[ML筆記] Convolutional Neural Network (CNN)
ML Lecture 10: Convolutional Neural Network CNN
本篇為台大電機系李宏毅老師 Machine Learning (2016) 課程筆記
上課影片:
https://www.youtube.com/watch?v=FrKWiRv254g
課程網 (投影片出處):
http://speech.ee.ntu.edu.tw/~tlkagk/courses_ML16.html
上課影片:
https://www.youtube.com/watch?v=FrKWiRv254g
課程網 (投影片出處):
http://speech.ee.ntu.edu.tw/~tlkagk/courses_ML16.html
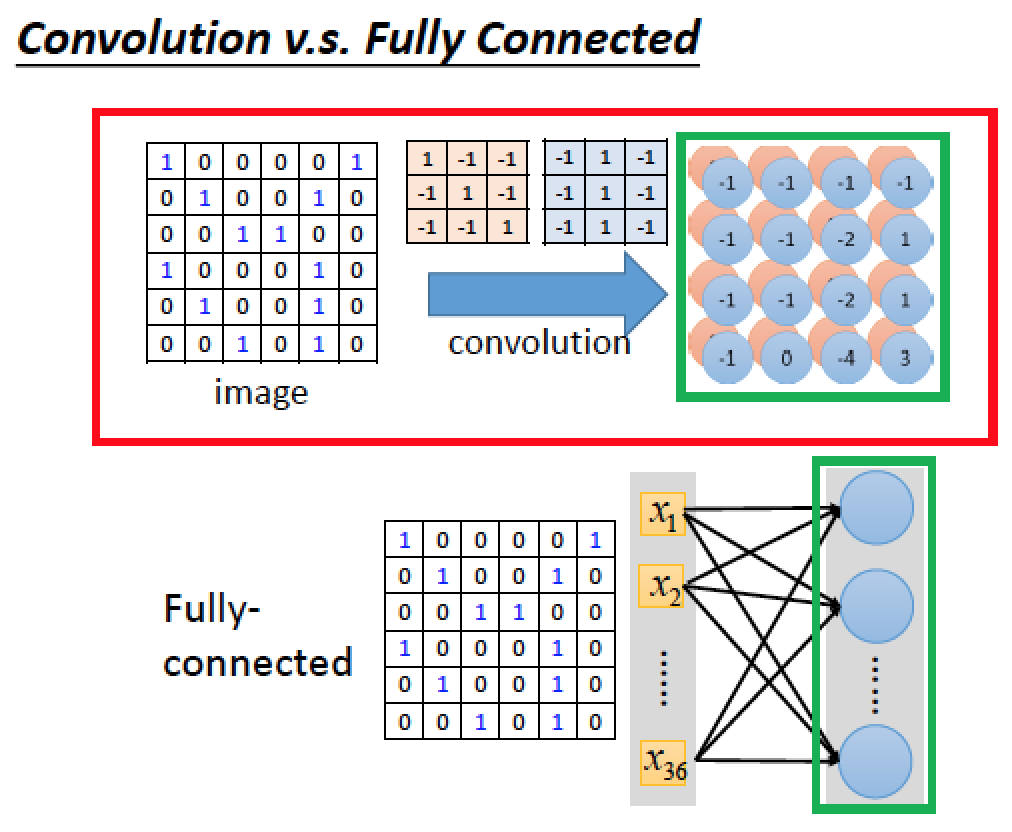
在 NN 架構中
每一個 Neural 都可視為一個簡單的 Classifier

所以整張圖片 vector 攤平後總共有 30000 維度,有 30000 個參數
當我們使用整張影像處理時,往往會需要太多的參數!
但是其實影像上要很多 pixel 在一起才有意義,所以我們可以利用一些方法把一些參數濾掉,用比較少的參數來做!
為什麼我們可以用比較少的參數來做這件事情?

例如我們只要看圖片中小塊的區域,偵測到鳥嘴,就可以知道圖中有鳥類!
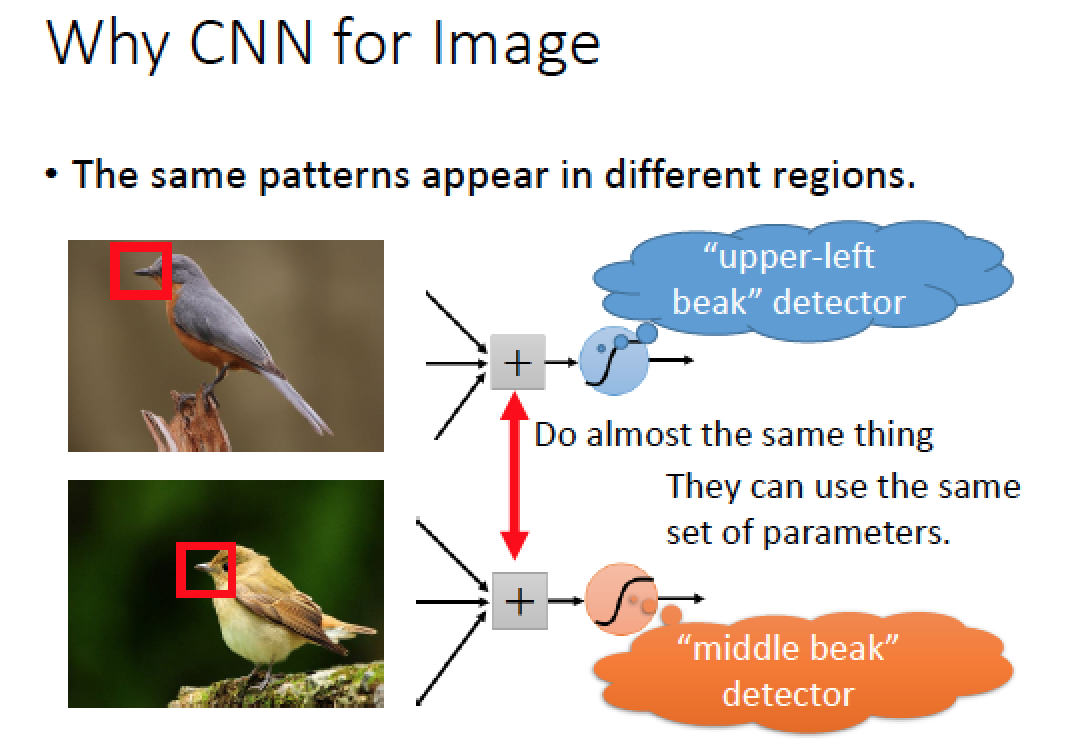
同樣都是偵測鳥嘴的 Neuron 可以直接共用! 減少需要用的參數!

一張高解析度的圖,經過 subsampling 可以變成較小的圖,但是圖中的鳥的資訊不會受到影響!所以可以透過 subsampling 來減少訓練 NN 時需使用到參數數量!
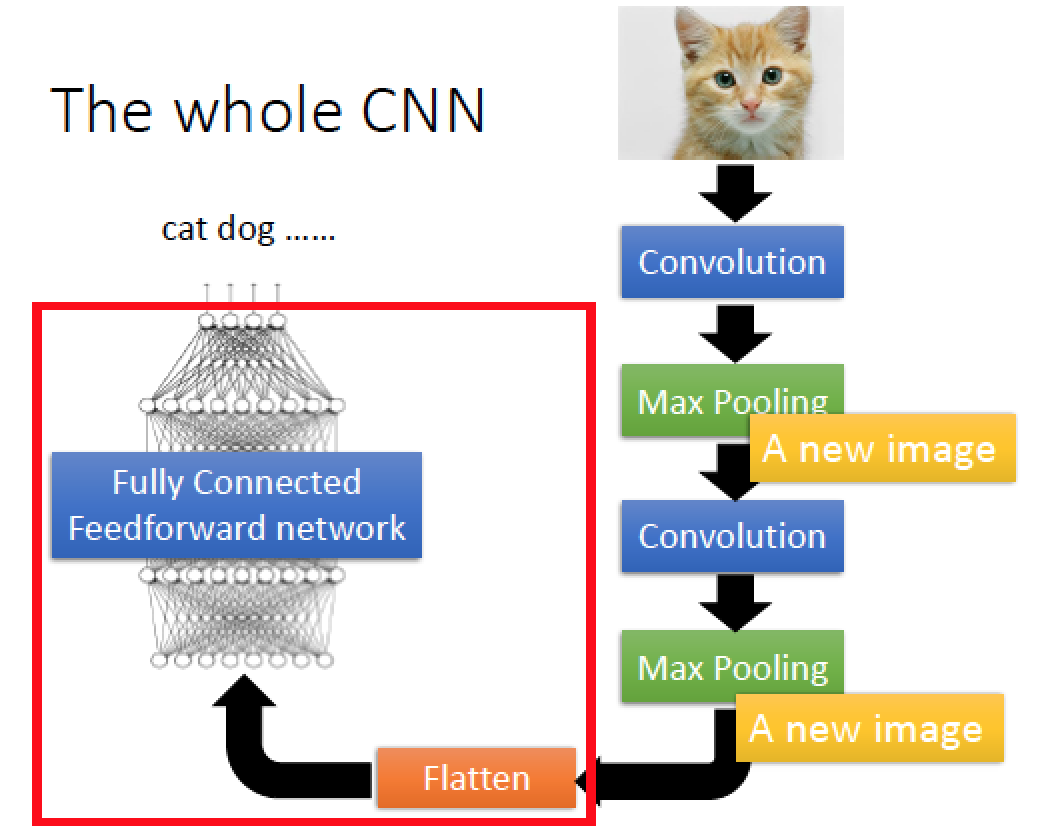
CNN 完整架構
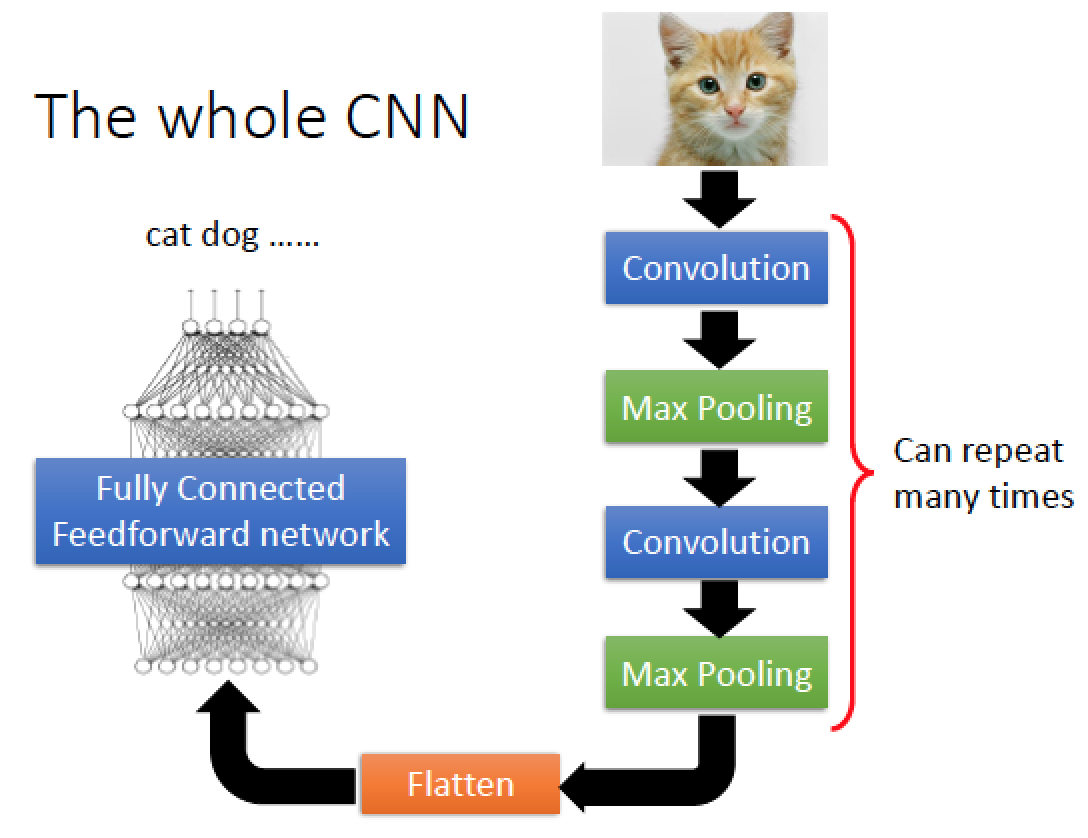
輸入圖片後,先做 Convolution 在做 Max Pooling
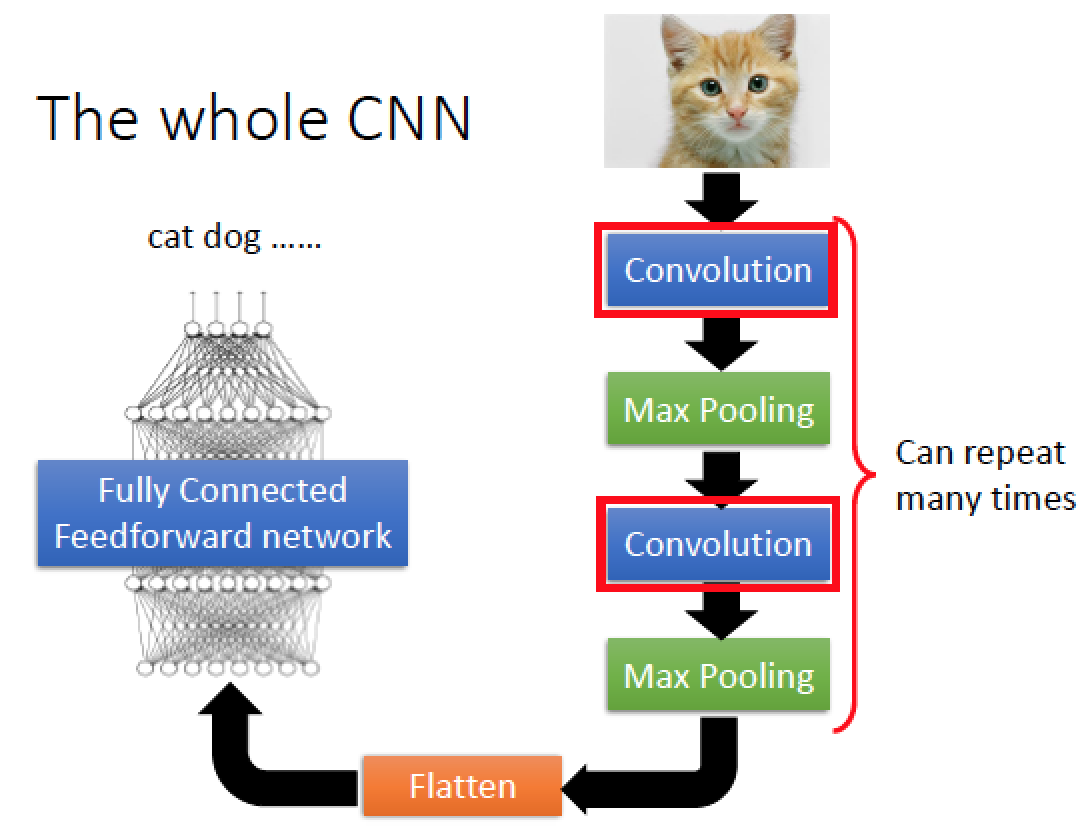
然後 Convolution 搭配 Pooling 的次數與細節是可以設計的,上圖例為兩次,做完後的結果攤平 “Flatten” 成一個一維的 Vector 然後丟到傳統的 DNN 架構: Fully Connected Feedforward network 裡面,最後得到 output
 |  |
Convolution
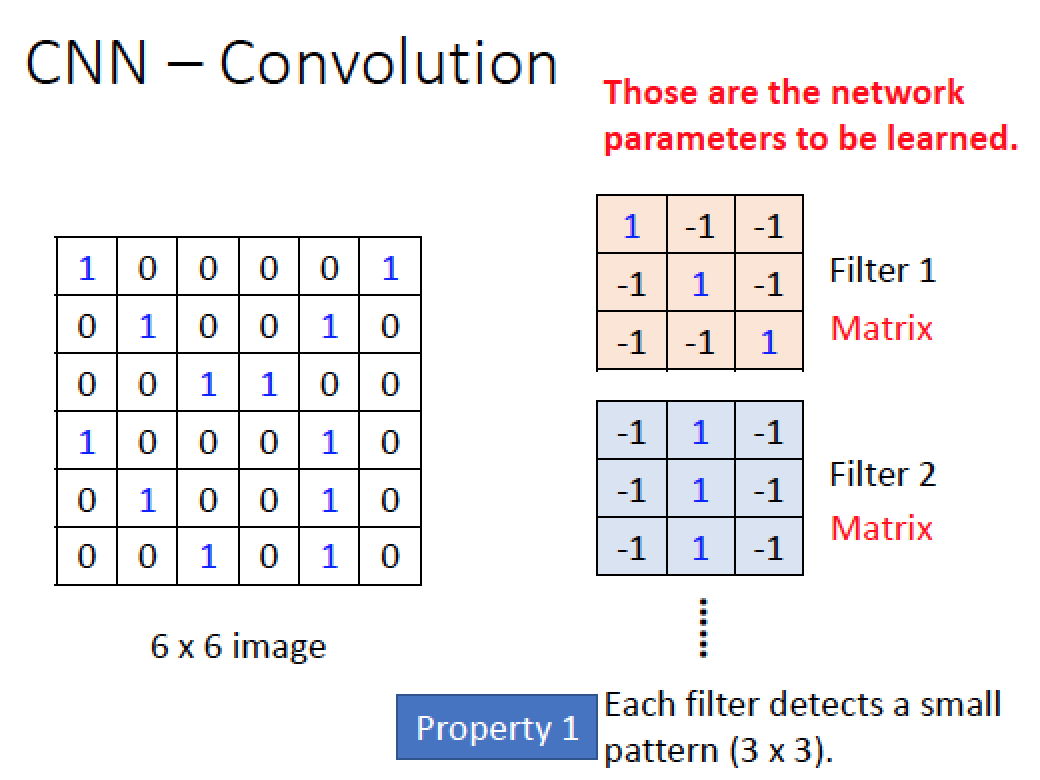
舉一個黑白照片的例子
0 代表沒訊號:白色
1 代表有訊號:黑色
上圖中有一張 6x6 的圖,以及有兩種 Filter (Filter 1 , Filter 2)
我們的 Filter 大小為 3x3 要偵測圖中是否出現特定的形狀
Filter 1 斜對角左上到右下都是 1 ,其餘是 -1 ,所以 Filter 1 的功能是偵測圖中是否有符合 “左上到右下” 斜直線的形狀
Filter 2 中間由上到下都是 1 ,其餘是 -1 ,所以 Filter 2 的功能是偵測圖中是否有符合直線的形狀
使用 Filter 在圖中運作原理如下:

將 3x3 大小的 Filter 1 疊到圖上右上角,圖中每一個 pixel 都跟對應到 Filter 1 上面的每個 pixel 相乘,最後全部相加,得到 1x1 + 1x1 + 1x1 + 其餘的都是 0 x(-1) = 3
同理,Filter 1 往右移動一格 (stride = 1),並做相同的運算得到結果為 -1
| 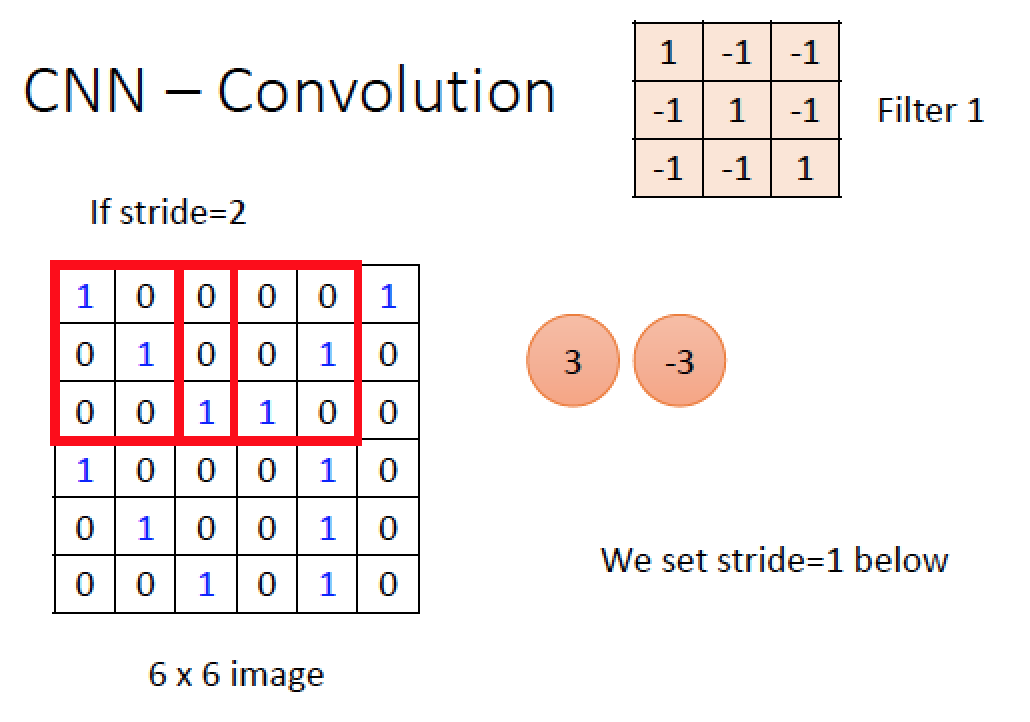
移動的格數,Filter 的大小都可以設定,假如我們每次移動為兩格 (stride = 2),則經過 Filter 1 運算:得到 1 x (-1) + 1 x (-1) + 1 x (-1) + 0 x 1 (三次) + 其餘都是 0 x (-1) = -3
移動後運算的結果為 -3
|
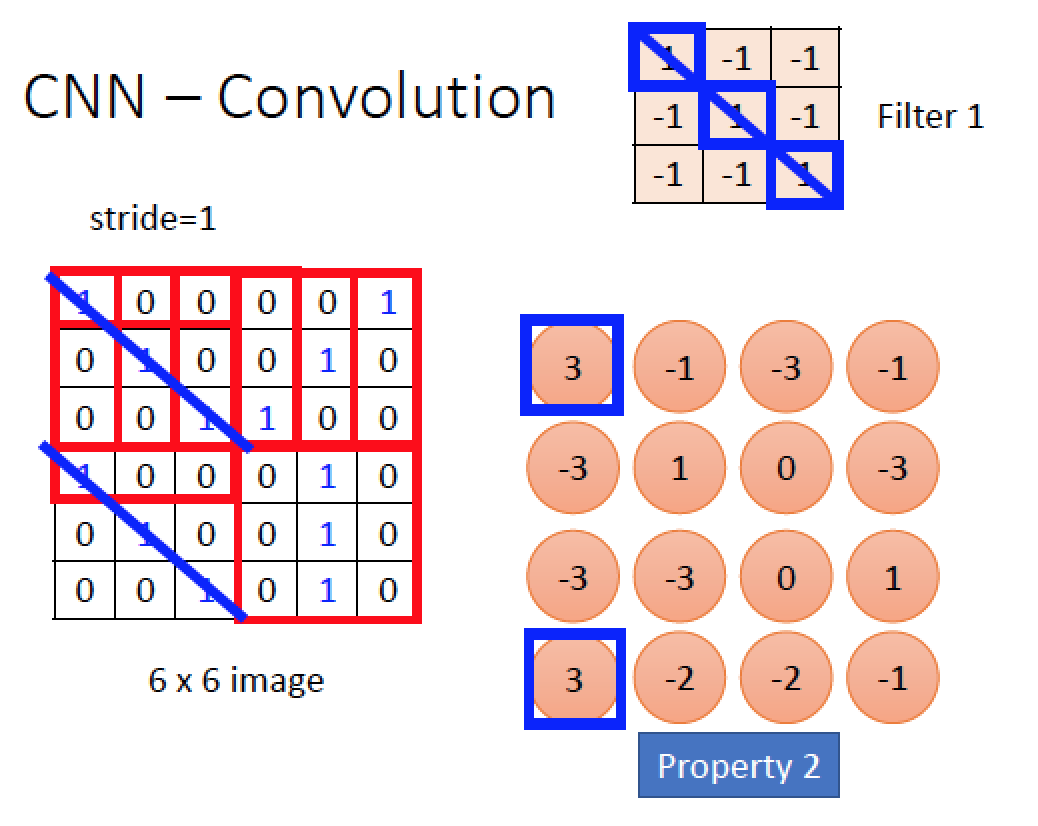
經過 Convolution 的運到,得到的結果當中,出現最大值的地方就是圖中最符合 Filter 要篩選的形狀之處!
大小為 6x6 的圖片,經過 3x3 的 Filter 1以 stride =1 的移動步伐做完 convolution 後,得到 4x4 的結果 “圖” ( 圖就是矩陣matrix )
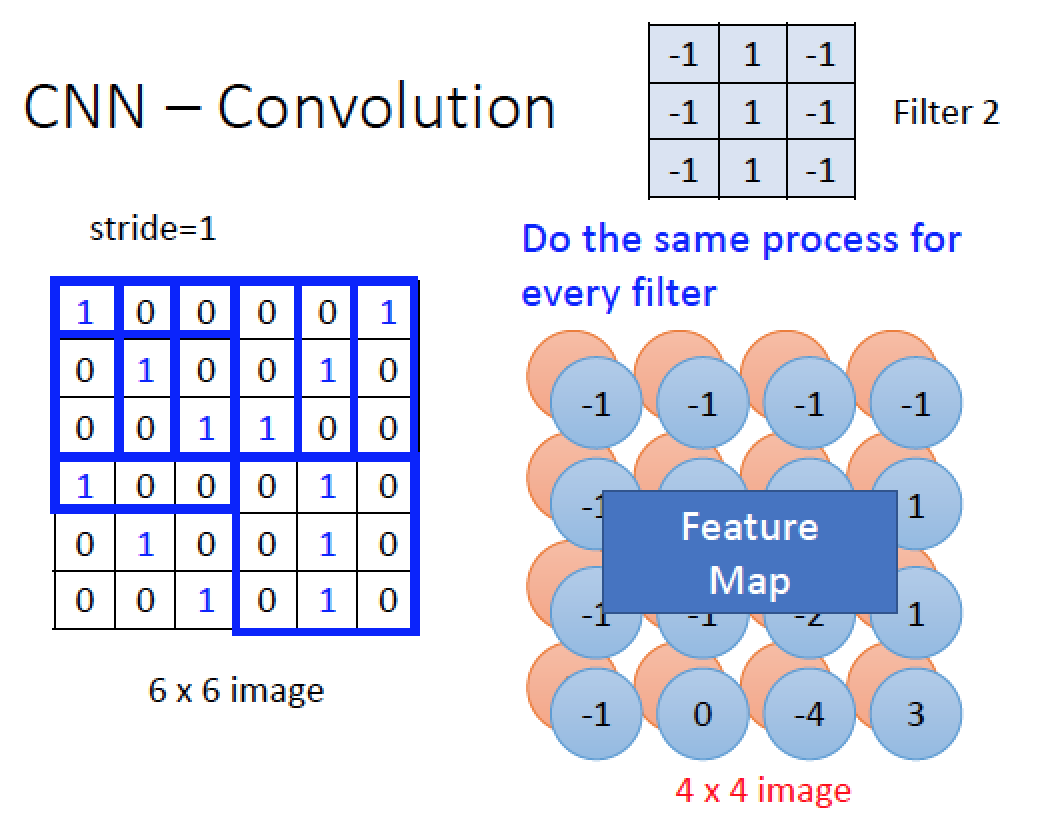
同理,我們把 Filter 2 也在圖中運算完畢後,得到另一個結果圖 (藍色圓圈部分)
我們有兩個 Filter (大小都是 3x3) 就會產生兩張 Convolution 的結果 image (大小都是 4x4)
有很多 Filter 就會得到很多張 Convolution 的 image
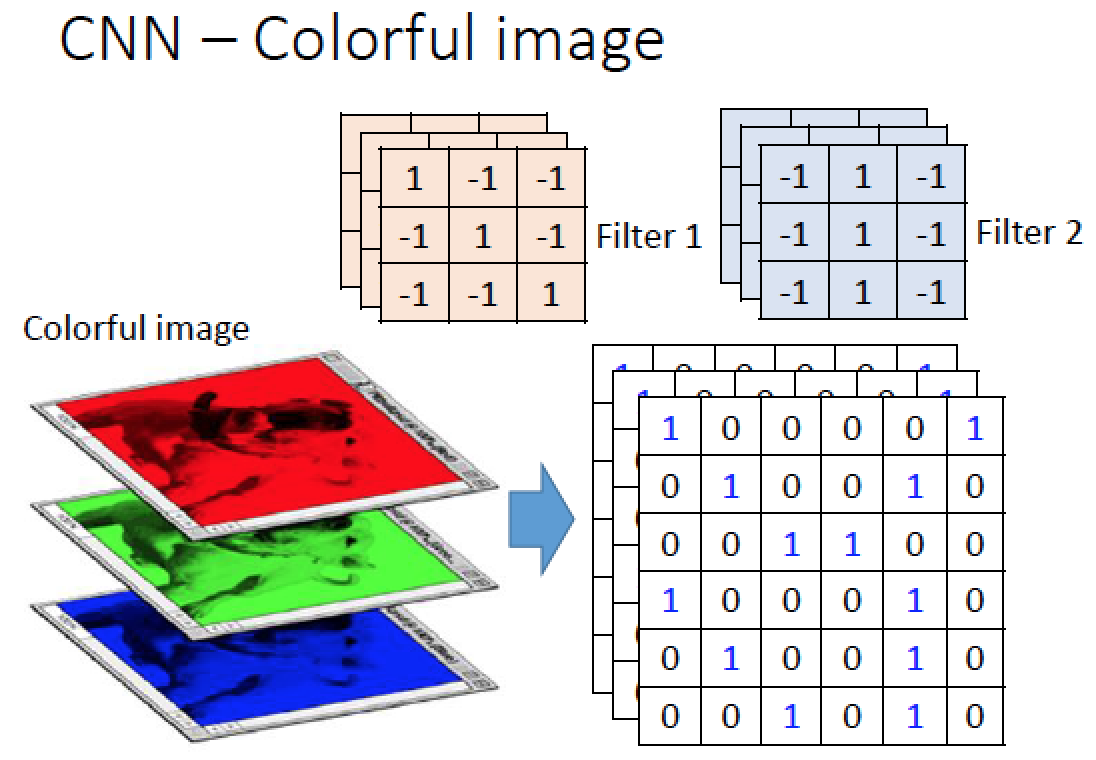
如果圖片是彩色的話,代表每個 pixel 都有三個維度,所以我們 convolution 所使用的 Filter 就是立體的 (3x3x3),然後把立體 Filter 跟圖中的值做內積!
其實 convolution 可以視為 fully connected layer 拿掉一些 weight 的結果
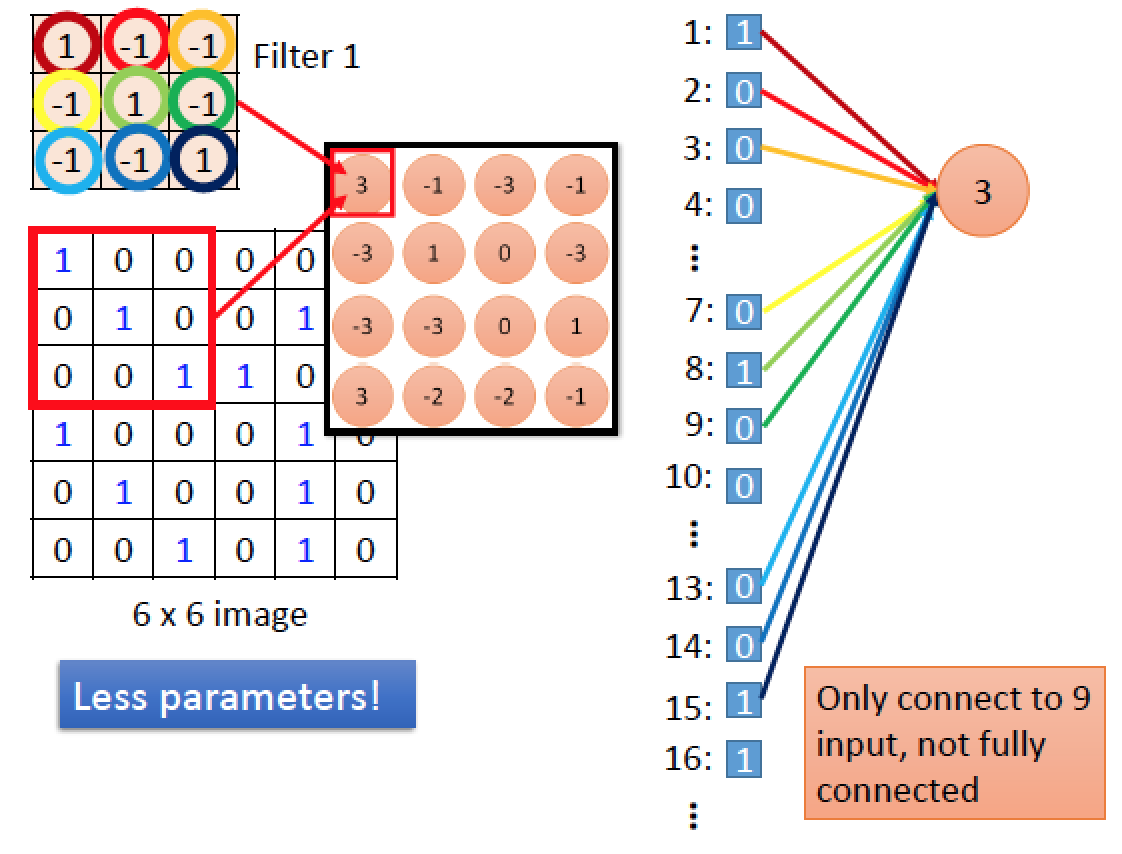 | 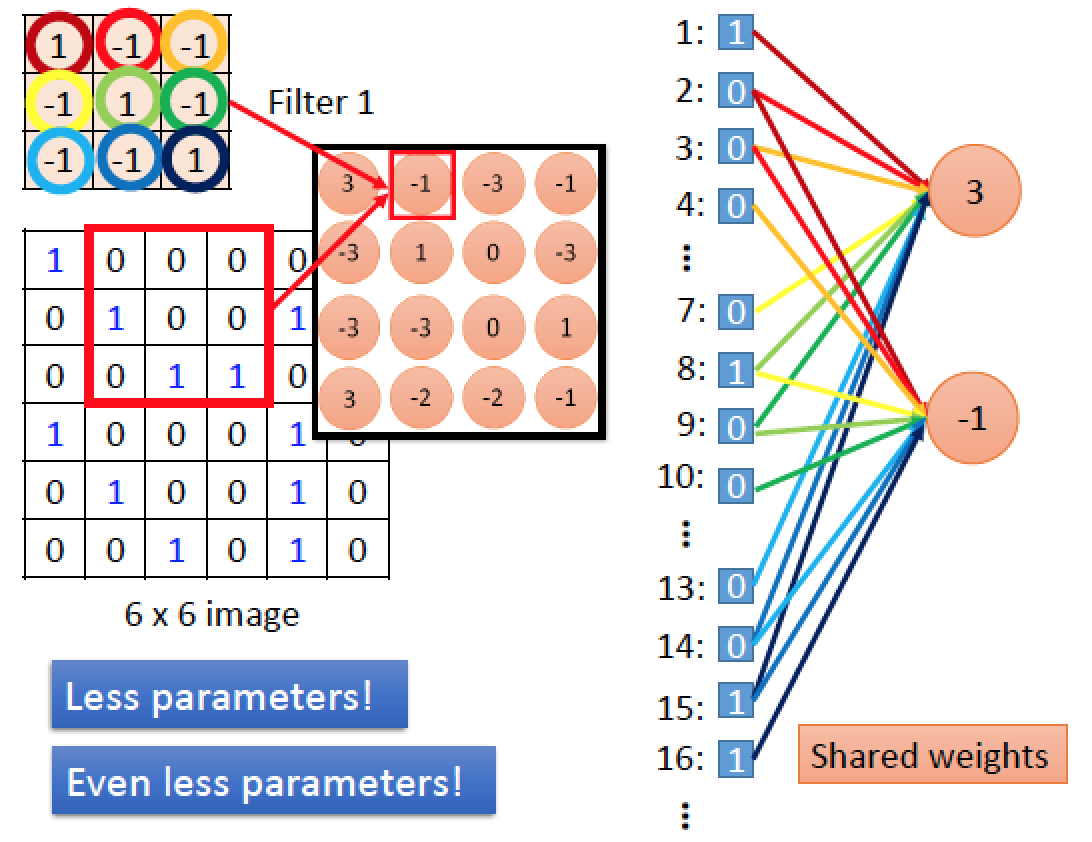 |
把原始圖片拉直,加上編號,對於 Filter 1 結果圖中 “第一個神經元” 而言,它只連結到原圖中的 9 個點, weight 部分我們用不同顏色表示。對於 Filter 1 結果圖中 “第二個神經元” 而言,他也只連接到原圖中 9 個點,有些跟上一個重複,且連接所使用的 weight 跟剛剛的都一樣!這件事稱為 weight sharing
Max Pooling

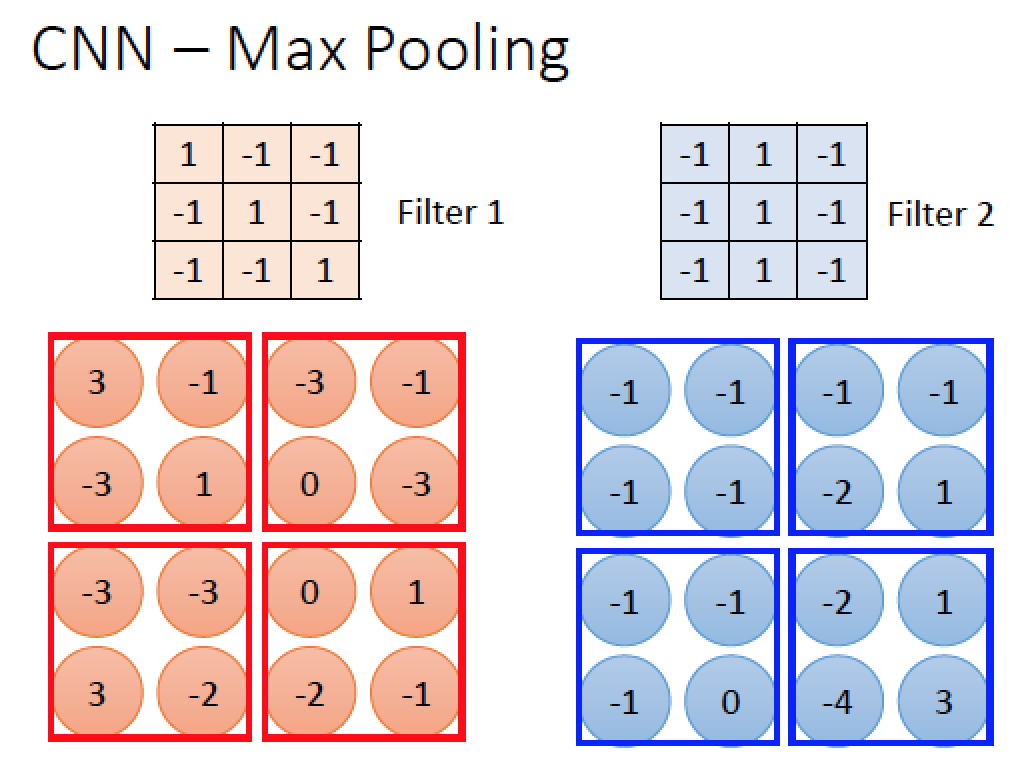 | 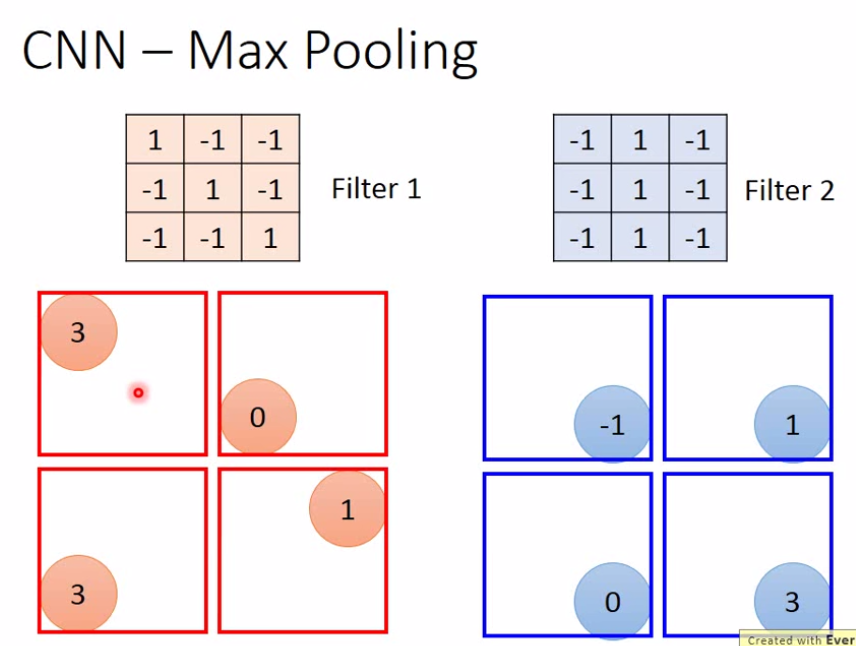 |
Max Pooling 的原理很簡單,我們把剛剛 convolution 得到的結果圖,每四個 pixel 當成一個單位,挑出最大值的留下來,如此即可使用一個值代表四個值,達到降低解析度的結果
我們上例當中,把 4x4 的圖片,降為 2x2 的
至於 2x2 結果當中,每一個 pixel 的 “深度” 或者說是 “高度” 多少取決於我們使用了幾個 Filter
 每個 filter 代表一個 channel
每個 filter 代表一個 channel 
到目前為止,我們把圖片經過 convolution 在經過 pooling 後就得到一個比較小的 image
如果再把這個比較小的 image 拿去做 convolution 再做 pooling 後可以得到更小的 image !
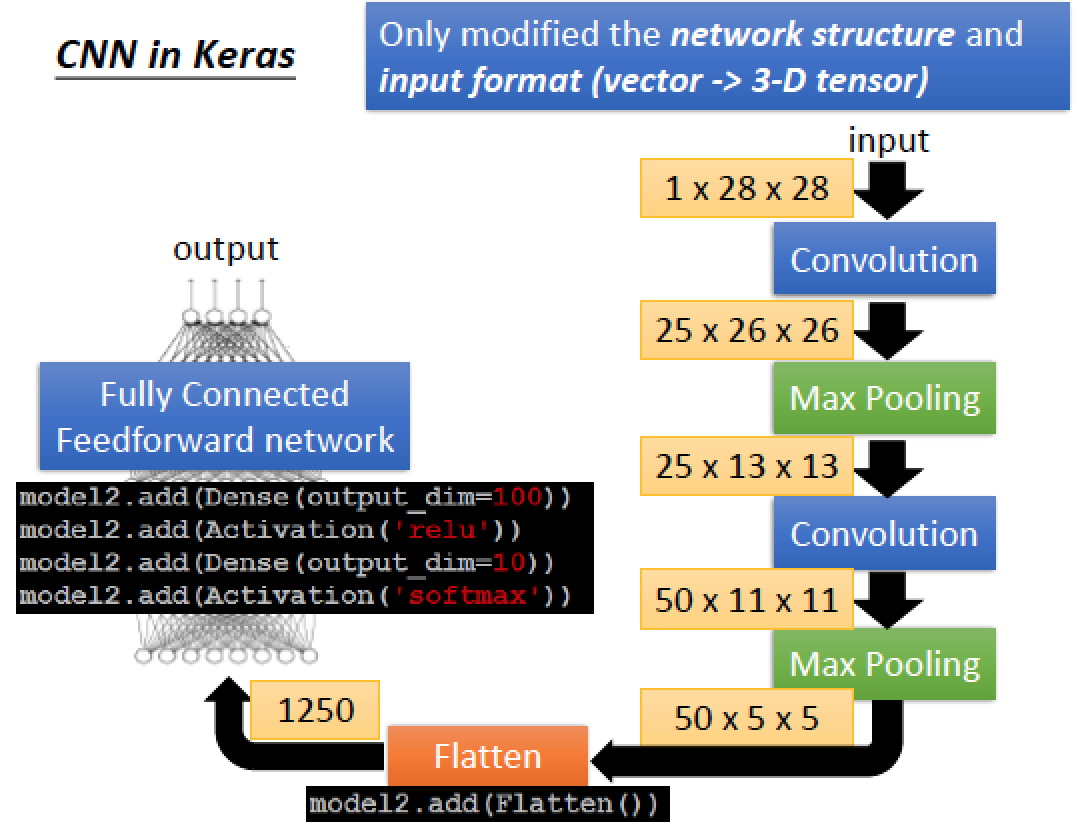
問題:我們使用 25 個 Filter 經過兩回合 convolution 後,請問是否得到 252的 Feature Map ?
不是!因為就算到了第二回合 convolution 時,他仍然考量 25 個 filter 只是每一個 Filter 的形狀是 “立體” 的,而立體的高度是 25 !,所以全部做完,仍得到25 個 “更立體” 高維度的 feature map
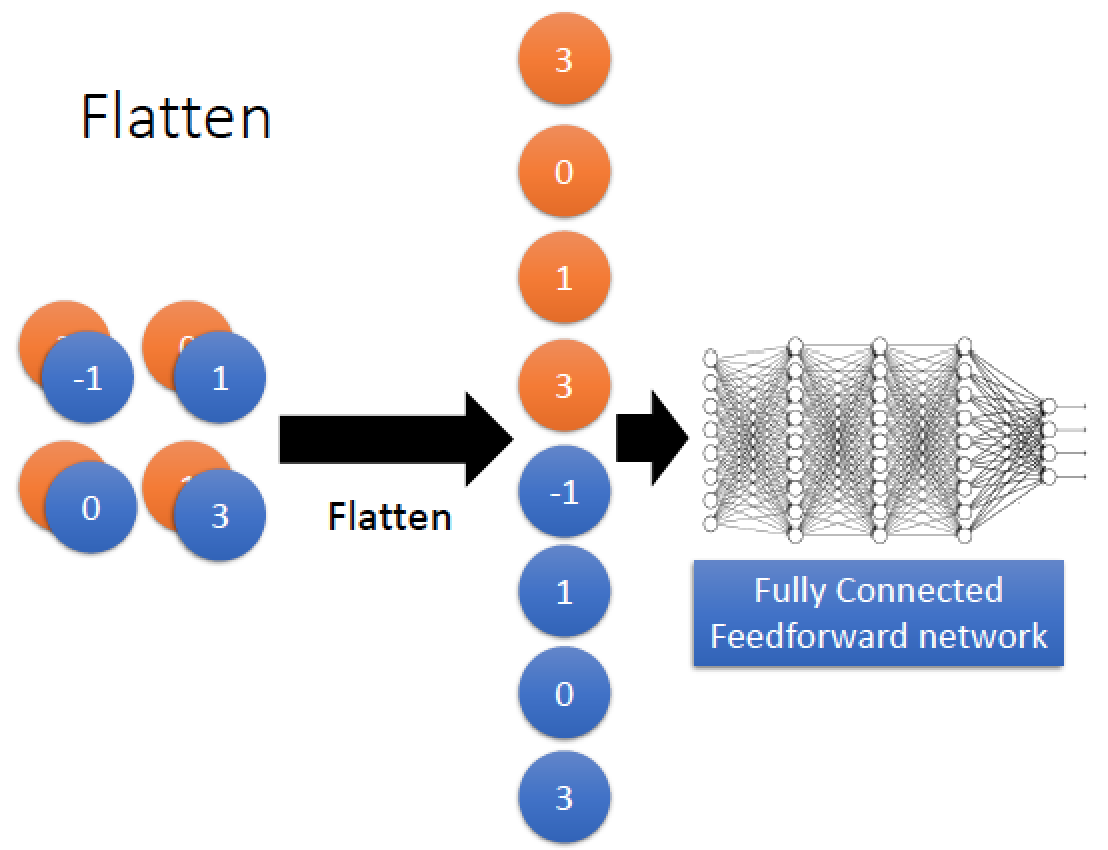
最後的 Flatten 的部分很簡單,就是把我們得到的結果攤平,然後全部丟到 Fully Connected Neural Network 就結束了!
 | 
問題1: 3 x 3 = 9 ; 問題 2: 3 x 3 x 25 = 225
|
分析每個 Filter 學到什麼
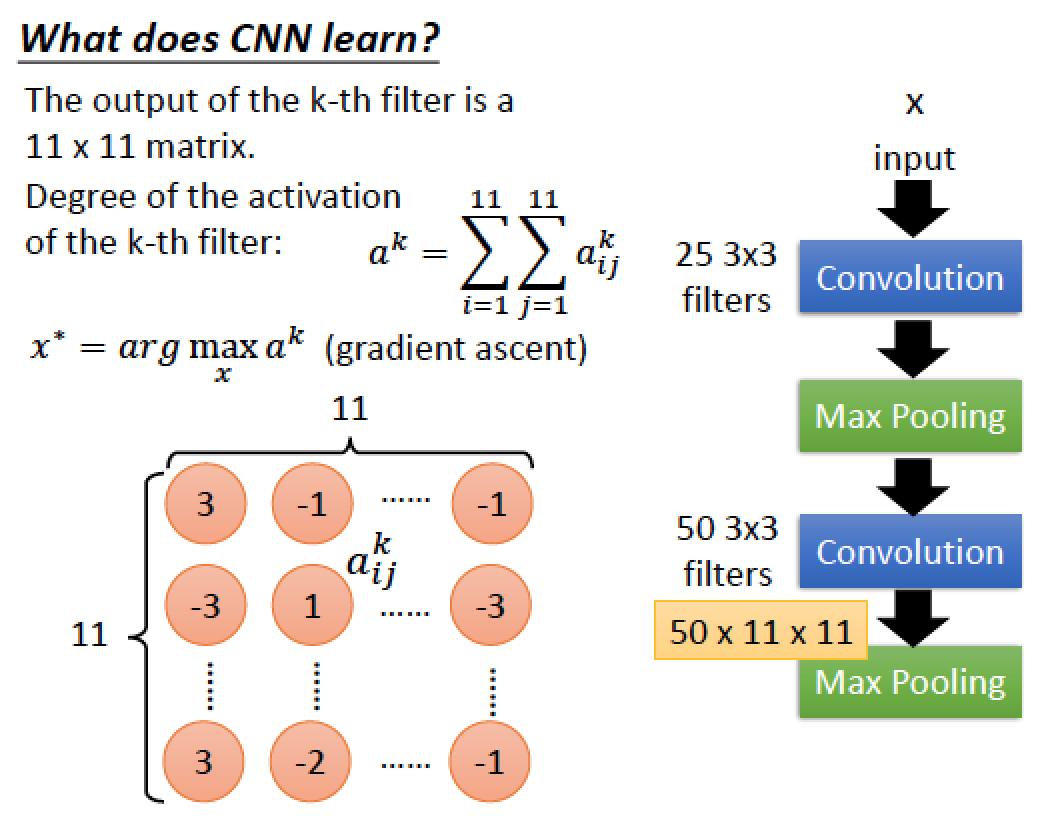
我們取出第 k 個 Filter 然後定義 ak 代表此第 k 個 Filter 有多被 activate 的程度
想要看 Filter 學到什麼,我們以 MNIST 手寫數字圖片資料為例
我們現在要解的問題是,找一個 image x 可以讓有 ak 最大的 “反應” (by Gradient ascent)
也就是找一張 input x 他可以讓我們的 Filter 有最劇烈的 “反應”,等於把立場反過來!
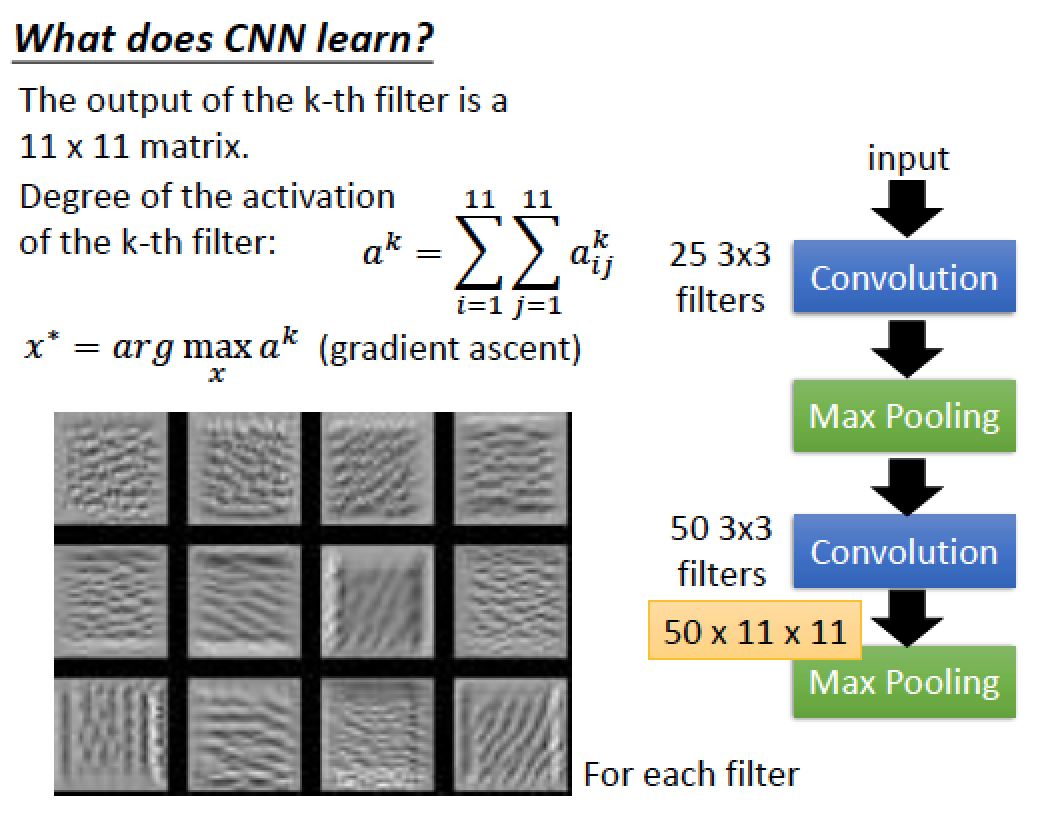 ← 結果大概長這樣子
← 結果大概長這樣子
這些結果的共同特徵就是某種 texture 在圖上不斷地重複
我們接下來可以分析 Fully Connected Layer 裡面
Neural Network 裡面的 Neuron 的工作是什麼
我們如法炮製剛剛做的事情
產生出來的 images 跟剛剛在 Filter 部分產生的很不一樣

因為現在每一個 Neuron 的工作都是看長張圖,而不是局部了!
如果我們今天考慮的是 output 層呢?
以上述同樣手法來產生最 activate 的圖片

結果發現出來的圖片都亂亂的
參考影片

所以我們應該進一步針對找出來的 input x 加上一些 constraint 限制
告訴 Machine 說,有一些 x 雖然可以讓你的 y 很大,但是不能考慮它!
對一個數字 Digits 來說,整張圖中大部分都是背景,只有寫數字的地方才有資訊,只有整張圖當中某一個小部分才會有筆劃
右上的式子加號應該要改成減號,他做的是 L1 reuglarization
如此做完後,得到一個比較像數字的結果
以上其實就是 Deep Dream 的概念
Deep Dream

我們把一張圖片丟到 CNN 裡面後,把它某一個 Layer 隨便抽出一個,得到一串 Vector
然後把正的讓它變個更正,負的變得更負
然後把這個東西當作是新的 image 的 “目標” ,(更新)找一張 image (用 gradient ascent) 更能符合我們調整後的結果,讓 CNN 誇大化它所看到的東西!

得到的結果就變成這樣子!
Deep Dream 的進階版本就是 Deep Style
Deep Style
 |  |
 |
首先把原圖丟進 CNN,得到 CNN Filter 的 output 代表這張圖中有什麼樣的 content
吶喊這張圖也丟到 CNN Filter 裡面,但是這次我們要的不是 Filter output value 而是 Filter 跟 Filter 之間的 corelation 代表 style
接下來就用同一個 CNN 找一個 content 他同時 maximize 左邊照片的元素,以及他的 Filter 之間的 corelation 像右邊那張吶喊
就可以得到 Deep Style 的結果
paper:
|
CNN 應用
例如用於下圍棋 Alpha Go !
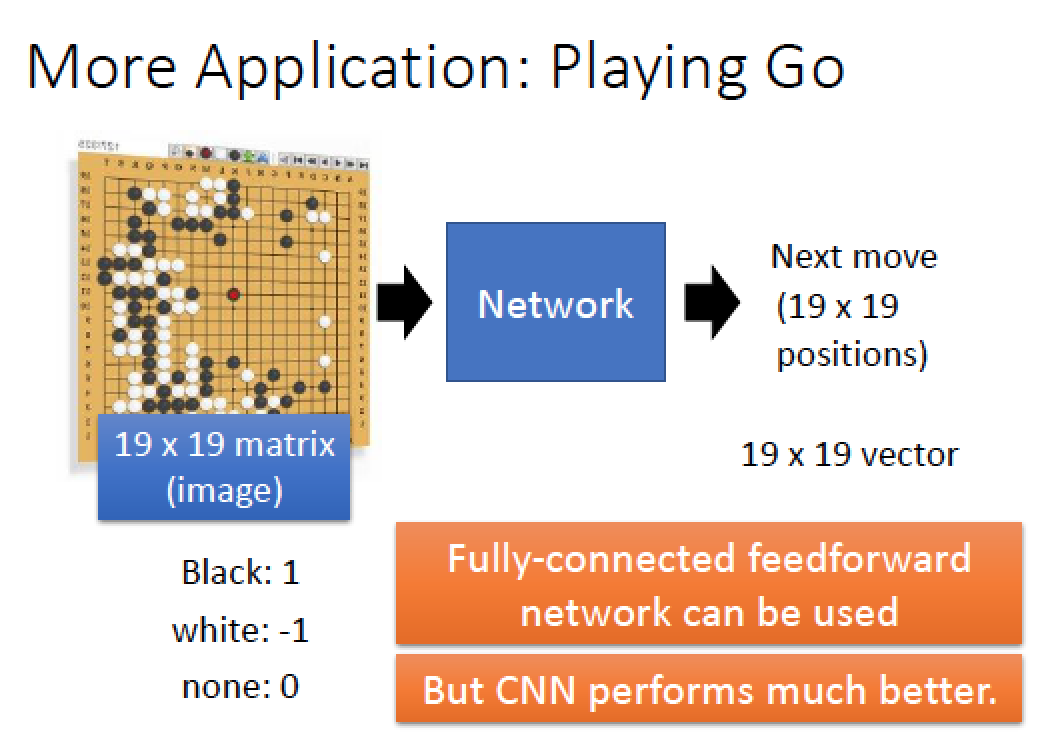
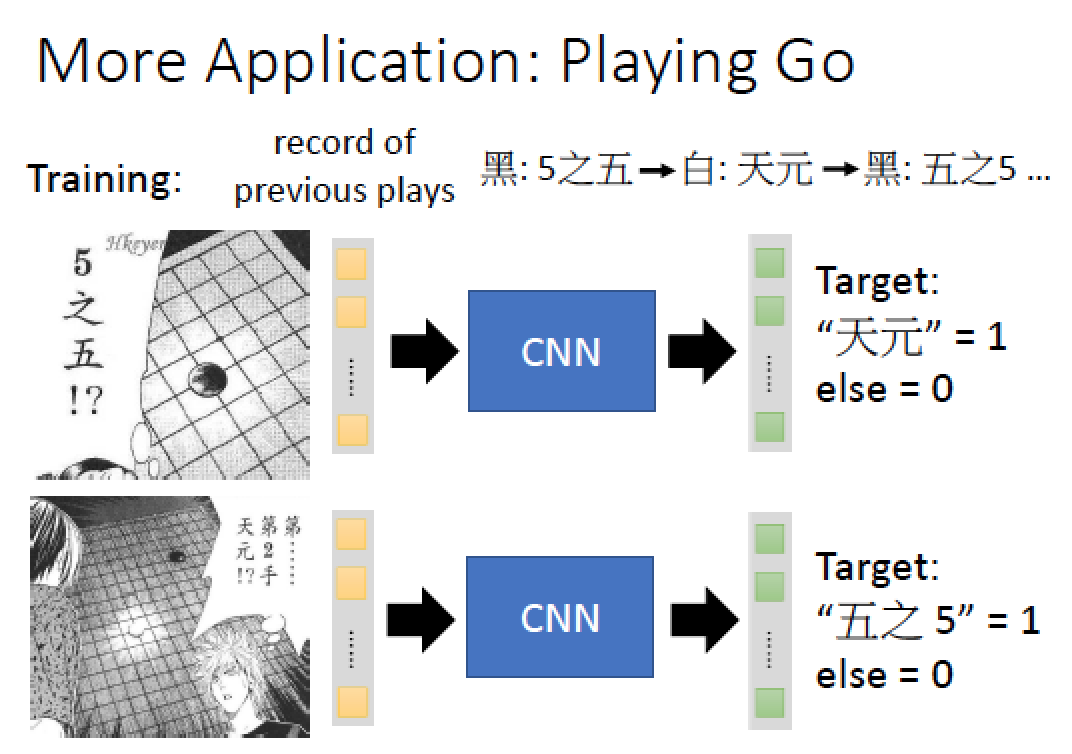
把整盤棋當成一張 image 19x19 然後 output 出下一步要下哪裡就結束了!
|  |

什麼時候可以用 CNN 呢?
要有 image 該有的特性才能用!
image 上某些 pattern 比起整張圖小得多
→ 圍棋上也有 pattern 比整盤棋小 ex.叫吃
image 上同樣的 pattern 會出現在不同位置,但是太婊同樣的意義
→ 圍棋上的 “叫吃” 也是相同的概念!
| 
但是 image 可以透過 Max Pooling 像解析度,圍棋上不行這樣做,解析度改片等於整盤棋就毀了!
所以根據 alpha go 的 paper 表示:他的 CNN 架構中沒有提到 Max Pooling !
根據圍棋的特性,我們本來就不適用 Max Pooling 這樣的架構來處理
|
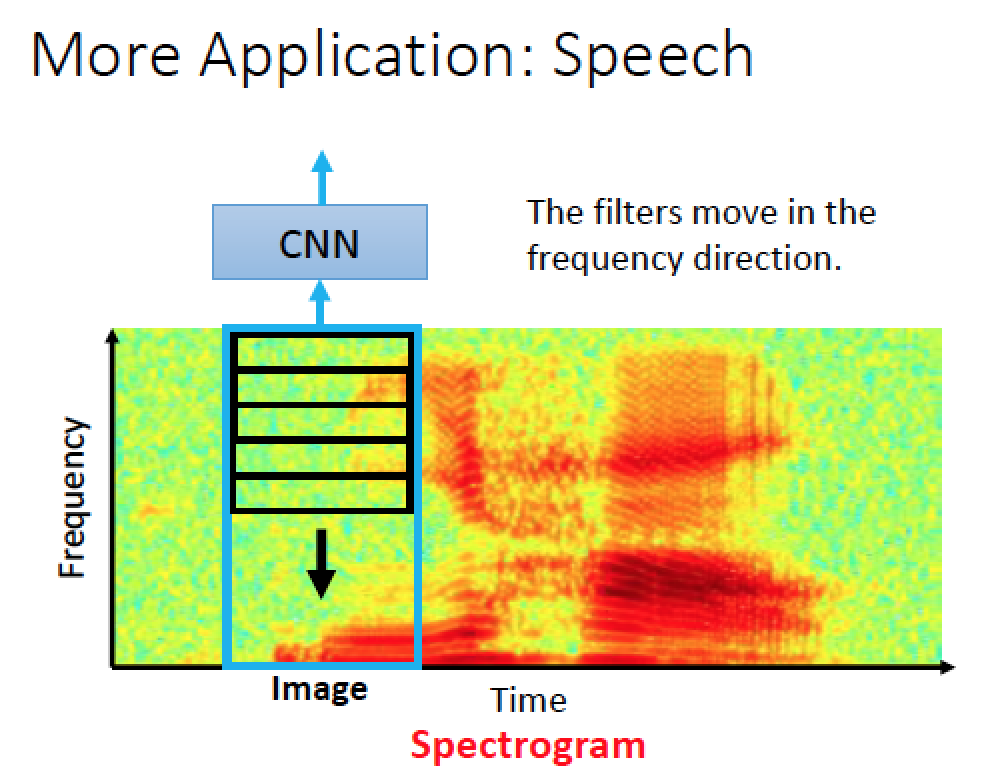
CNN 用於語音辨識:
左圖是 “你好” 語音的頻譜圖
我們使用 CNN 再圖上分析時,只會針對頻率的維度上移動做 convolution ,時間方向上做移動根據實驗,沒有太大的幫助,原因可能是他做完CNN 分析後,後面可能還會接 LSTM 的架構去做時間序列分析
而且男生說的 “你好” 跟女生說的 “你好” 可能只是在頻率上的 shift 而已,所以在 time domain 上的分析沒有太大的幫助
CNN 用在文字處理方面
例如 input 一組 word sequence 要 CNN 判別他是正面的還是負面的!
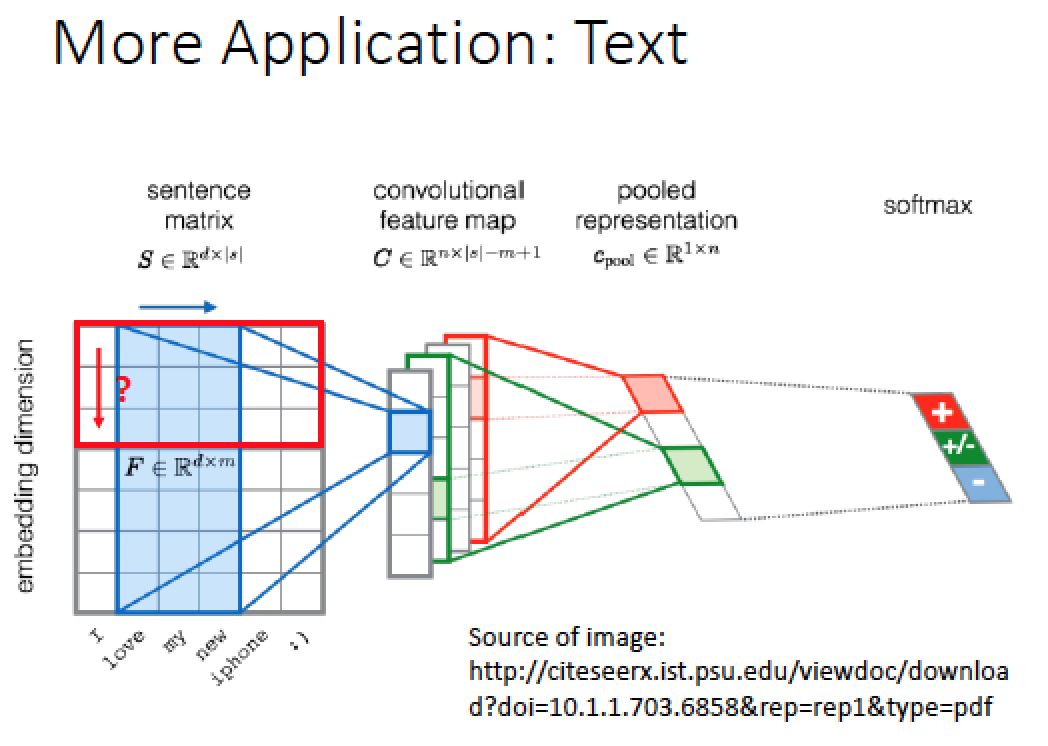
最左邊圖中的縱軸是 “word embedding”:將每一個 word 都用一個 vector 表示!
我們把一句話的每一個文字轉成 vector 然後我們使用 CNN Filter 做分析!使用多組 Filter 分析得到的 feature map 再經由 pooling 處理後丟到神經網路中訓練,最後產出結果 (正面 / 負面 / 中立)
→ 在使用 CNN 的 Filter 在文字處理的問題中, Filter 只會在時間的方向上移動 (藍色區塊),而不會在 word embedding 這個 dimension 上移動 (紅色框框)
因為在 word embedding 方向上不同 dimension 彼此是獨立的,所以在這個方向上移動 Filter 是沒有意義的
而 Filter 在時間方向上移動才能看出不同單字組成的句子產生的特徵!
 | 
這些 reference 是關於可以讓 CNN 學完後畫出的圖更 “漂亮” 接近人所想看到的版本
|






作者已經移除這則留言。
回覆刪除作者已經移除這則留言。
回覆刪除