[ML筆記] Recurrent Neural Network (RNN) - Part II
ML Lecture 26: Recurrent Neural Network (Part II)
本篇為台大電機系李宏毅老師 Machine Learning (2016) 課程筆記
上課影片:
https://www.youtube.com/watch?v=rTqmWlnwz_0
課程網 (投影片出處):
http://speech.ee.ntu.edu.tw/~tlkagk/courses_ML16.html
上課影片:
https://www.youtube.com/watch?v=rTqmWlnwz_0
課程網 (投影片出處):
http://speech.ee.ntu.edu.tw/~tlkagk/courses_ML16.html
接著來探討 RNN 如何 training
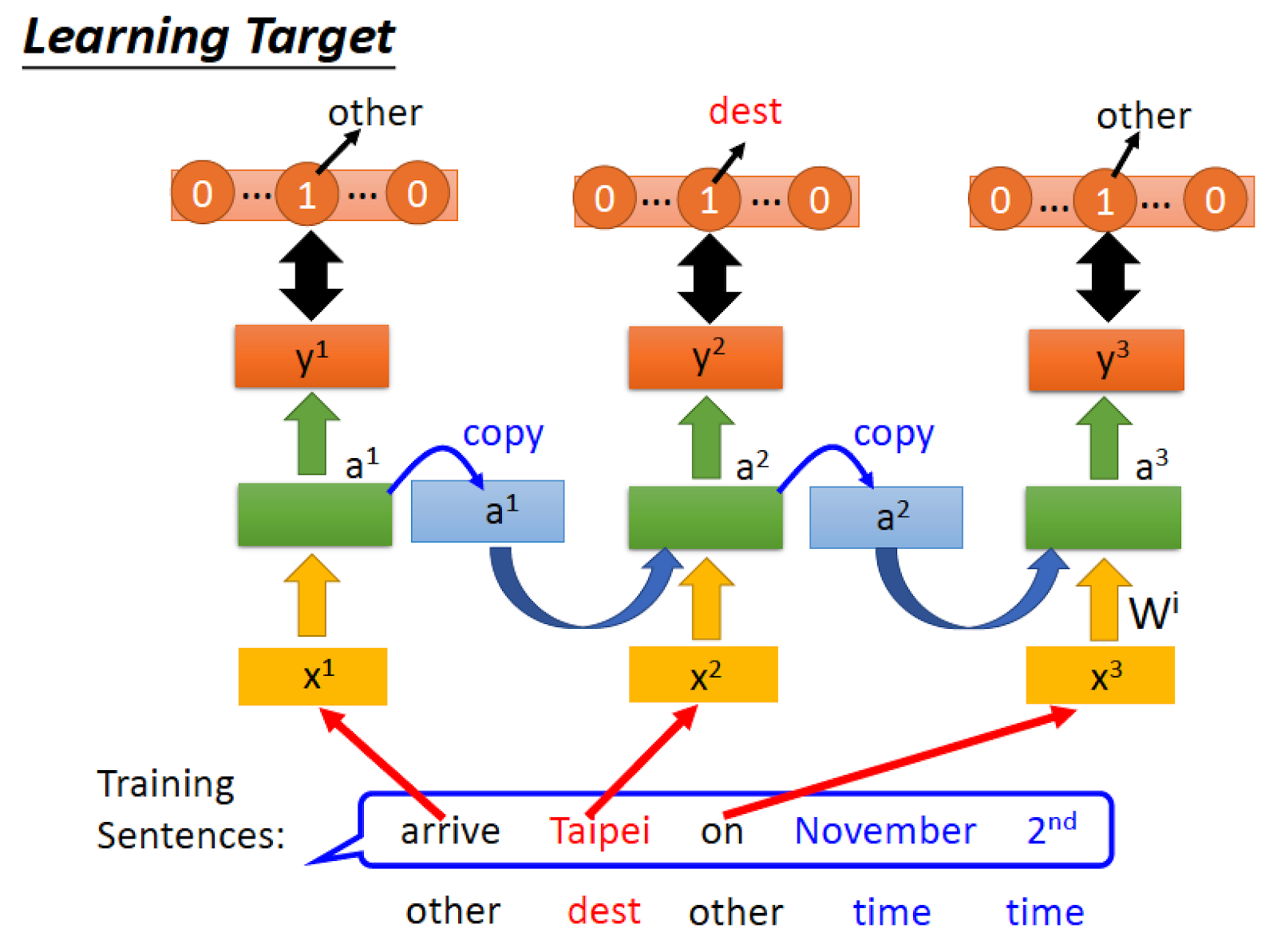
我們的 training data 假設是一句 sentence
cost function要如何定呢?
針對 input 句子的每一個單字,透過 RNN 分別輸出 output y 比對我們人工標記好的 label
注意事項: input 句子順序要正確,也就是丟 x1 後才能丟 x2
Cost 就是每一個時間點的 output 跟答案 vector 之間的 cross entropy 的和!
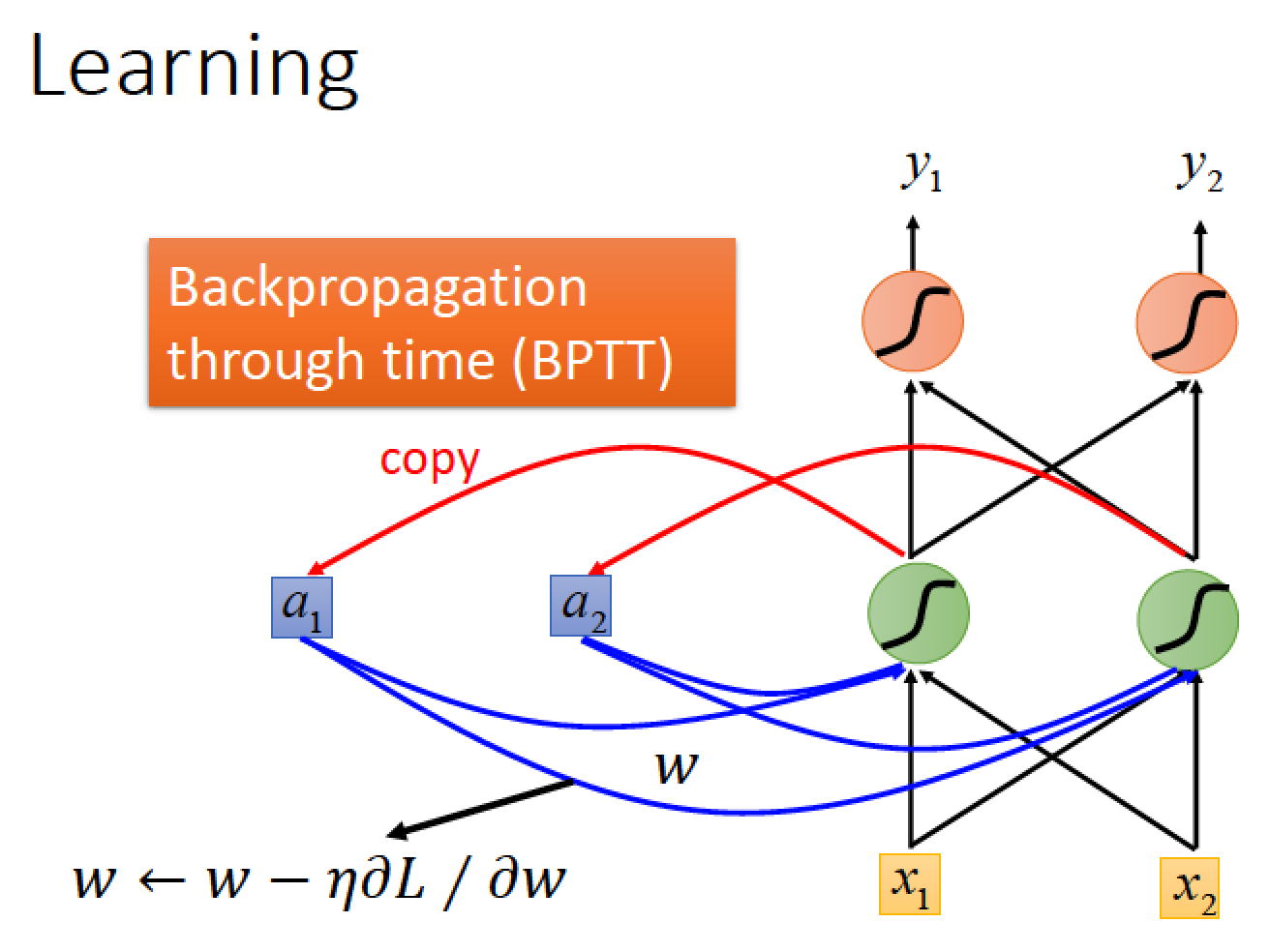
Train 參數的方法: gradient descent 搭配進階版版的 Backpropogation through time (BPTT)
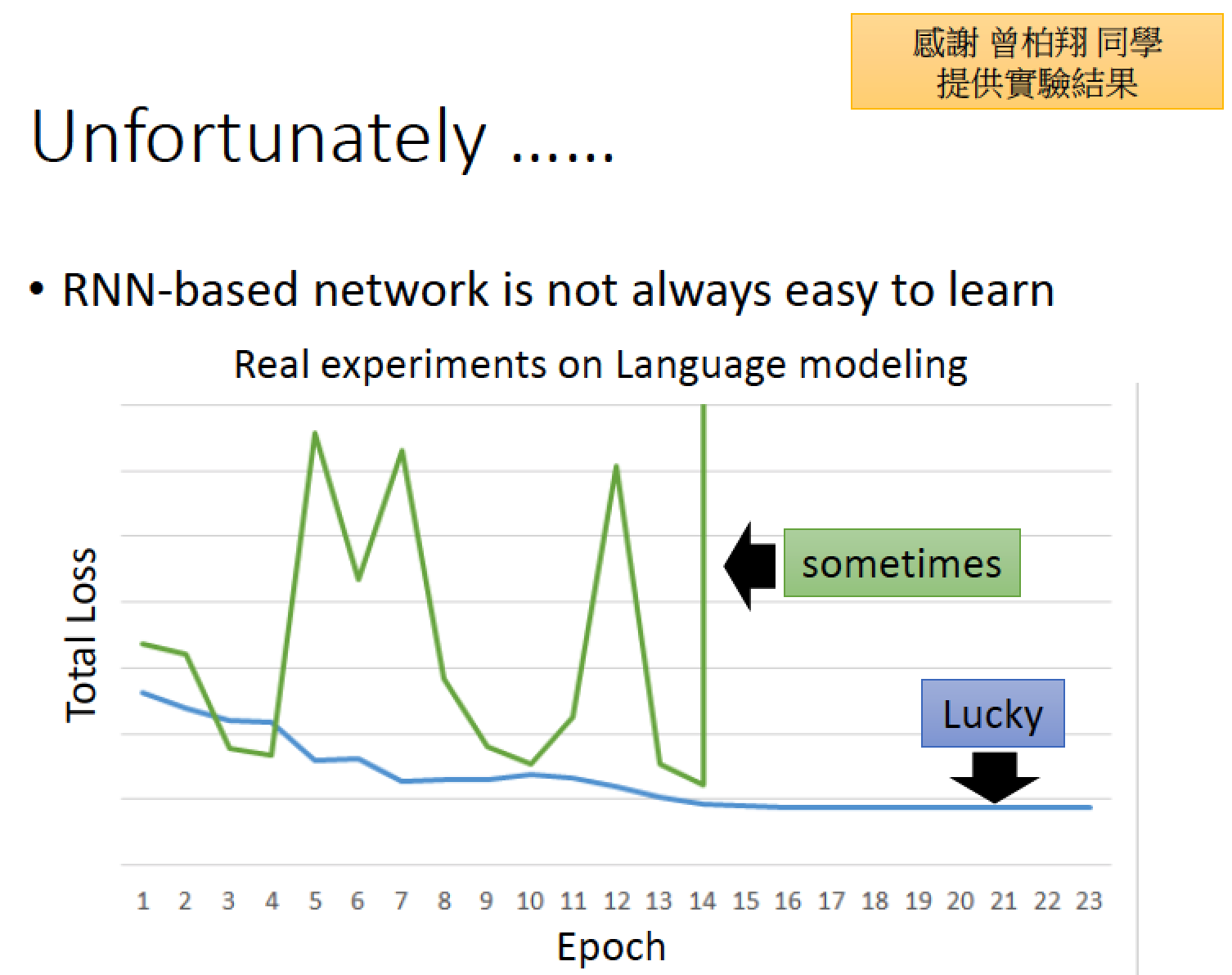
不幸的是,RNN 非常難 Train
RNN 的 “Error surface” 也就是Total Loss 對於參數的變化,有些地方非常平坦,
但有些地方則是非常陡峭,造成可能在更新參數時,恰好跳過懸崖,發生 loss 劇烈暴增,劇烈震盪的情況
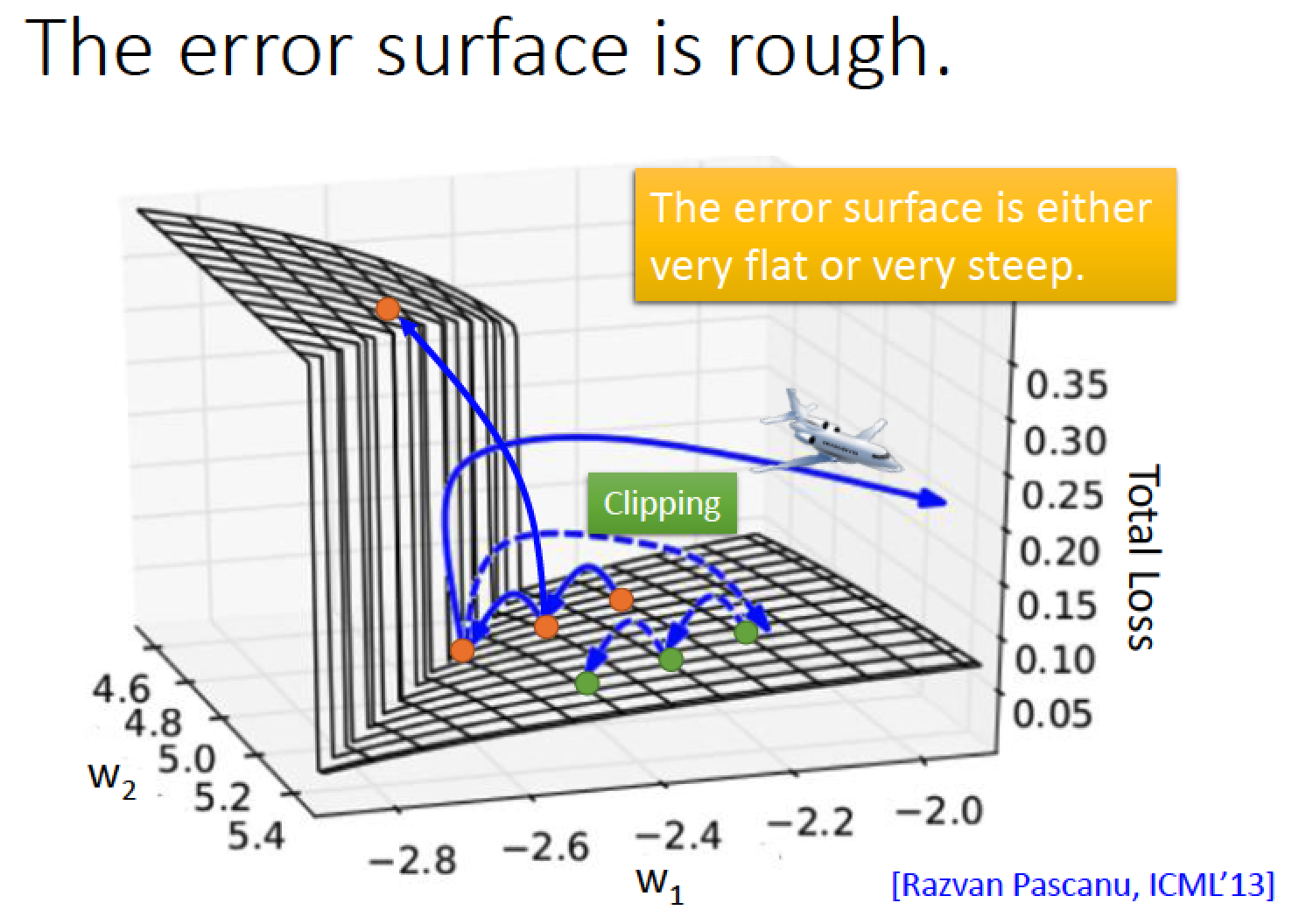
在很平坦的區域 learning rate 漸漸調的比較大,如果不幸剛好不小心一腳踩在懸崖峭壁上,
很大的 gradient 乘上很大的 learning rate 參數就會 update 很多,參數就飛出去了
解決方法:Clipping 當 gradient 大於某一個 threshold 時,就把它限制在那個 threshold
所以現在 gradient 不會過大,參數只會飛到比較近的地方,限制住參數更新大小不飛出去
至於為什麼 RNN 會有這樣的特性呢?
來看下面這個例子
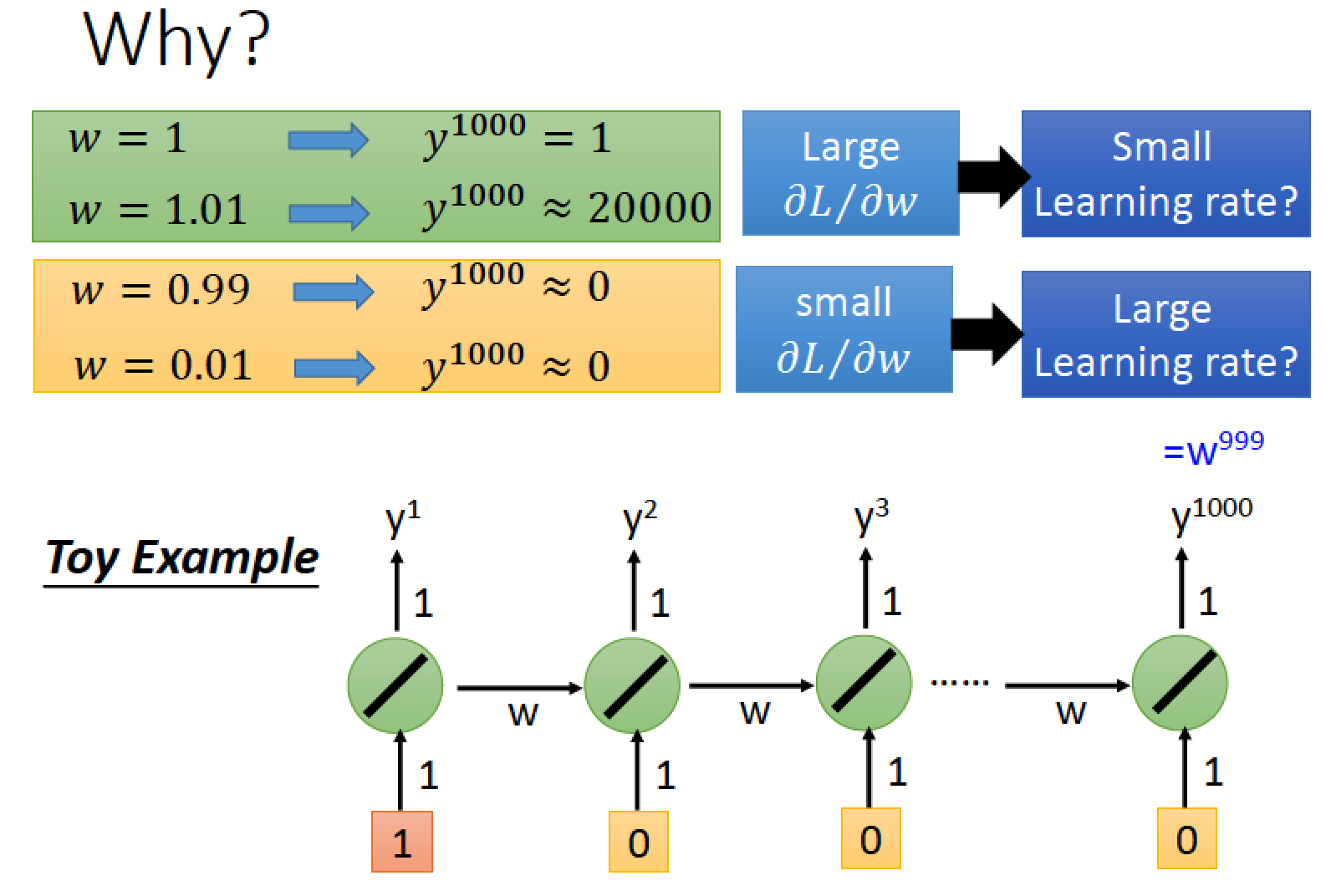
假設我們有一個最簡單的 RNN 只有一個 Neuron with linear function
Network 的 input output weight 都是 1
transition 的 weight 是 w
如果我們給 Network 的輸入是 1, 0, 0, 0, …, 0
那我們在最後一個時間點 1000 處的 output 會長怎樣呢?
它的值會是 w999 次方
如果 w = 1 則最後一個時間點的 output 也是 1
如果 w = 1.01 則最後的 output 暴增到 20000 左右 ,意即 w 有一點小小的變化,對 output 影響很大,
所以 w 有很大的 gradient,則我們會把他的 learning rate 設為小一點來因應。
BUT
如果 w = 0.99 則最後的 output 會接近 0
如果 w = 0.01 則最後的 output 也是 0
意即 w 在 1 這個地方有很大的 gradiant,但是在 0.99 這個位置 gradiant 突然變得很小很小
因此 gradient 時大時小,在非常短的區域內,gradient 的變化很大,error surface 很崎嶇
由以上例子可以看出,為什麼 RNN 會有問題,w 在 0~0.99 之間的變化,造成最後的結果沒有影響,
但是 w 超過 1 後,一但有影響,就是天崩地裂等級的影響
“w 只要一小變化,可能完全沒有造成影響,但只要有造成影響,就是巨大的影響”
那有什麼樣的技巧可以幫助我們解決這個問題呢?
目前最被廣泛使用的技巧就是 LSTM

問:為什麼我們把 RNN 換成 LSTM ?
答:因為 LSTM 可以處理 Gradient Vanishing 的問題
問:Why LSTM can handle gradient vanishing ?
答:RNN 跟 LSTM 在面對 memory 的處理上相當不同
在普通的 RNN 架構中,每一個時間點 Memory 裡面的值都會被洗掉覆蓋掉,所以影響就消失了,
但是 LSTM 的做法是把原本 Memoy 裡面的值乘上一個值,
再跟 input 是相加的,所以一但有一個值被存進 Memory 造成影響,
這的影響就會被永遠的留著,除非 forget gate 把 memory 洗掉,
否則影響會永遠留著,所以不會有 gradient vanishing 的問題。
→ Forget Gate 在多數的情況下,要保持開啟(不忘記)
只有少數情況下, forget gate 關閉,把 memory 裡面的值洗掉
Gate Recurrent Unit (GRU) 只有兩個 Gate,需要的參數量比較少,
所以在 training 時比較好訓練,他會把 input gate 跟 forget gate 連動,
也就是要把存在 memory 裡面的值清掉,才能把新的值存進來 “舊的不去,新的不來”!
其他可以解決 gradiant vanishing 問題的 RNN

Hinton 提出一個有趣方法:
使用一般的 RNN (不用 LSTM)且使用 Identity matrix 來 initailize transition weight matrix 時,
再搭配 ReLU 的 activation function ,會有比較好的 performance
以往如果我們用 random initial weight 的話,使用 sigmoid function 會比較好
但是如果我們用 Identity matrix 來 initialize weight,則使用 ReLU 會比較好
RNN 的其他 application
在 slot filing 的問題中 input 跟 output 數量是一樣的
但 RNN 實際上還可以做更複雜的事情


input 一個 character sequence
output 對於整句的理解分類,例如好雷負雷

給 machine 一篇文章,然後自動找出這篇文章中有哪些關鍵詞彙
RNN 把 document word sequence 當作 input 把文章看過一次
把出現在最後一個時間點的 output 拿出來做 atention 丟進 feedforward network 裡面
得到最後的 output
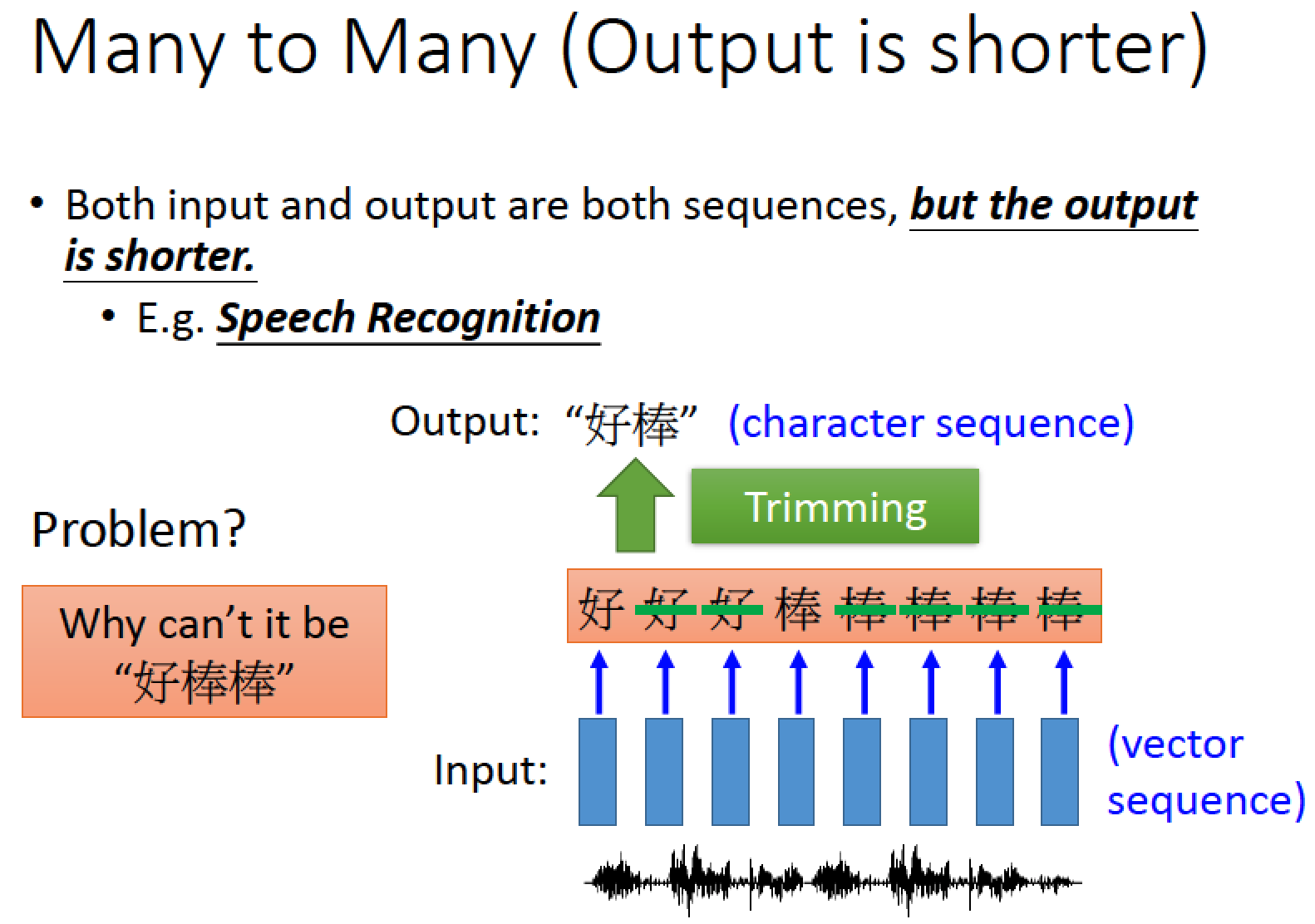
語音辨識
input 一長串語音訊號,每隔 0.1 秒取樣一次
output 一串較短的訊息 character sequence 經過 triming 把重複的東西刪掉可以得到訊息
但這樣的作法無法把 “好棒” 跟 “好棒棒” 分開來
怎麼辦呢?
有一招叫做 CTC
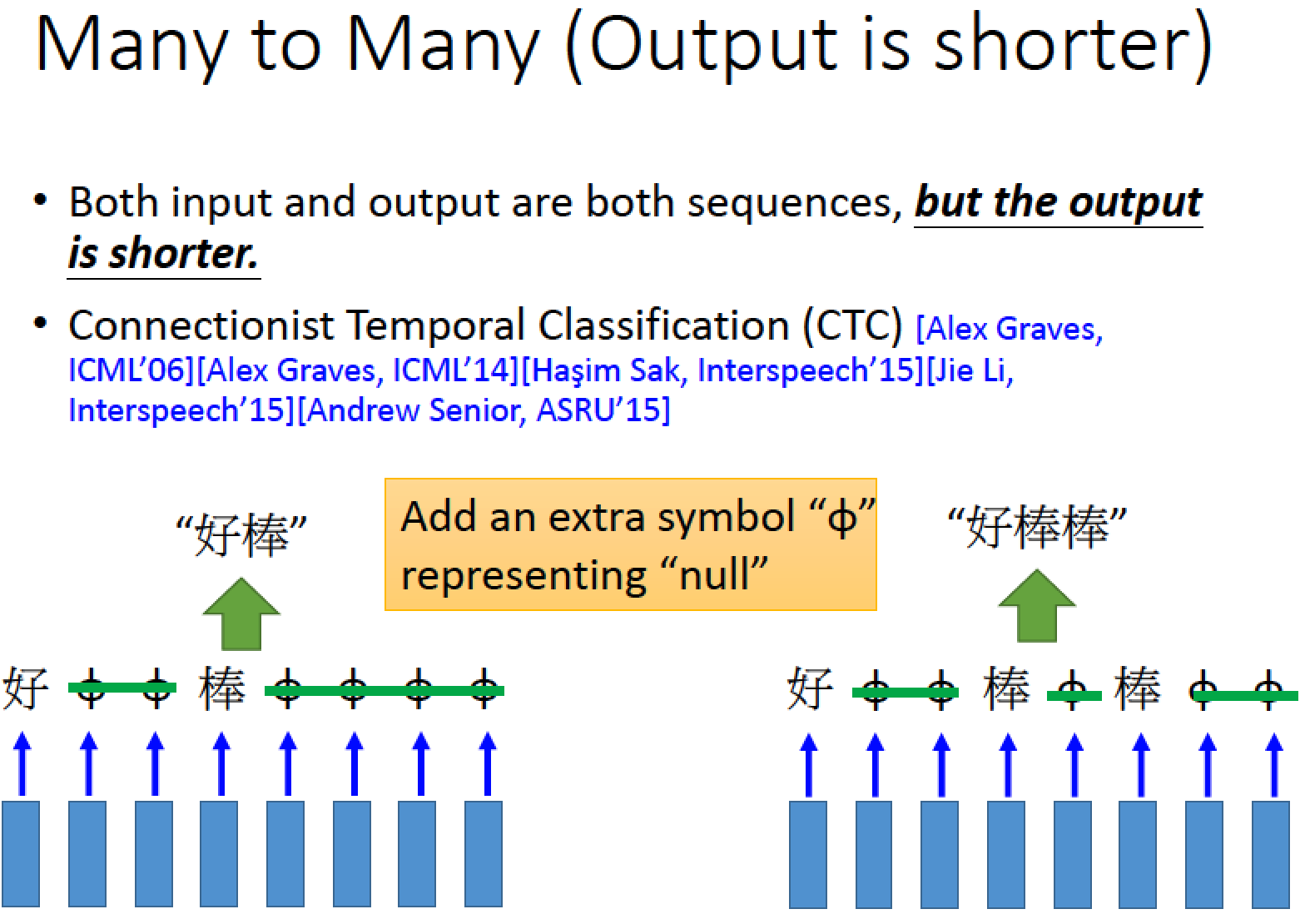
output 除了中文字以外,再增加一個新的符號 NULL ,這樣就可以解決疊字的問題了!
CTC 怎麼 training 呢?

窮舉所有可能的 文字與 NULL 之間的排列組合,全部都當作正確的下去 train 再看我們的語音訊號屬於哪一個類別!
以下是文獻上 CTC 得到的結果
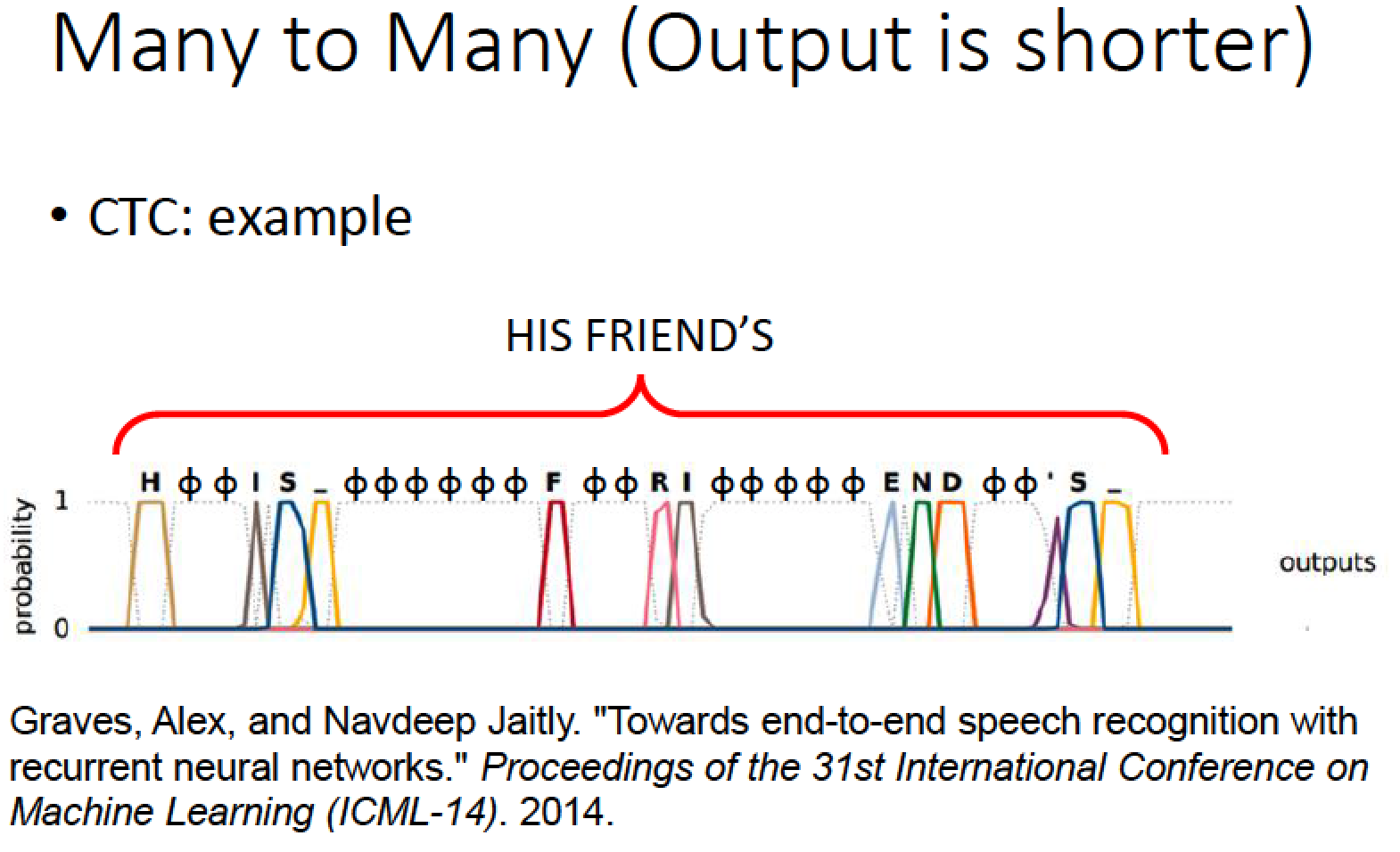
英文辨識上,RNN output 的目標就是字母,空白,還有 NULL
字跟字之間的 bundary 自動用空白區隔
上圖中每個 frame 的 output 把 NULL 的部分拿掉,這句話辨識的結果就是 HIS FRIEND’S
不需要告訴 machine HIS 是一個詞彙 FRIEND’S 是一個詞彙,machine 透過 training data 會自動學到這件事情
另一個神奇的 RNN 應用為 Sequen to sequence learning
剛剛的 CTC 的例子是 input 比較長 output 比較短
而 Sequen to sequence learning 則是不限制 input 跟 output sequence 的長度
最常見的應用就是翻譯,英文跟中文講同一句話,不能確定哪個語言會比較長
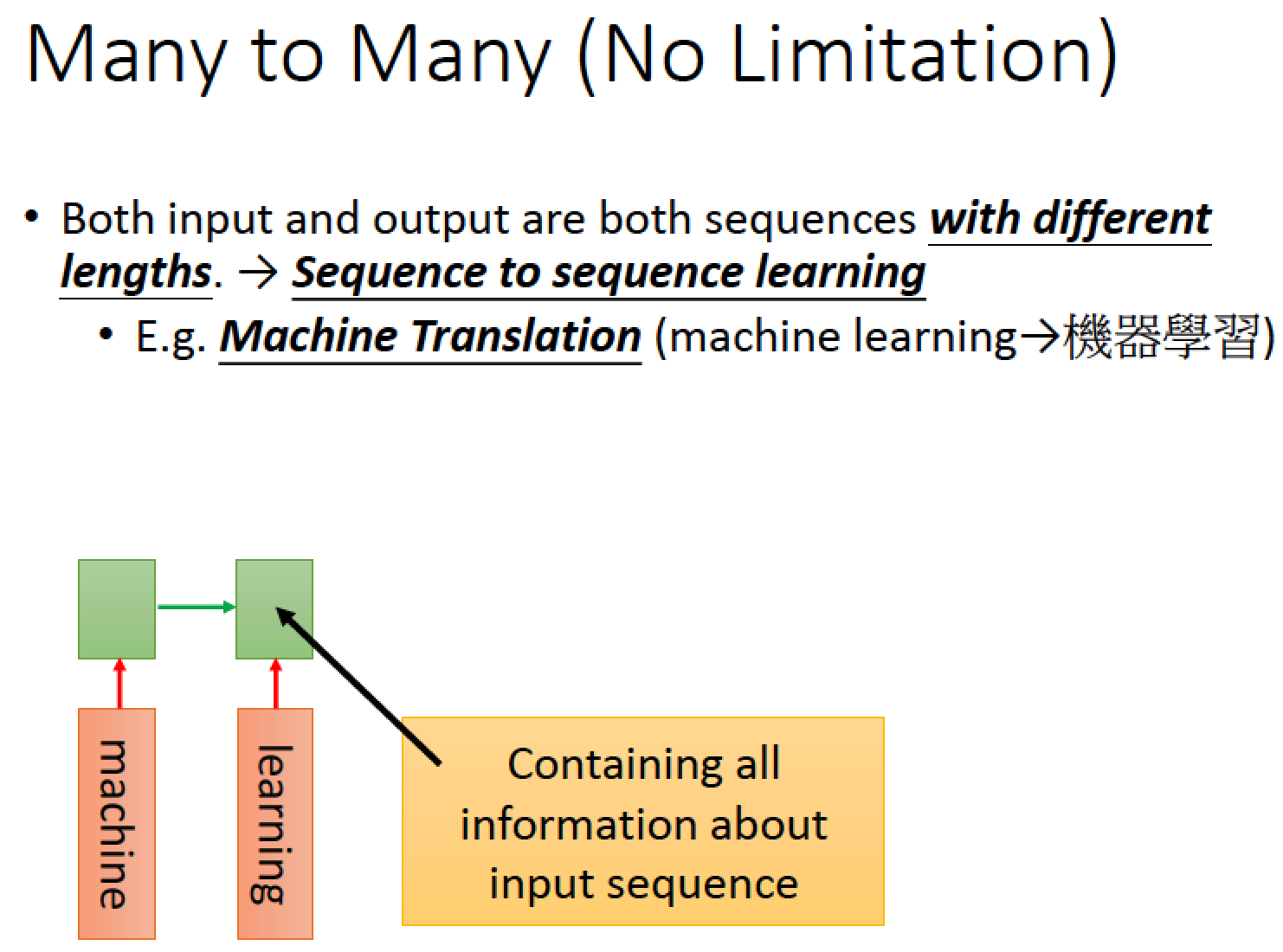
假如 input 是 “machine learing” 用 RNN 讀過一遍,想要把它翻譯成中文
RNN 讀過一遍,最後一個時間點的 memory 存了整個 input seqnece 的 infomation
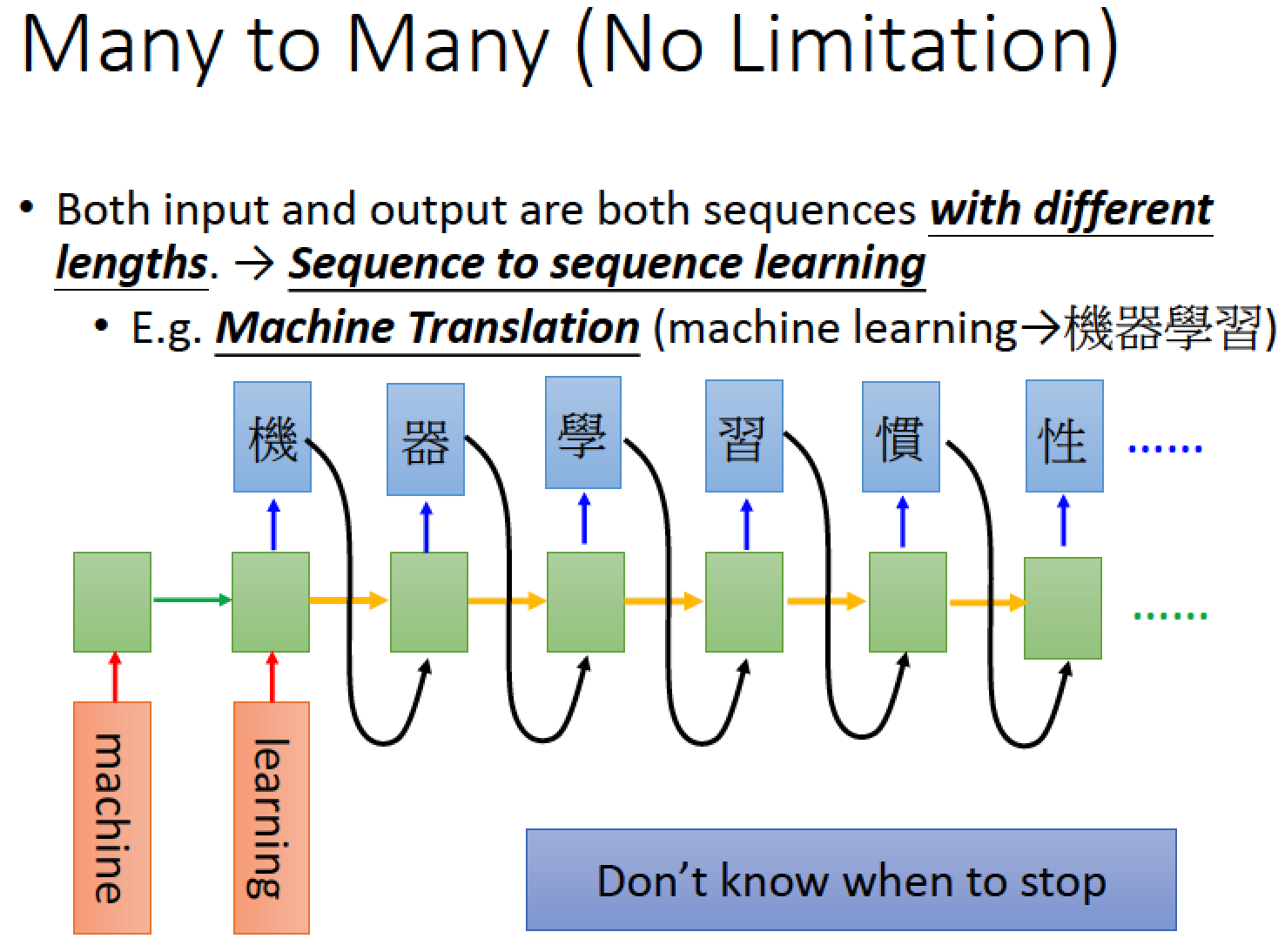
接下來讓 machine 吐出一個 character,第一個 output 是 “機”
再叫他 output 下一個 character ,他會 output “器” 詳細內容與技巧之後再講
這樣 output 下去有可能無限接龍下去,不知什麼時候會停止
PTT 推文接龍中,大家會接前一個人的字,直到有一個人推文 ===== 斷 ===== 才會停下來

所以同樣的技巧用上,再增加一個 character 代表 “斷”
讓 machine 一看到斷就停下來
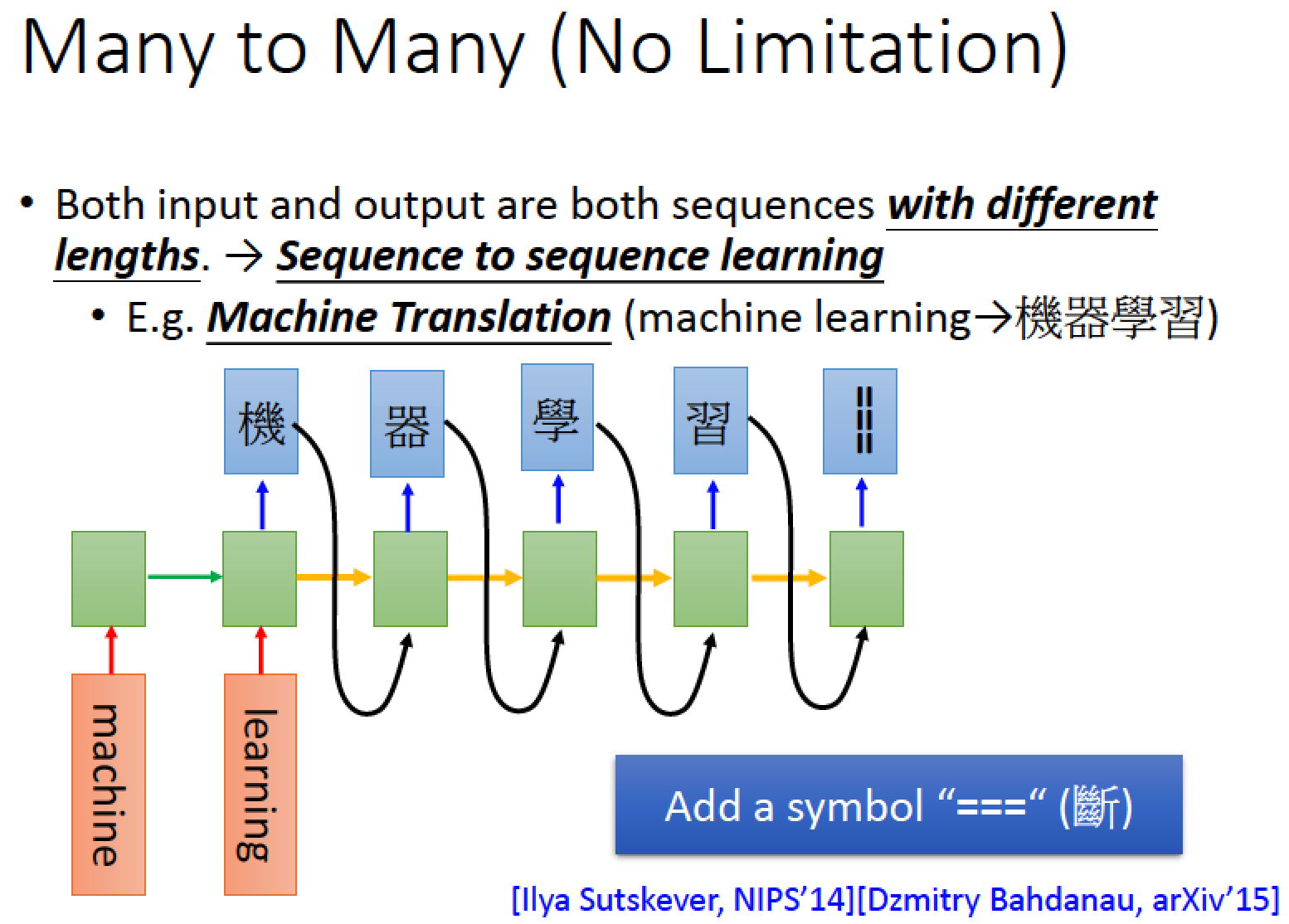
神奇的是,這樣的方法可以 train 的起來
雖然效果沒有 CTC 好,但也很好用!
Sequence to sequence learning

直接把一句英文語音訊號,翻譯成中文的文字!
作法:直接把英文聲音訊號以及對應的中文翻譯拿下去 train
居然 train 的起來,成功可以用!
知道這樣的技術可以成功的話,可以應用在一些特定方言,沒有完整的文字系統的語言上,
例如我們可以把台語的聲音訊號,跟對應的英文翻譯搜集起來,就可以 train 了,
不需要先知道台語的語音訊號轉文字後才翻譯。
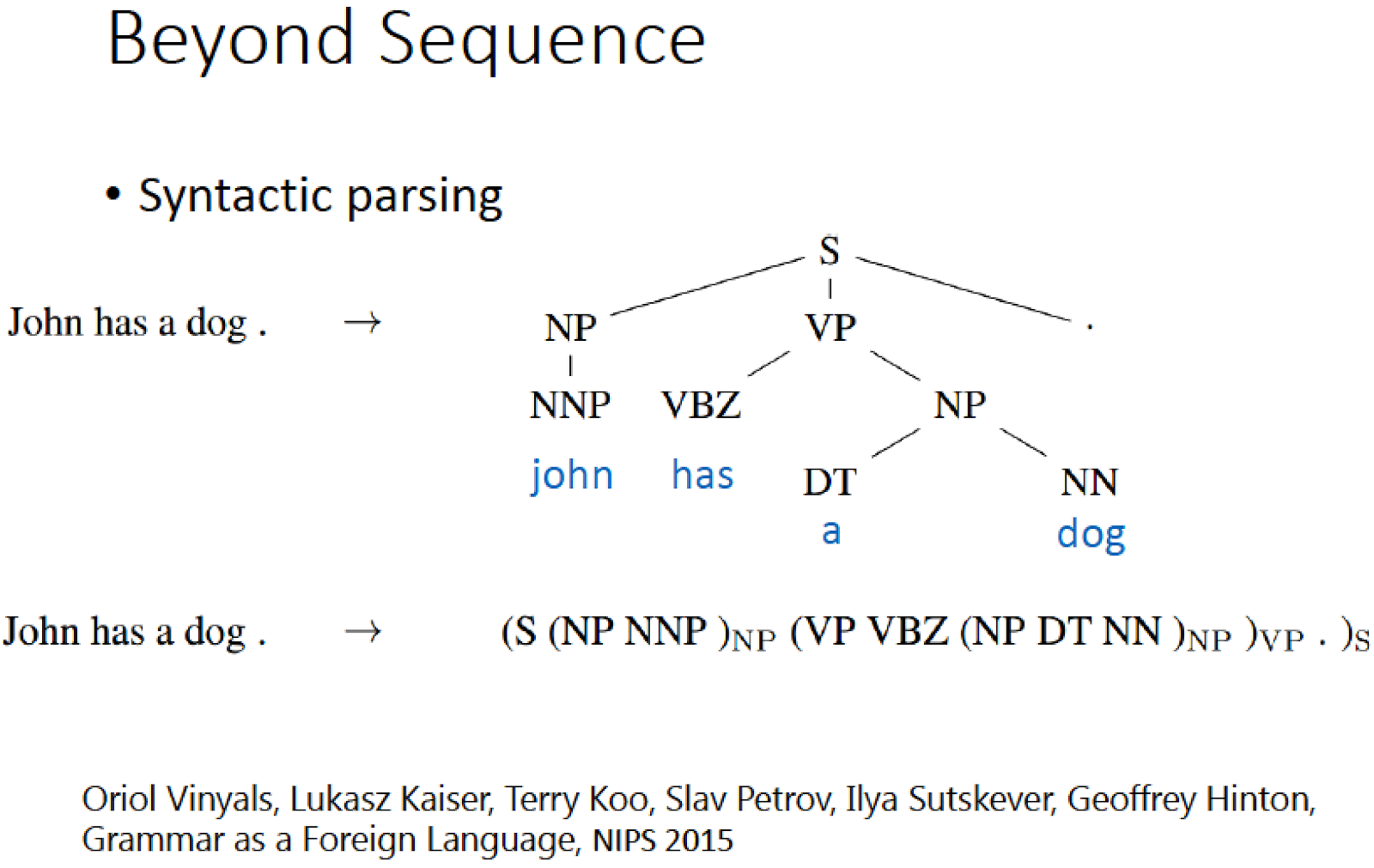
Syntactic parsing tree : 讓 machine 看一個句子,得到文法的結構樹
方法: 把樹狀圖描述成一個 sequence 例如 (S (NP NNP) … ) 然後丟下去 train 可以 train 起來

兩段句子 bag-of-word 詞彙完全一樣,但是順序不一樣,得出來的意思截然不同
可以用 sequence-to-sequence auto-encoder 方法,在有考慮順序的情況下,
把一個 document 變成一個 sequence
做法:
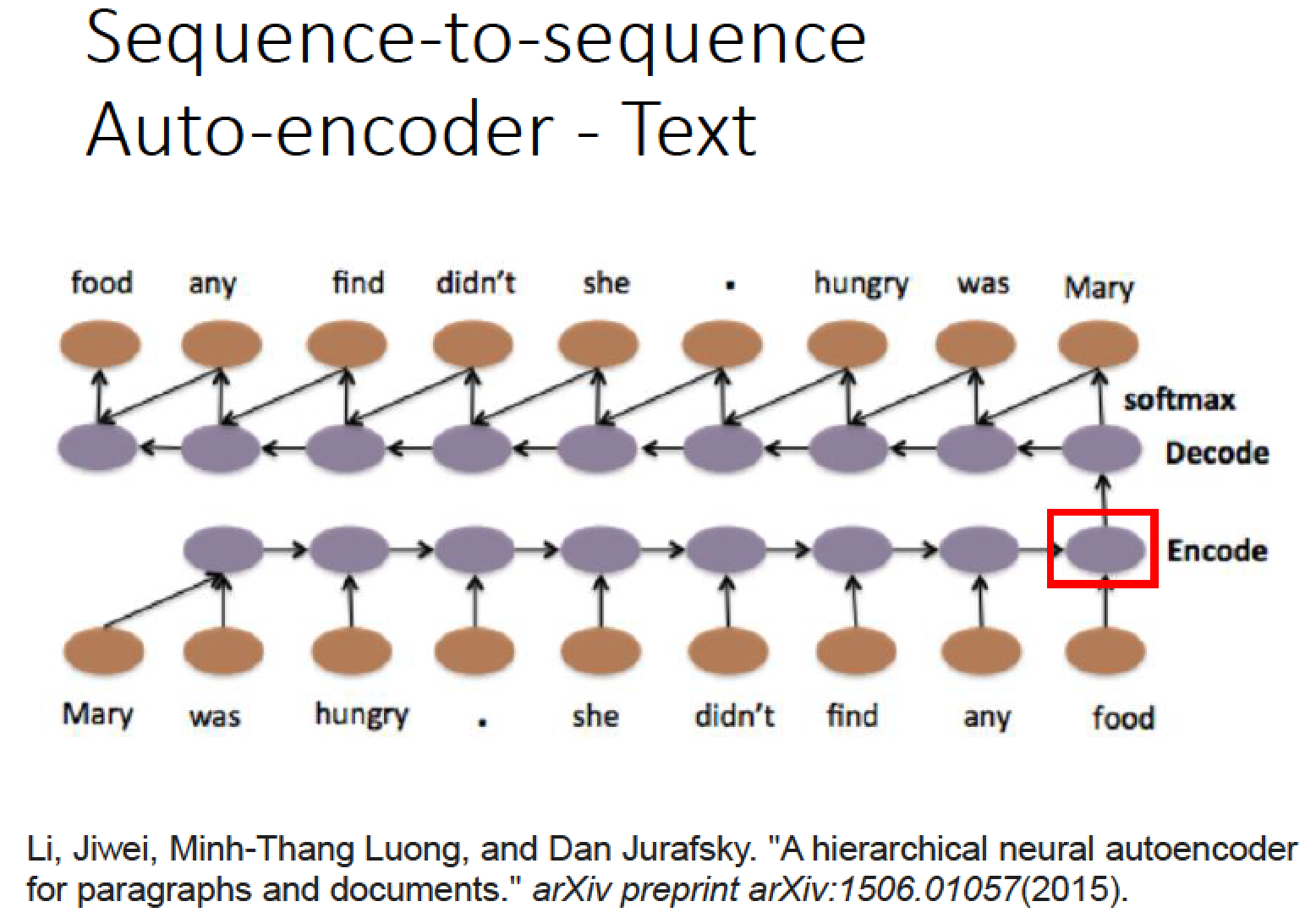
我們 input word sequence 通過 RNN 把它變成一個 encoded vector 當作 Encoder 的輸入
再讓 Decoder 根據 Encoder 的訊號,長回原貌,一模一樣的句子。
如果 RNN 可以做到這件事情的話,代表 encoded vector 可以代表 input sequnece 裡面的重要資訊,
根據這個技術,我們不需要 label data 只需要搜集大量文章,然後 train 下去就好了
這樣的結構也可以是 hierarchy 的
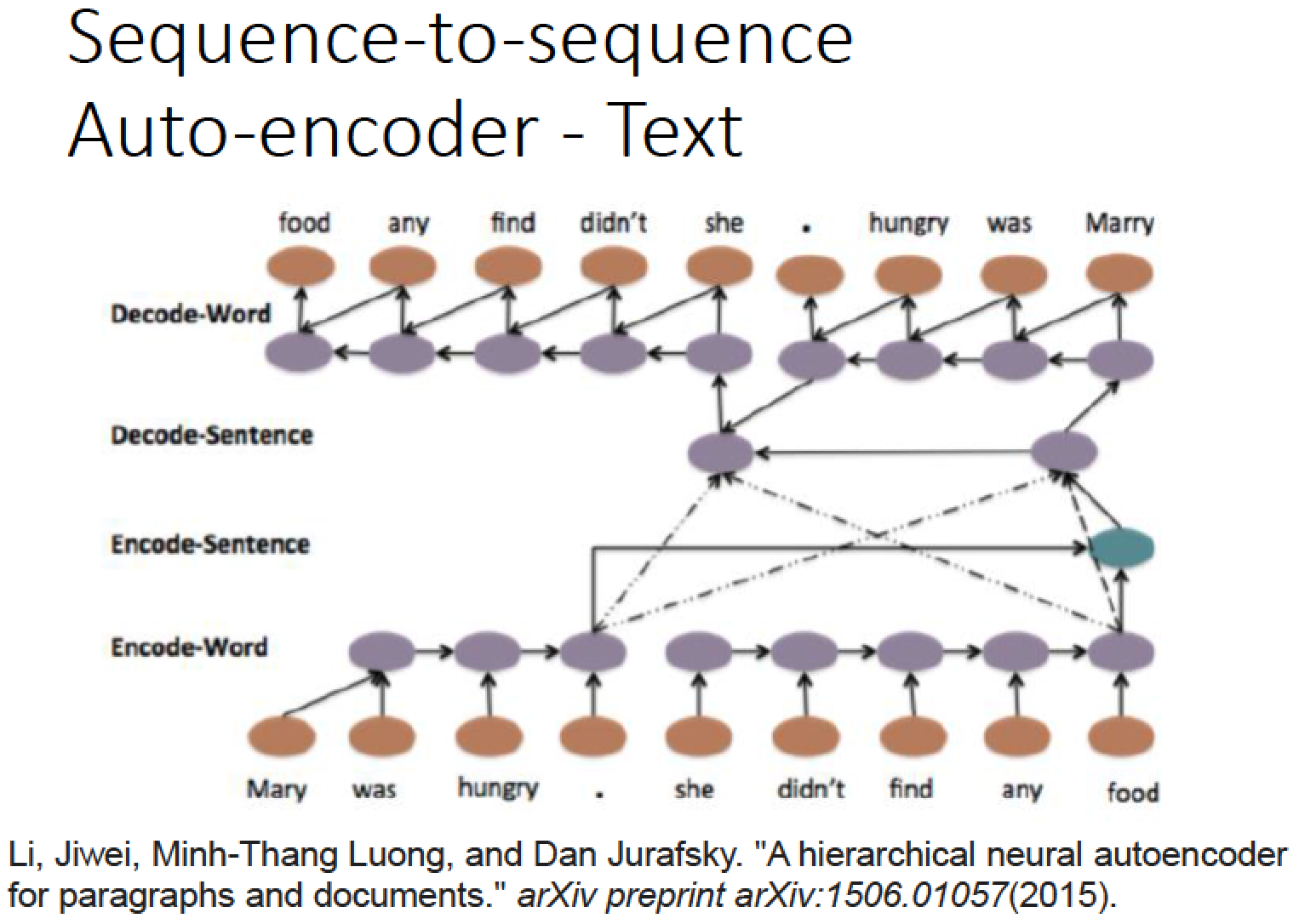
可以每一個句子都先得到一個 vector
再把這些 vector 加起來,變成一個整個 document 的 high level 的 vector
再把這個整合後的 high level vector 去產生一串串 sentence vector
再根據 sentence vector 再解回 word vector
這樣的架構也是可以 train 的

除了用在文字上以外,也可以用在語音上
可以把一段 audio segment 變成一段 fixed-length 的 vector, 可以視為 audio 的 word-to-vector
應用:
可以拿來做語音的搜尋
例如我們有一個聲音的 database 例如上課的錄影錄音,然後說一句話,
可以直接比對聲音訊號的相似度,查詢相關的內容
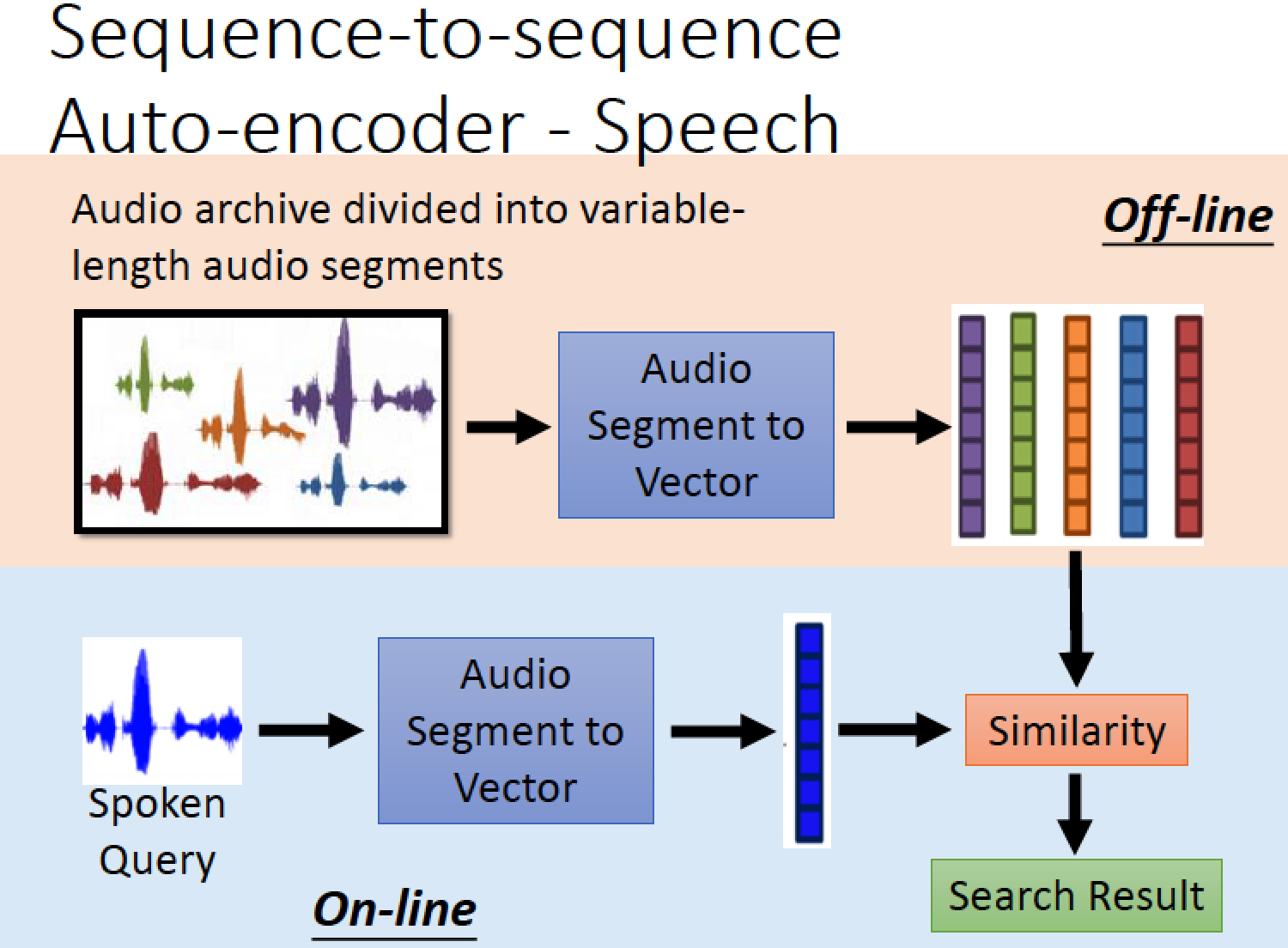
把 database 裡面的聲音訊號切成一段一段,再把 audio segment 拿去用 RNN 變成 vector
根據 vector 的相似度比對計算,得到搜尋結果
如何把 audio segment 變成 vector 呢?
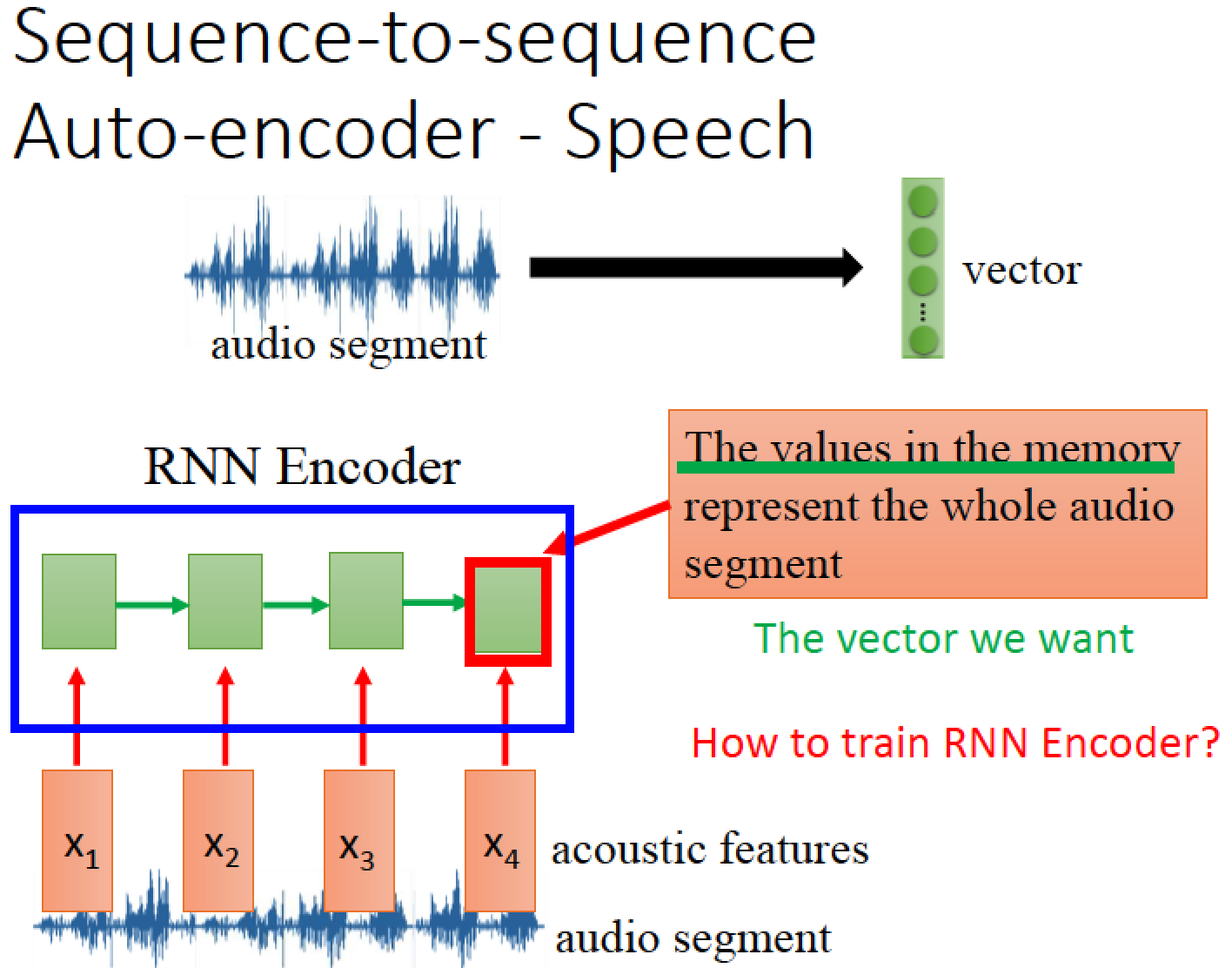
把聲音訊號先抽成 acoustic feature sequence ,再丟進 RNN 裡面去
RNN 讀過 acoustic feature sequence 後,他在最後一個時間點,存在 memory 裡面的值
就代表了整串聲音訊號的訊息
以上這個 RNN 扮演一個 Encoder 的角色
除了 Encoder 之外,我們還需要 Decoder
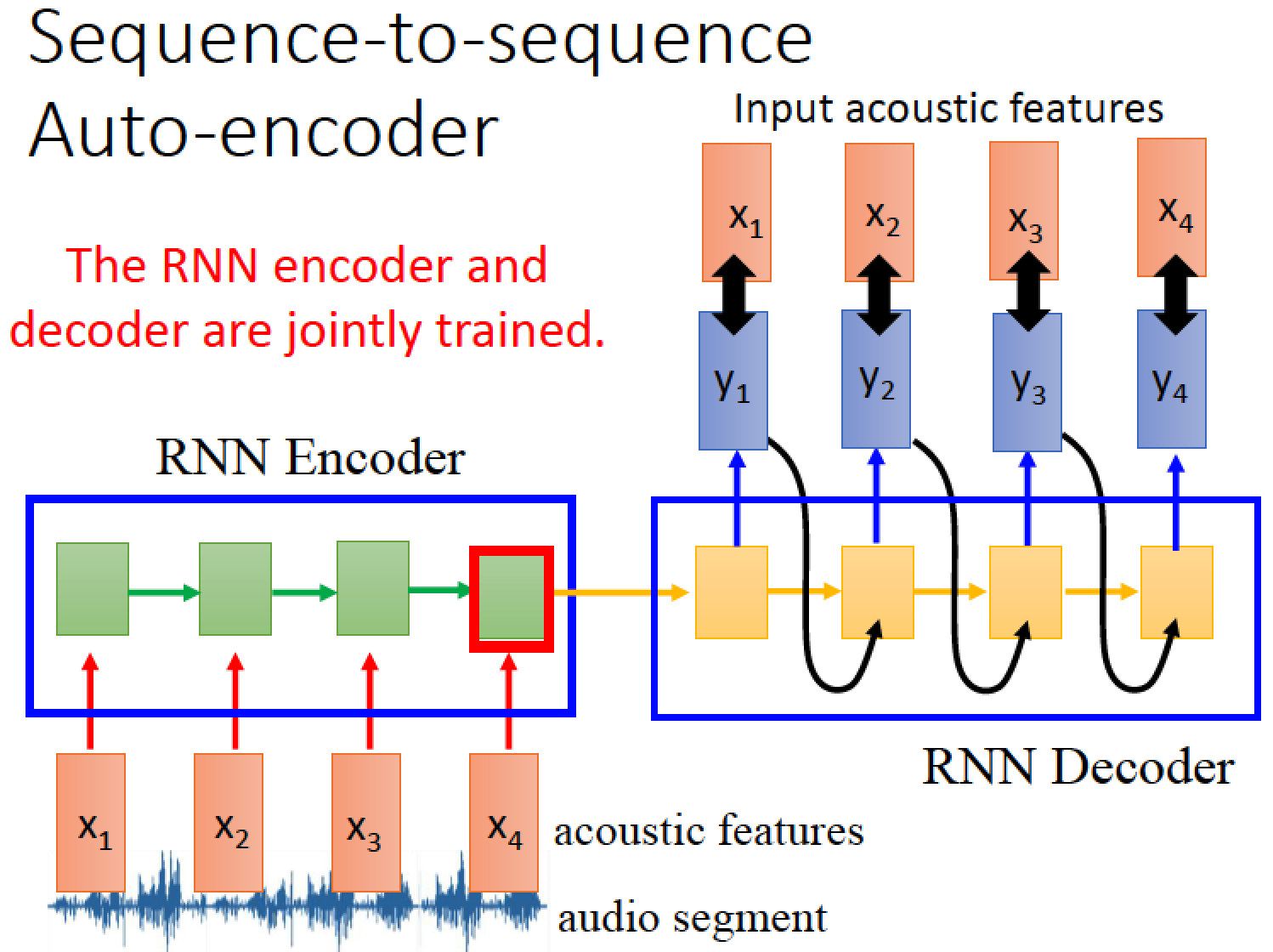
Decoder 的作用就是把存在 Encoder RNN memory 裡面的值拿出來當作 input
再根據 input 依序產生 y1, y2, y3, … 然後跟原本的 x1, x2, x3 比對正確性
所以這個架構中,Encoder 跟 Decoder 要一起 train !
實驗結果:

例如我們把 fame 開頭字母換成 n 變成 name 他的 word vector 移動的變化跟 fear 到 near 的移動方向是相同的
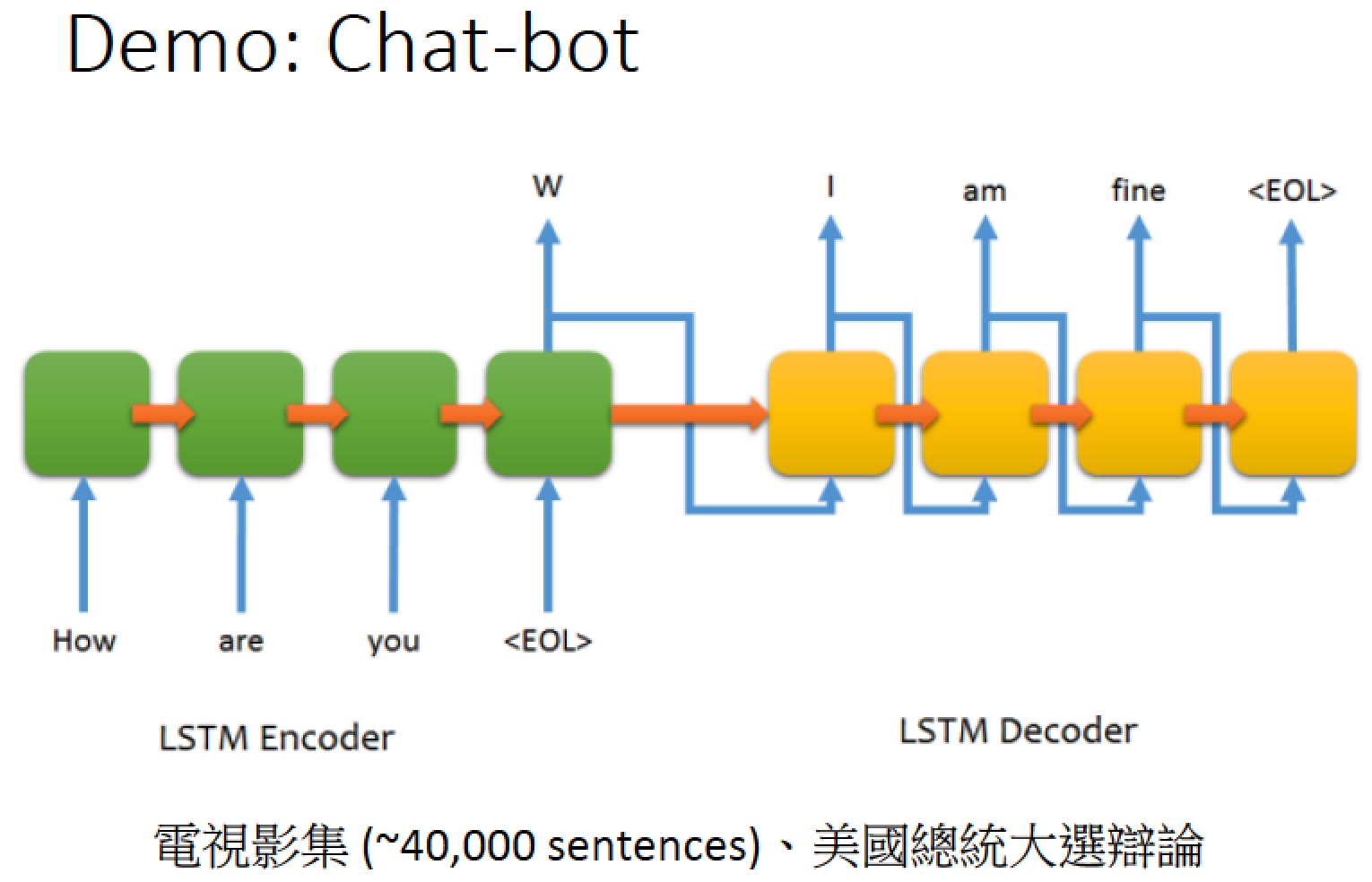
Chat-bot 可以用 sequence-to-sequence auto-encoder 來 train
資料:蒐集很多的對話,例如電影的台詞,辯論
假如 input 是 “how are you” 的話,output 就是 “I am fine”
大量的對話資料丟下去 train
除了 RNN 有用到 memory 以外還有一個 Attension-based Model 也有用到 memory
可以視為 RNN 的進階版本
想法:
人的大腦有非常強的記憶力,我們可以記得非常非常多的東西,
譬如我們同時記得今天早餐吃什麼,也記得十年前的夏天時發生什麼事
但是我們會自動忽略無關的事情,只記得重要的事情
當有人問什麼事 deep learning 時,我們腦中會把相關重要的事情組織起來,再產生 answer
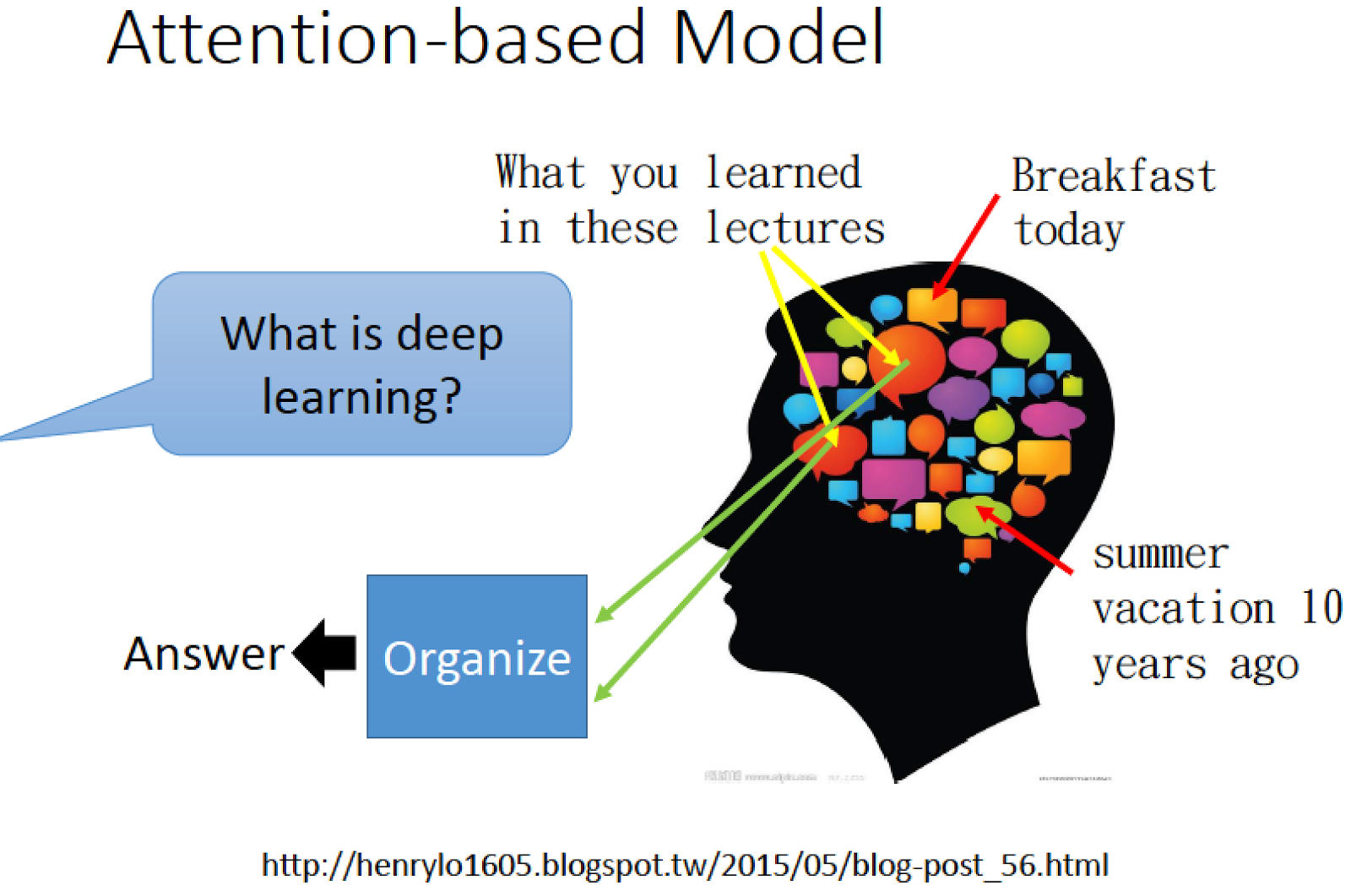
Machine 也可以記得很多事情
輸入時會經過一個中央處理器,可能是一個 DNN 或是一個 RNN
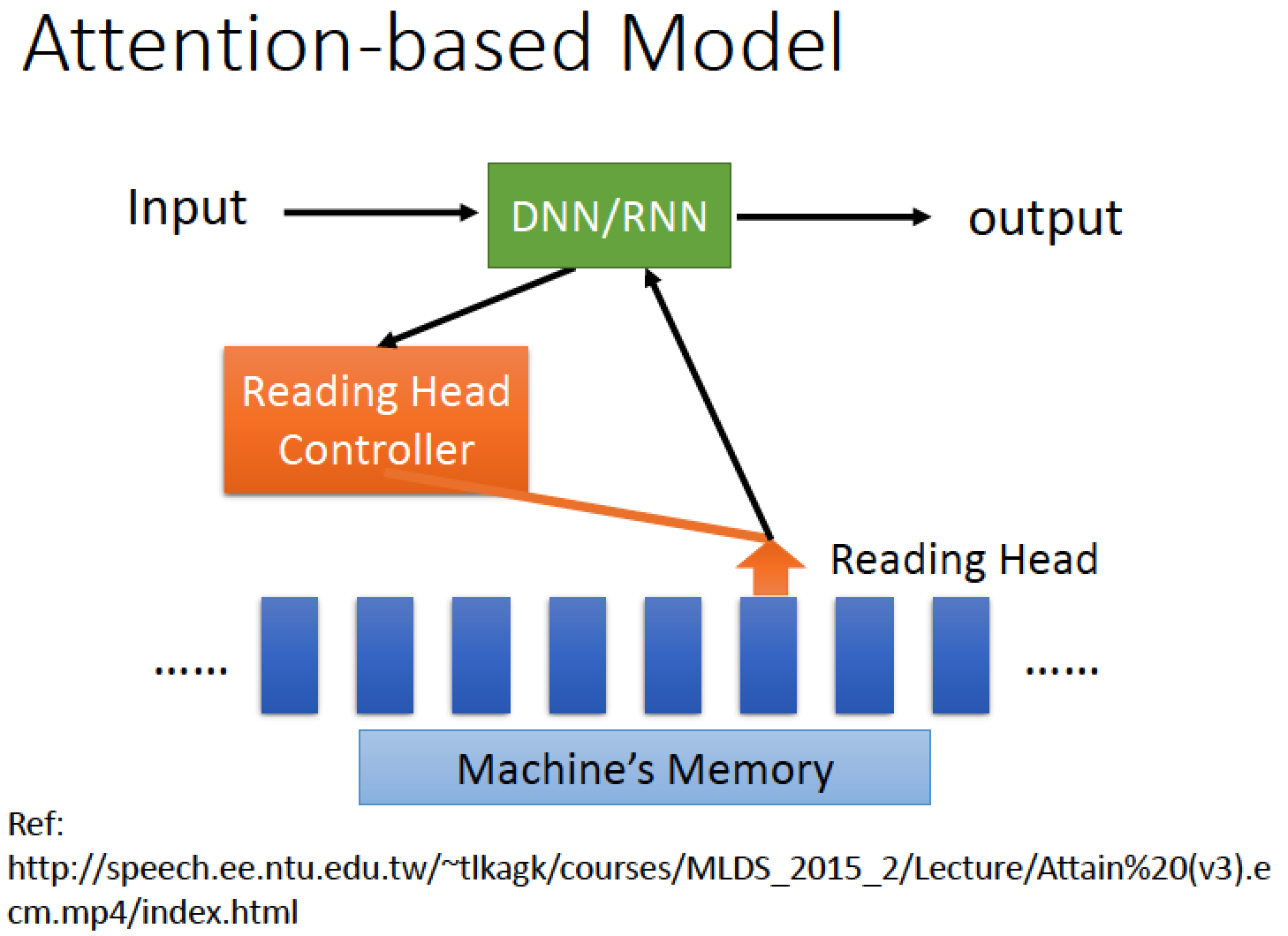
中央處理器會操控一個讀寫頭 Reading Head Controller 來決定 Reading Head 放的位置
Machine 再從 Reading Head 的位置去讀取資訊出來
詳細請見以下影片連結
這個 Model 還有 2.0 版本,除了 Reading Head 以外,還會操控一個 Writing Head Controller ,
會決定我們資訊要寫到哪個位置,這樣的結構就是大名鼎鼎的 Neural Turing Machine

這樣的 Model 常常被應用在 Reading Comprehension 裡面
輸入一份 Document 讓 machine 去讀,產生許多 vector ,每一個 vector 代表每一句話的語意

讀取 information :中央處理器控制 Reading Head Controller 去 Database 裡面找哪些相關的資訊要讀取進來,
這些讀取過程是可以重複數次的,mahine 可以從很多地方去讀取 information ,
把所有 information 讀取完成後,最後整合產生 answer

這是 Facebook AI Research 在 Baby Question & Answer 資料集上的實驗結果,
藍色代表了 Reading Head 的位置,可以從這些位置看出 Machine 的思路,
第一時間點,先提取 Greg (Hop 1),接下來在提取 frog (Hop 2),最後在提取 yellow (Hop 3),最後得到答案
Yellow !
machine 要 attention 在哪個位置是透過 data 自動去學出來的!
這樣的技術也可以應用在 Visual Question Answering
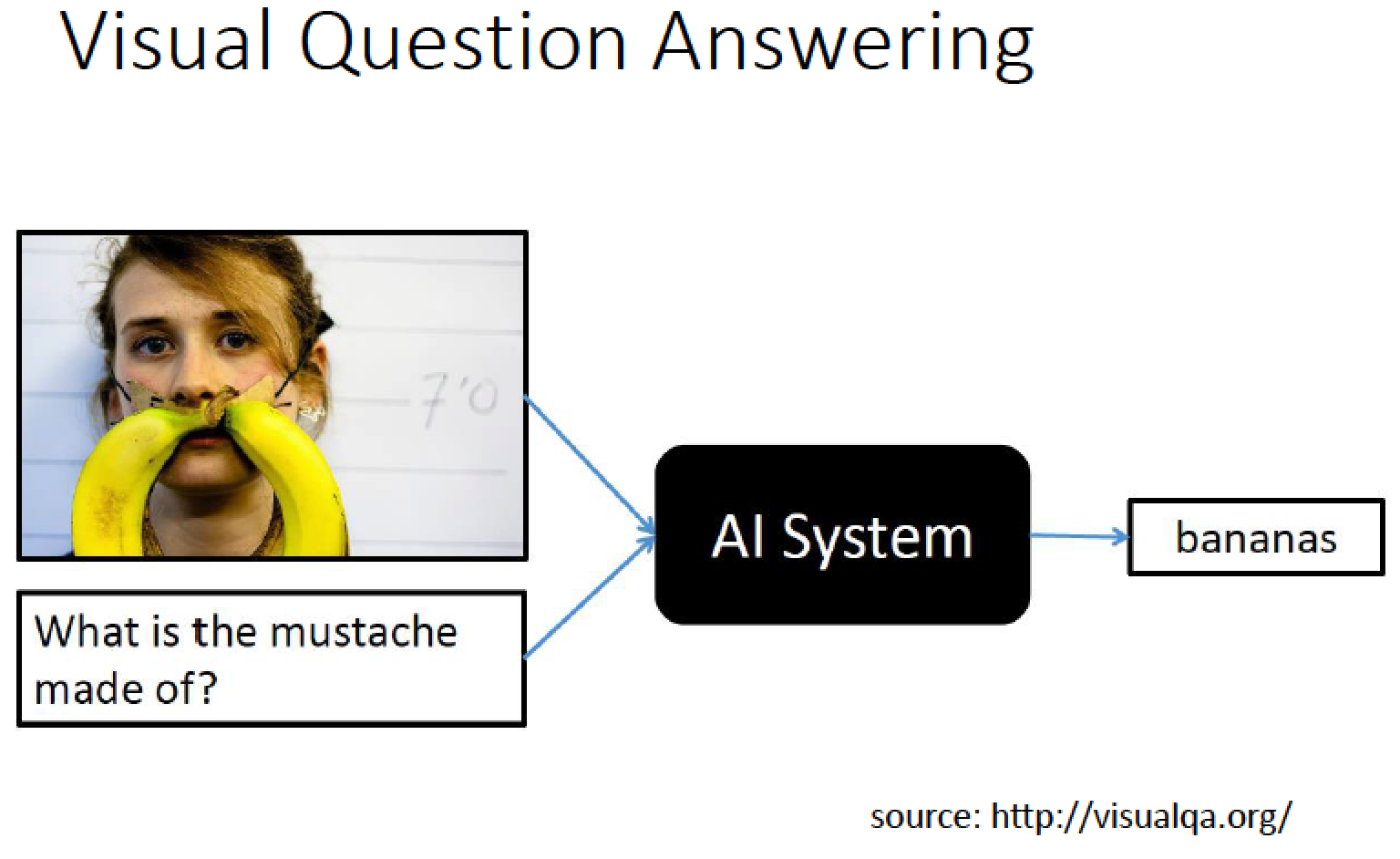
給 machine 看一張圖,然後問他一個問題!
怎麼做呢?

透過 CNN 把圖的每一小塊 Region 用 vector 來表示
接下來輸入一個 Query ,這個 Query 被丟到中央處理器,中央處理器操控 Reading Head Controller,
決定他要讀取資訊的位置,看看這個圖片的什麼位置跟現在輸入的問題是有關的,最後得到答案
也可以做語音的 Question Answering
例如讓 machine 做托福的聽力測驗
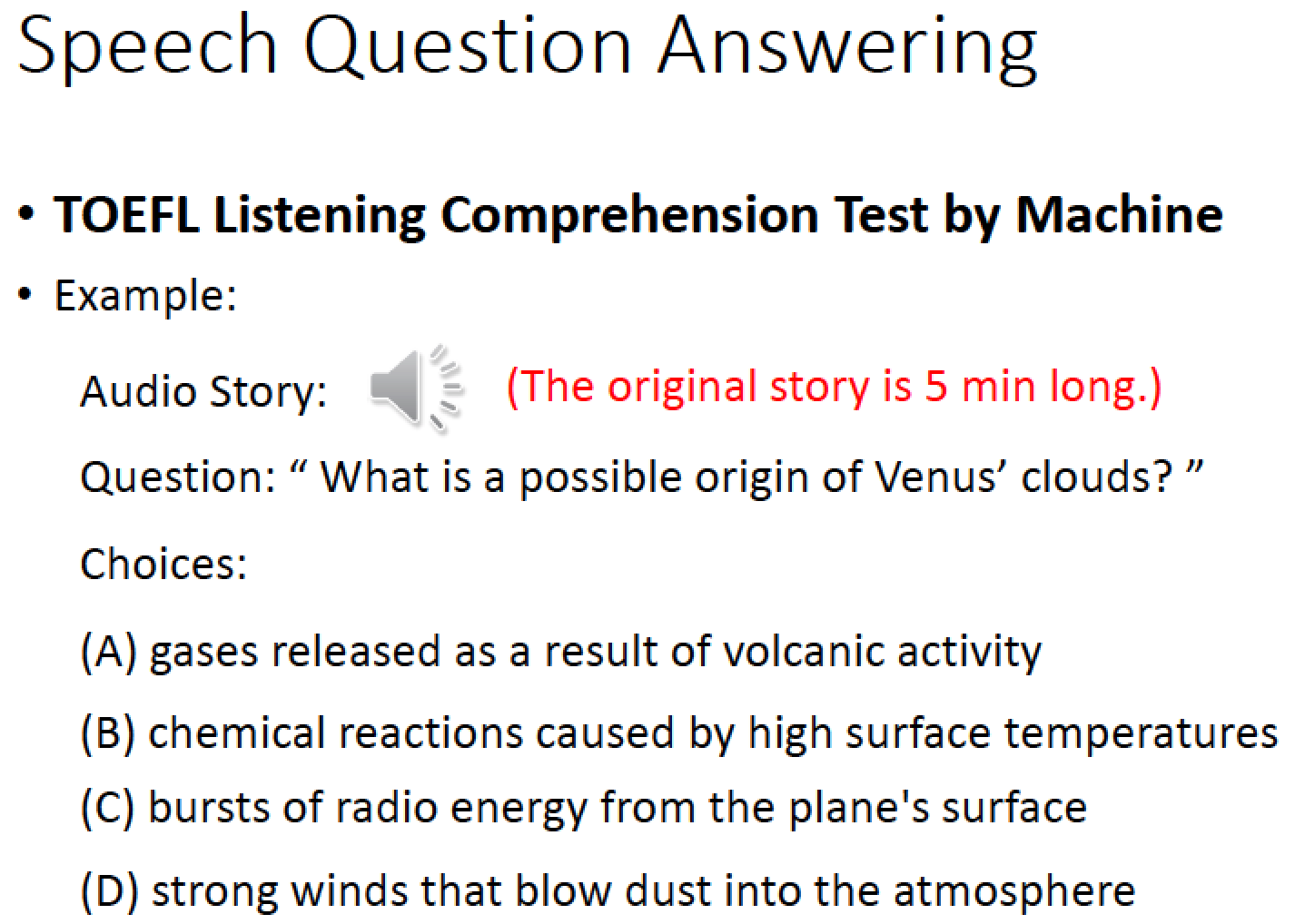
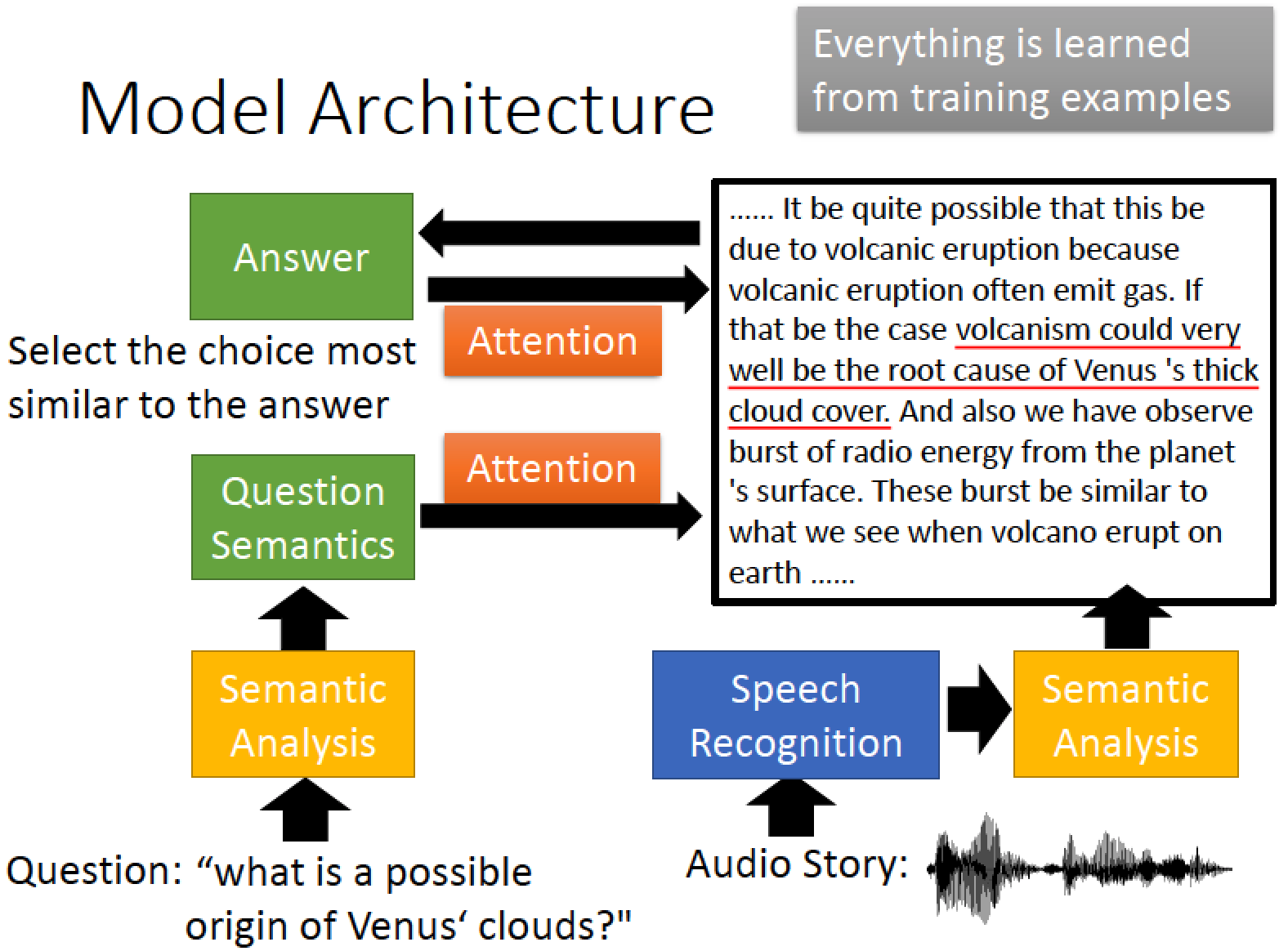
聲音的部分,先把訊號轉成文字,再去做語意分析
Question 經過中央處理器,中央處理器控制 Reading Head Controller 去找 database 當中哪些資訊是相關的,
最後整合後回答問題
實驗結果

隨便猜,正確率 25% 有兩個方法遠比隨便猜還要高:
選最短的選項可以得到 35% 的正確率 (2)
分析四個選項的語意,使用語意相似度分析,
某一個選項跟另外三個選項語意相似度高的話就把它選出來,也得到 35% 的正確率 (4)
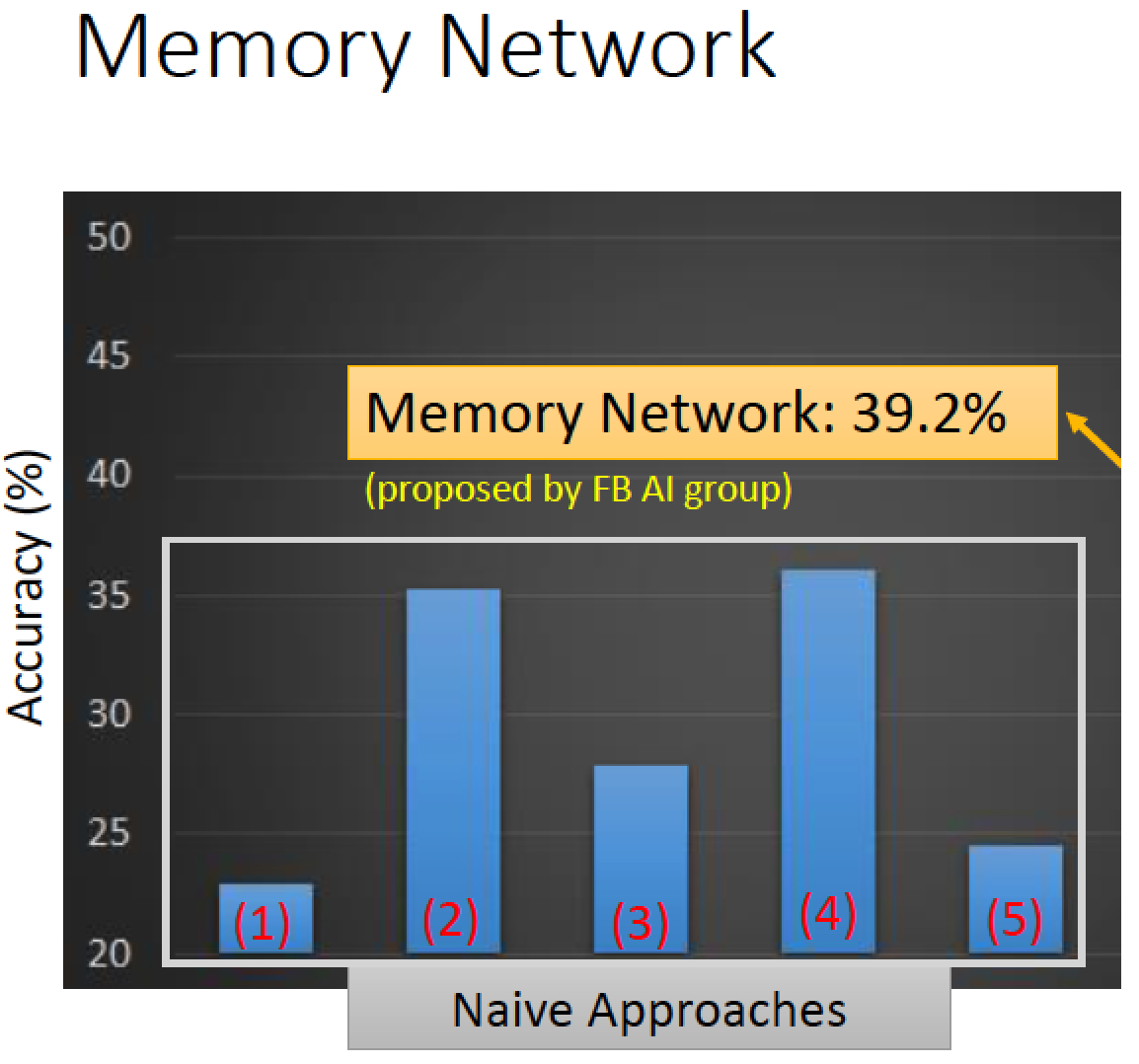
使用 Memory Network 可以得到 39.2% 的正確率
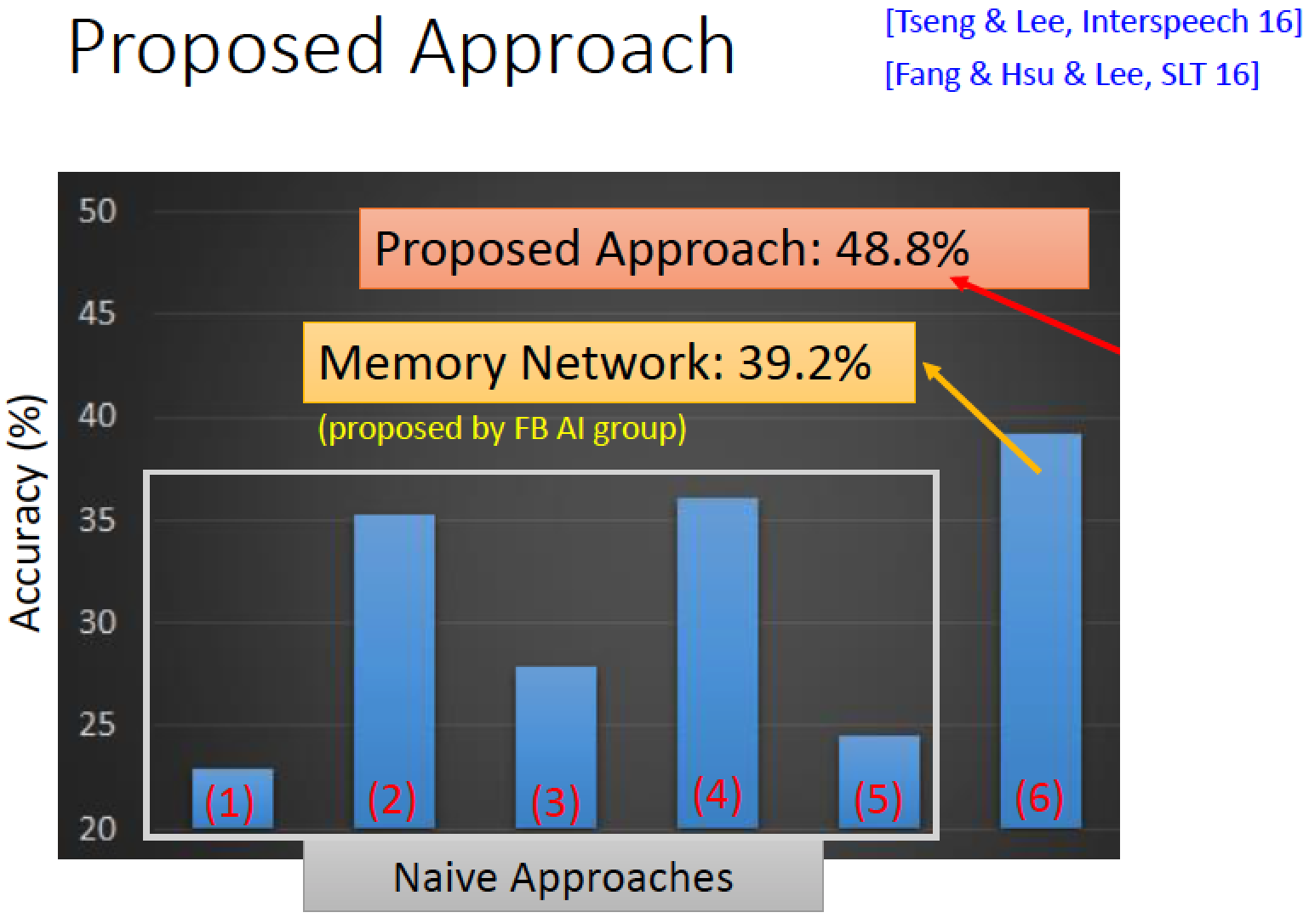
用我們剛才講的技術來答題,可以得到 48.8% 的正確率
留言
張貼留言