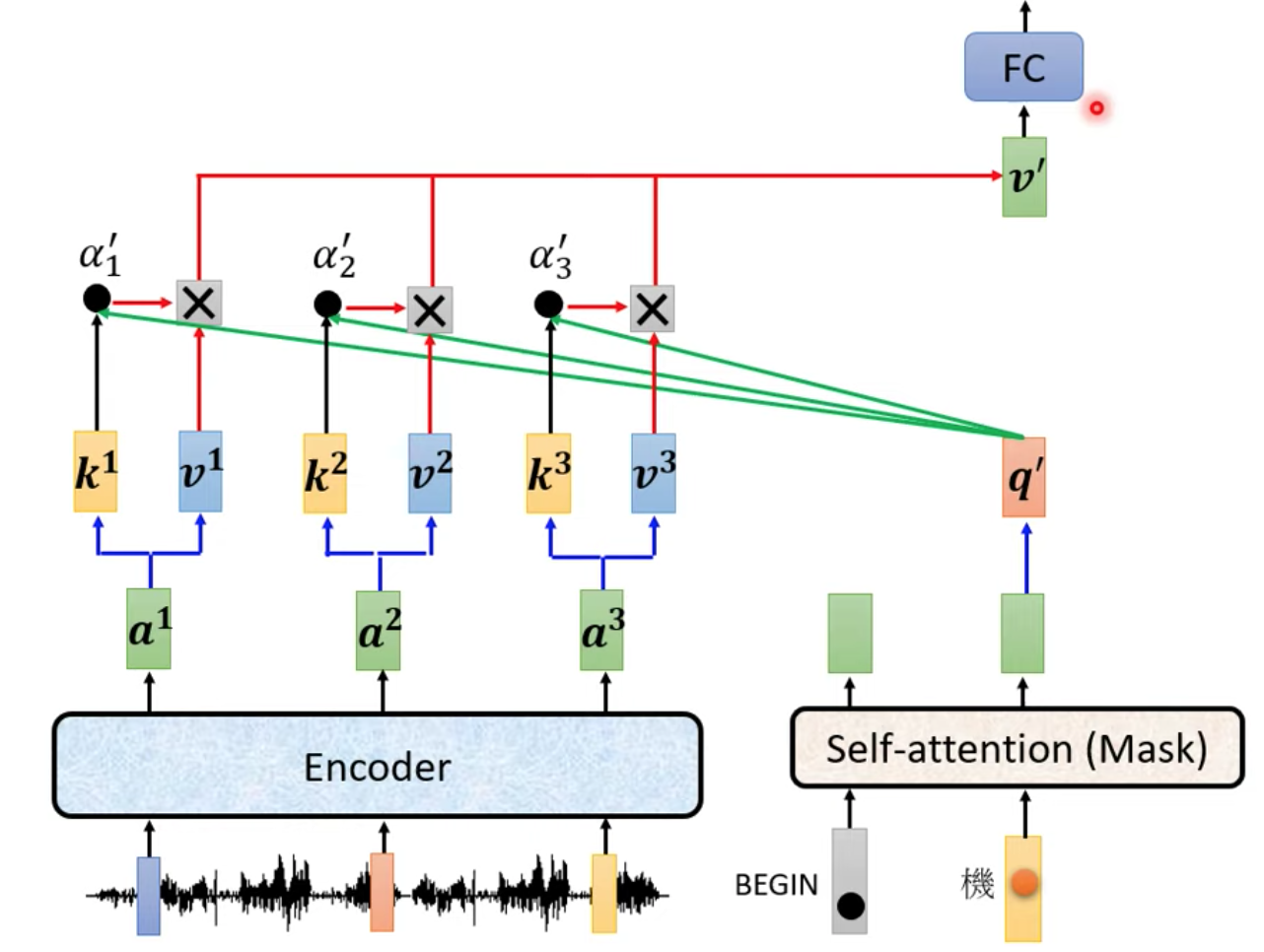
下一個時間點同理,當 Decoder 的 input 是 BEGIN 以及 “機” 這兩個 input 時,重複剛剛的流程,算出 v’
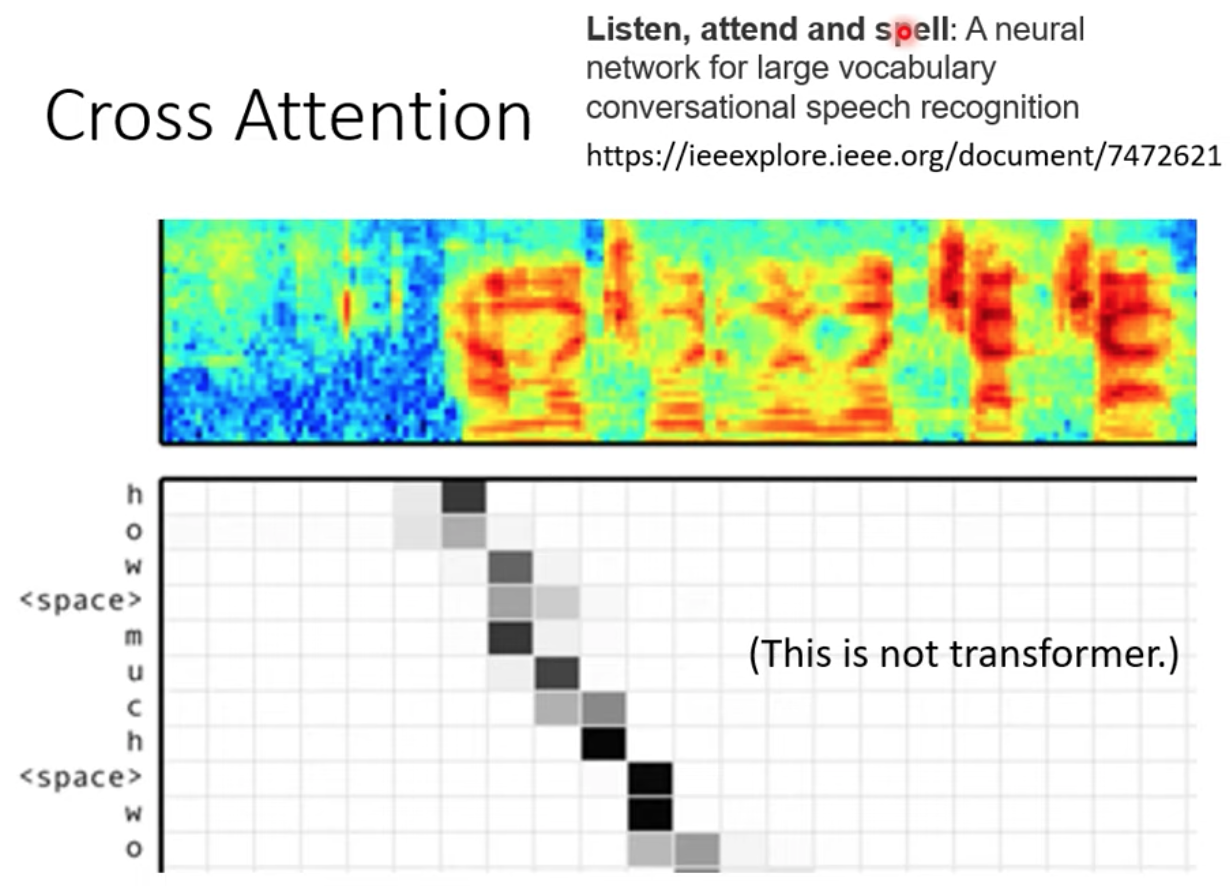
來看一篇 seq2seq 做語音辨識的結果 "Listen, attend and spell: A neural network for large vocabulary"
這篇 paper 推出的時候所使用的 Encoder 跟 Decoder 都是 LSTM
但它有用到 Cross attention 的機制!
如下圖:Decoder 端一次只吐一個英文字母,當它輸出空白 <space> 時,代表單字的結尾斷點
input 是一段聲音序號抽出來的 vectors

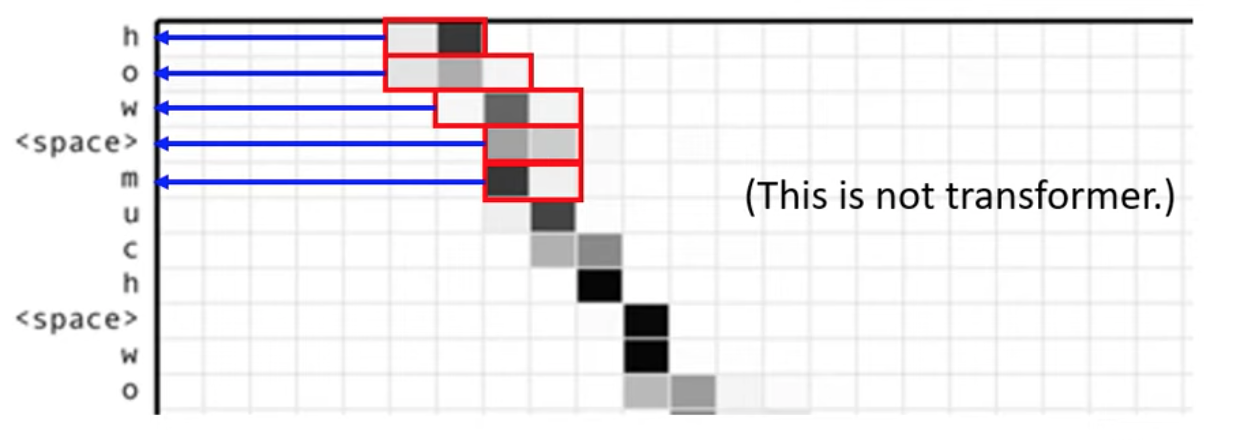
上圖網格中顏色越深,attention 的分數 (也就是 𝛼 值) 越大
Decoder 會對 Encoder 的輸出去做 attention 可以觀察它不同 attent 位置跟對應的輸出字母
目前介紹的 Cross Attention 架構中 Decoder 的不管哪一層都是拿 Encoder 的最後一層的輸出當 input
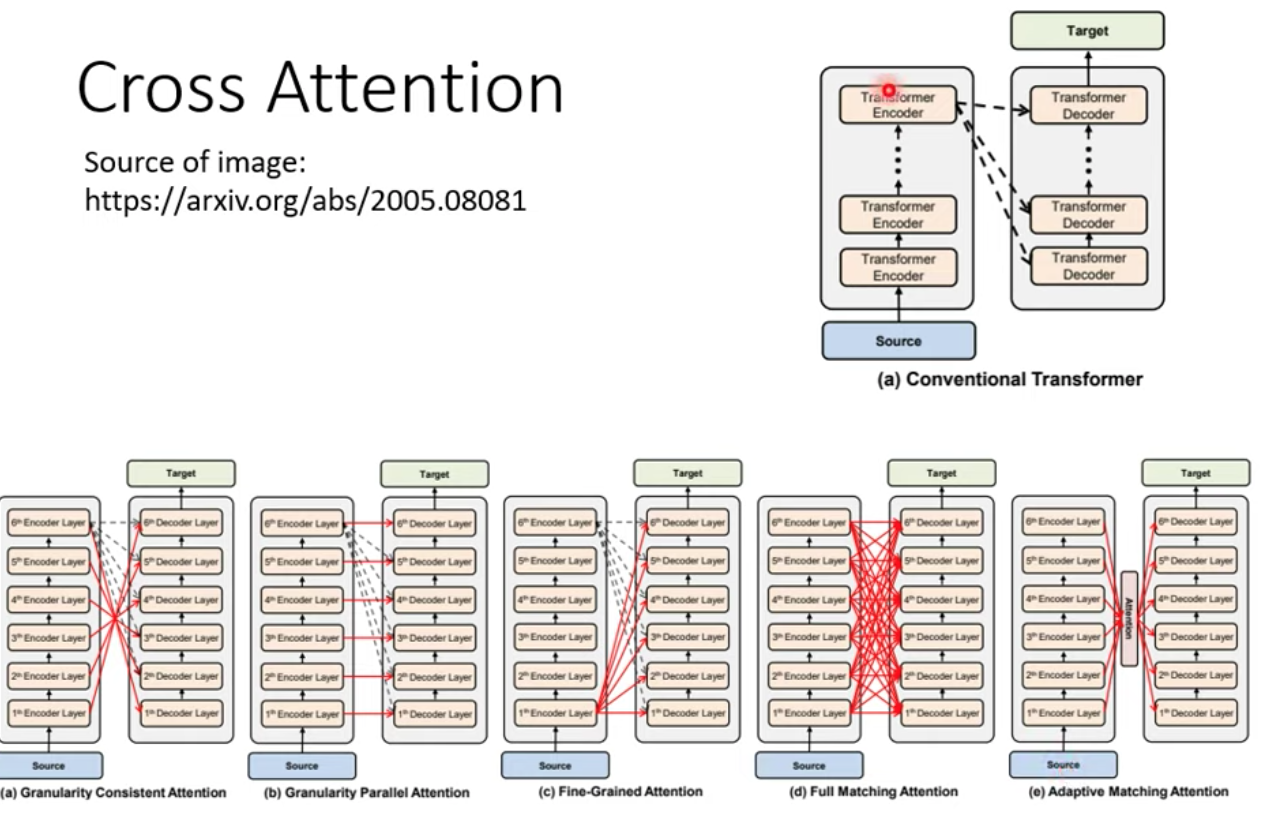
但也有人做其他的嘗試,讓 Encoder 跟 Decoder 的連接方式有更多的可能性,這邊是有待深入研究的題目~ 在此打住!
接下來來講怎麼訓練這樣的 Model

訓練資料前處理: 以中文語音辨識為例
把聲音訊號與對應的中文字答案資料整理好

Label 的格式:
以這張圖為例,當我們輸入聲音訊號,第一個字聲音送進去,以及 BEGIN 訊號送進 Decoder 的時候,我們最理想的狀況是產生 “機” 這個字對應的維度機率值為 1 其他字的機率值為 0 的一串 one-hot vector
訓練時的輸出:
我們希望輸出的機率分佈,跟Label答案的 one-hot vector 越接近越好
可以視為一種分類問題
假設我們資料中可辨識的中文字總共有 4000 個,可以想成每一次 decoder 在產生中文字的輸出就是在做 4000 類別的分類問題,用 cross entropy 來計算 loss
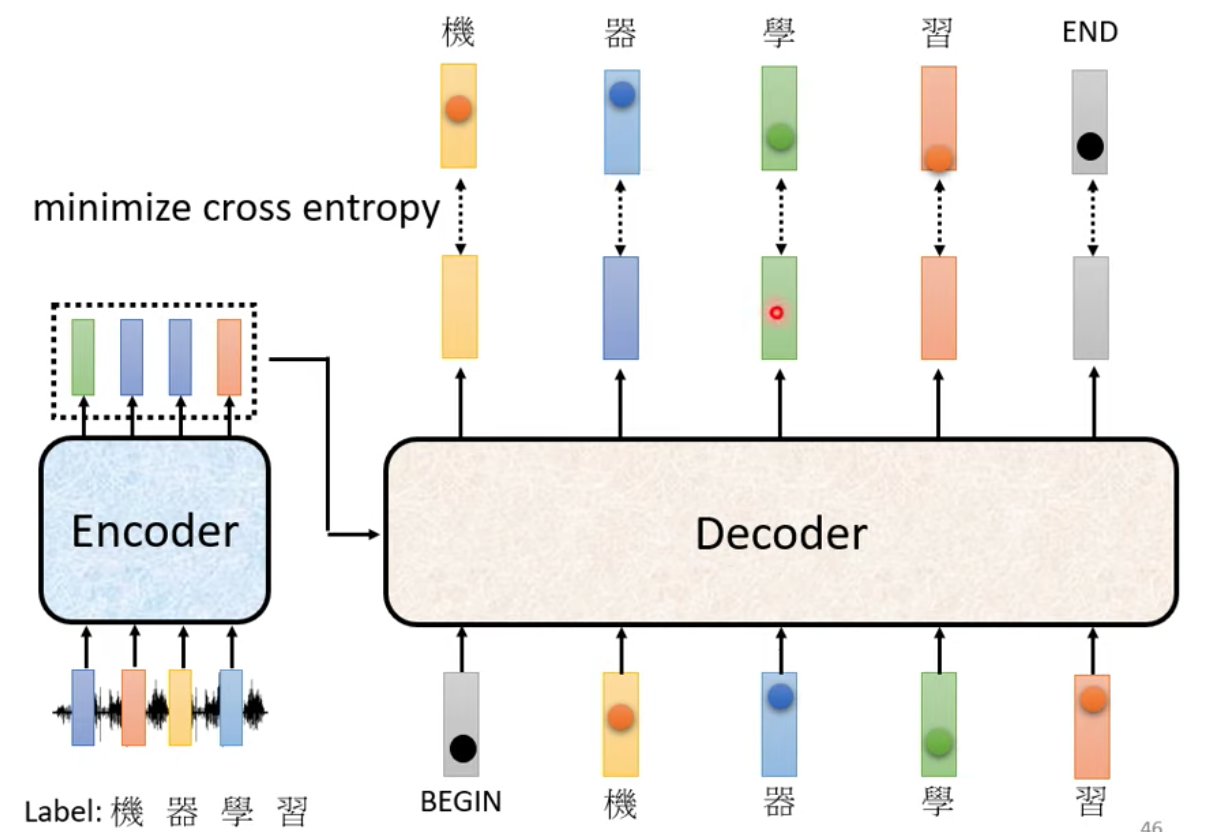
如圖, “機” “器” “學” “習” 這四個字的 output 總共做了四次分類問題,有四個 cross entropy 算出來的 loss 值,我們目標是讓 loss 的總和越小越好,但還有一個 END 別忘了!
要讓 Machine 知道在輸出完 “機” “器” “學” “習” 這四個字後,下一個要輸出跟 END 符號相對應的機率分佈
想想看 Decoder 的輸入是什麼?
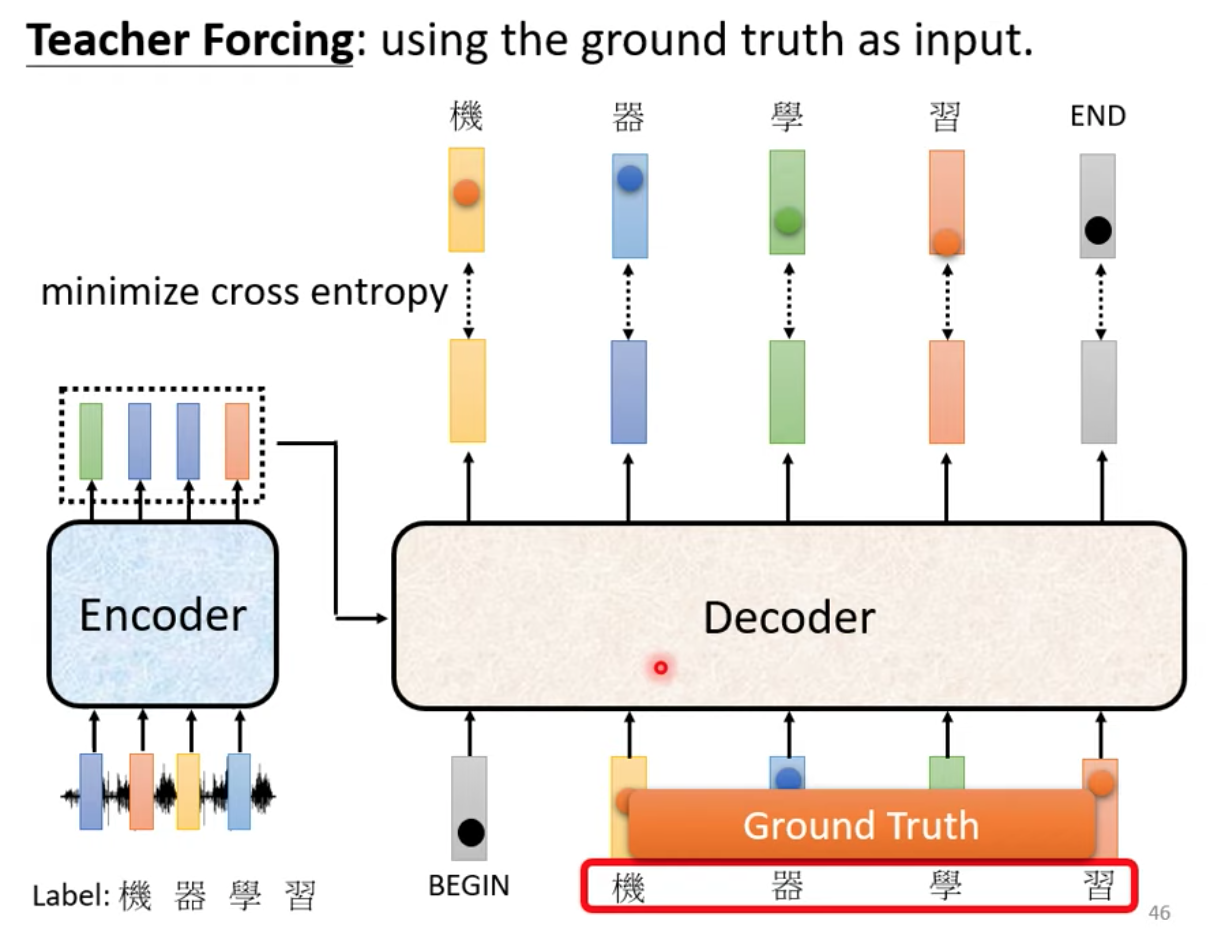
Decoder 的輸入是所謂的正確答案
我們會告訴機器說
當有 BEGIN 有 “機” 的情況下,要輸出 “器”
當有 BEGIN 有 “機” 跟 “器” 的情況下,要輸出 “學”
當有 BEGIN 有 “機” 跟 “器” 跟 “學” 的情況下,要輸出 “習”
當有 BEGIN 有 “機” 跟 “器” 跟 “學” 跟 “習” 的情況下,要輸出 END
訓練 Decoder 時,我們在輸入的時候給 Decoder 正確答案
這件事情叫做 Teacher Forcing,我們把正確答案當作 Decoder 的輸入
(此時可能會有個疑問:訓練時我們有正確答案可以用,但真的在測試時候沒有正確答案怎麼辦呢?這件事情之後來說明)
接著來討論 訓練這樣 seq2seq 的 Model 時的一些 Tips
Copy Mechanism
第一個是 Copy Mechanism
在目前的討論內容中,我們都要求 Decoder 自己產生 output 出來
但對很多任務而言,也許 Decoder 沒有必要自己創造 output 而是要從 input 裡面複製一些東西出來
想想在哪些任務會用得上呢?
其中一個例子是做聊天機器人

例如
User: 你好,我是庫洛洛
Machine: 庫洛洛你好,很高興認識你
對機器來說,沒有必要創造一個 “庫洛洛” 這個詞彙,而是要讓機器學習看到輸入時,我是 “某某某” 的時候,要把 “某某某” 複製一份,output “某某某” 你好
或者在做摘要的問題:
input 一篇文章
output 針對這篇文章的摘要
(要讓機器說出合理的句子,至少要上百萬篇文章以上)
當在做摘要的時候,很多的詞彙就是從原文裡面複製出來的
因此從文章裡面複製一些資訊出來,是一件很關鍵的能力

這件事情目前不細講,可以參考其他文章內容
Guided Attention
Guided Attention 要做的事情,就是要求機器在做 Attention 時要有固定的方式

在做語音合成或語音辨識的任務時,想像中的 Attention 是由左到右依序看
例如:機器要先看左邊的詞彙,產生聲音,在看中間的詞彙,產生聲音,最後看右邊的詞彙,產生聲音
但我們發現,機器的 attention 順序是顛三倒四的,顯然這樣的 attention 是有問題的
所以 Guided Attention 的機制要做的事情,就是強迫 Attention 要有固定的樣貌
這件事情的細節就留下關鍵字,日後再深入研究
Beam Search
舉個例子,假設我們decoder 只能產生兩個字 A 跟 B,我們每一次都在 A,B 中選一個輸出

每一次 Decoder 都選分數高的那個,第一次輸出 A 後,發現 B 分數比較高,
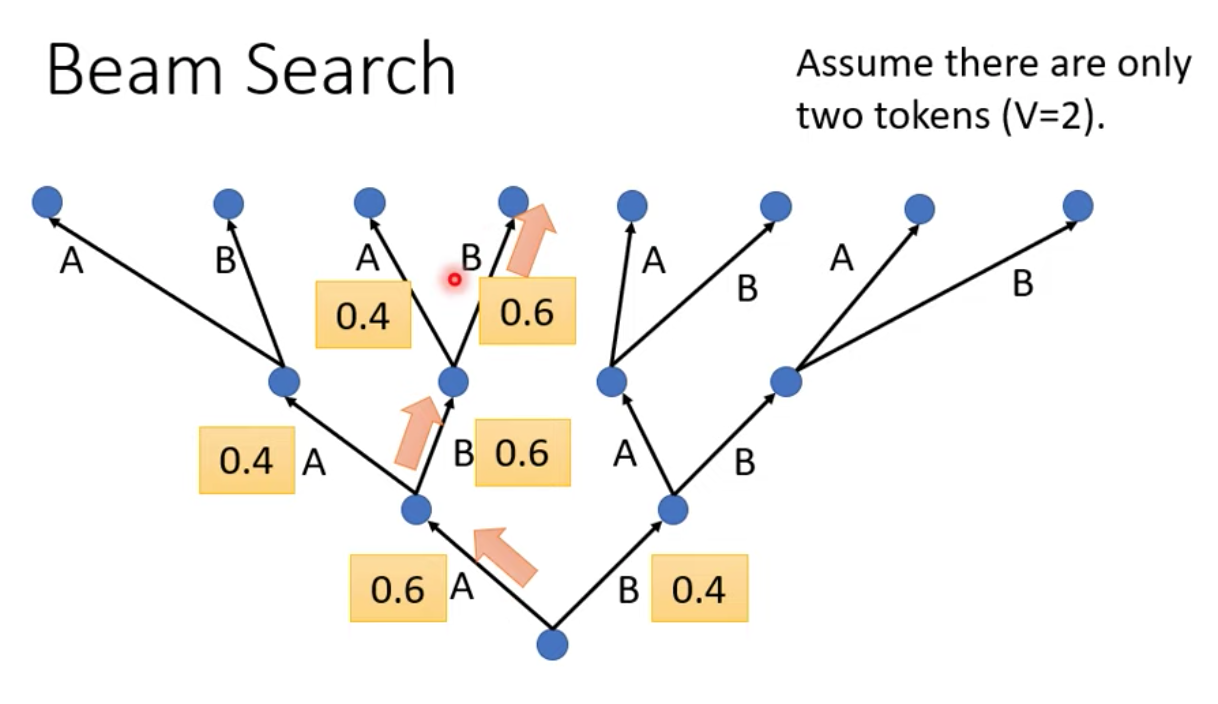
最後的輸出為 ABB,這種每次都選最高分的字當輸出這件事情,叫做 greedy decoding
但有沒有可能,我們在某步驟選了比較低的分數那條路,但後面的路得到的分數卻比原本的還要高分?
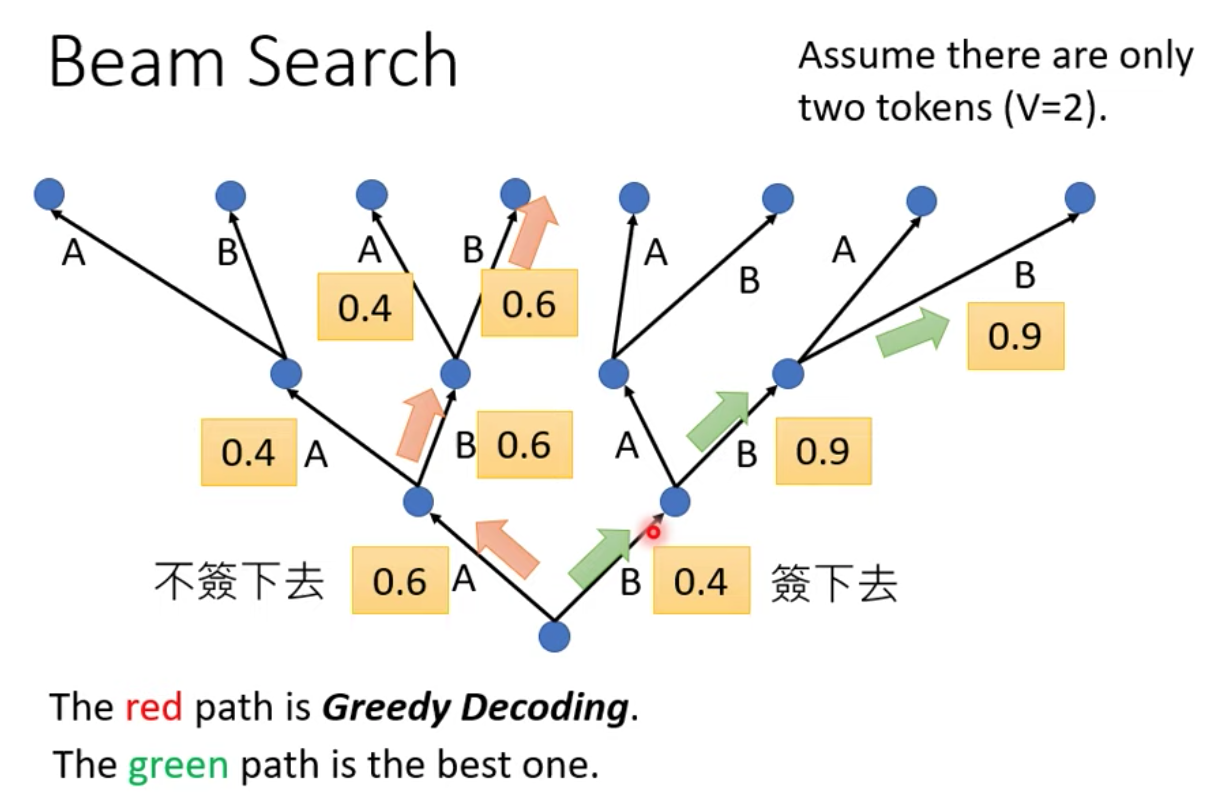
如圖中綠色這條路,雖然一開始我們選了比較差的輸出,但後面的路,分數卻超級好,最終的結果比紅色那條路還要好
我們要怎麼找到最好的路呢?
窮舉法:不可能 (假設我們有10萬個中文字要輸出,每次的選擇都是 10萬選一條走下去)
有個演算法叫做 Beam Search,有個估測的方法來找路,留給大家自行 google
BUT
Beam Search 這個技術有時候有用,有時候沒有用
有些文獻告訴你說 Beam Search 是個很爛的東西

例如圖中使用 Beam Search 的 output 出現不段說同一句話鬼打牆的情況
對於答案明確的任務中,Beam Search 比較有幫助
當你需要機器發揮創造力時,不是只有一個答案的任務時,需要在 decoder 裡面加入隨機性,例如這種 sentence completion 任務,就不太適合使用 Beam Search
做語音合成 (TTS) 的任務時, decoder 端居然要加 noise 反而會得到好結果
Decoder 找到最好的結果,不見得是人類覺得最好的結果...
Optimizing Evaluation Metric
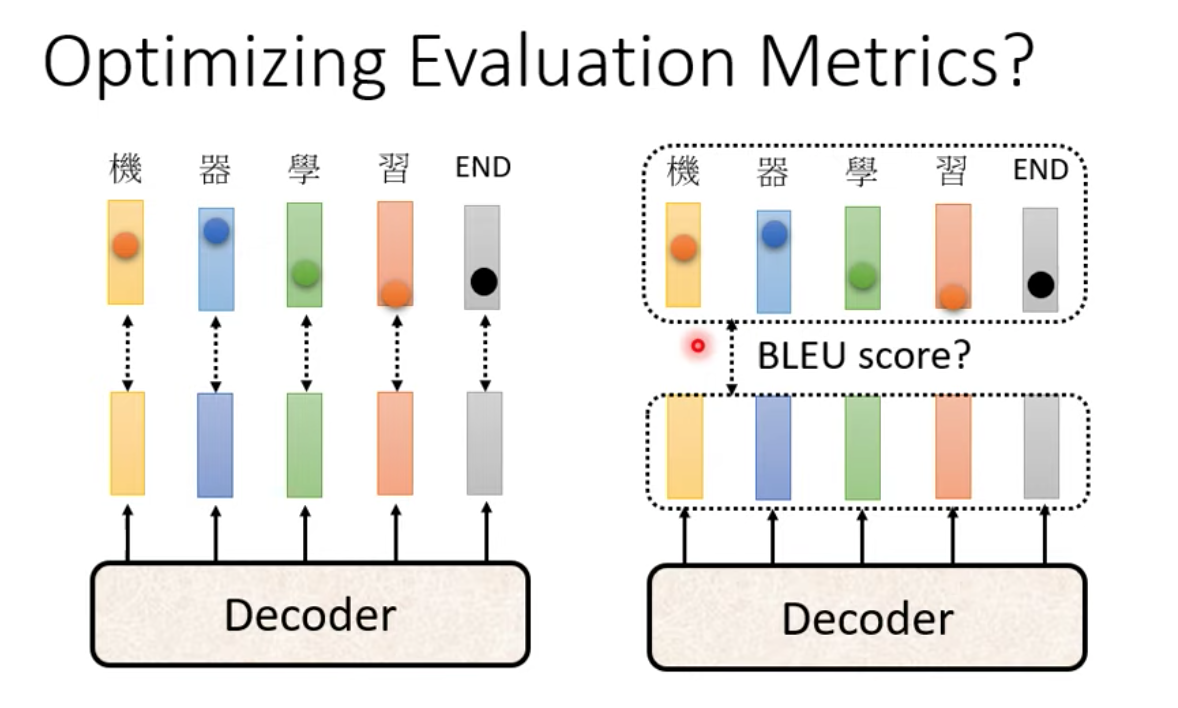
BLEU score 拿兩個句子做比較算出相似分數
訓練時:看 cross entropy loss 最小的
測試時:看 BLEU score 最高分的
training 時 cross entropy 最低的 model 得到的 BLEU score 不見得是最高分的
因此在 validation 時,要用 BELU score 來看模型好壞
那有沒有辦法用 BLEU score 用在訓練呢?
沒這麼容易,因為 BLEU score 本身很複雜,是不可微分,無法去算 gradient decent
該怎麼辦呢?
遇到你無法 Optimize 的 loss function 時
可以把它當作 RL 的 reward ,把你的 decoder 當作是 agent 硬做,有可能得到更好的方法
這招是比較進階的,不一定推薦
Exposure Bias
訓練時 decoder 永遠都看正確的東西
測試時,看到錯誤的東西時,造成一步錯步步錯

有一個思考方向是,訓練時偶爾給 decoder 的輸入加一些錯誤的東西,它反而學得更好
這招叫做 Scheduled Sampling
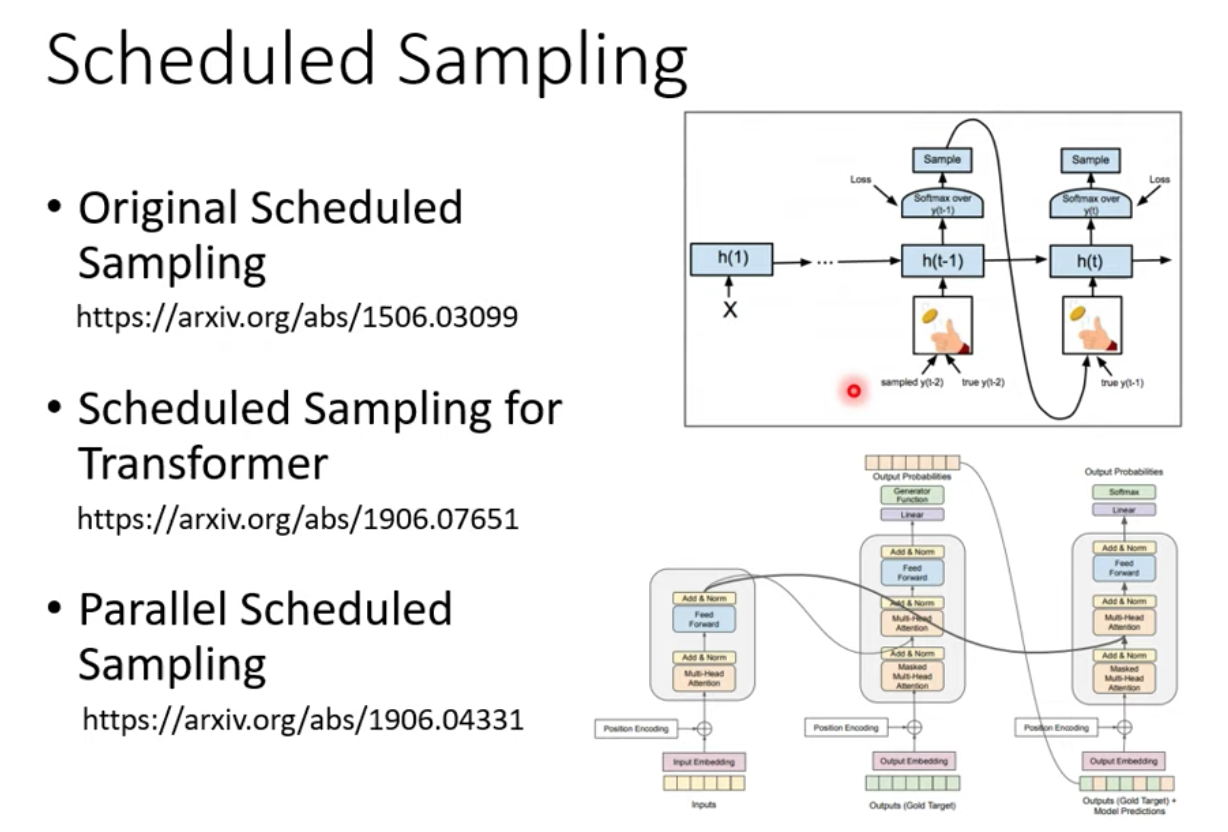
詳細就追 paper 囉
相關文章整理






留言
張貼留言