[ML筆記] Why Deep ?
ML Lecture 11: Why Deep ?
本篇為台大電機系李宏毅老師 Machine Learning (2016) 課程筆記
上課影片:
https://www.youtube.com/watch?v=XsC9byQkUH8
課程網 (投影片出處):
http://speech.ee.ntu.edu.tw/~tlkagk/courses_ML16.html
上課影片:
https://www.youtube.com/watch?v=XsC9byQkUH8
課程網 (投影片出處):
http://speech.ee.ntu.edu.tw/~tlkagk/courses_ML16.html
神經網路為什麼越深越好?
首先先做個實驗來探討:
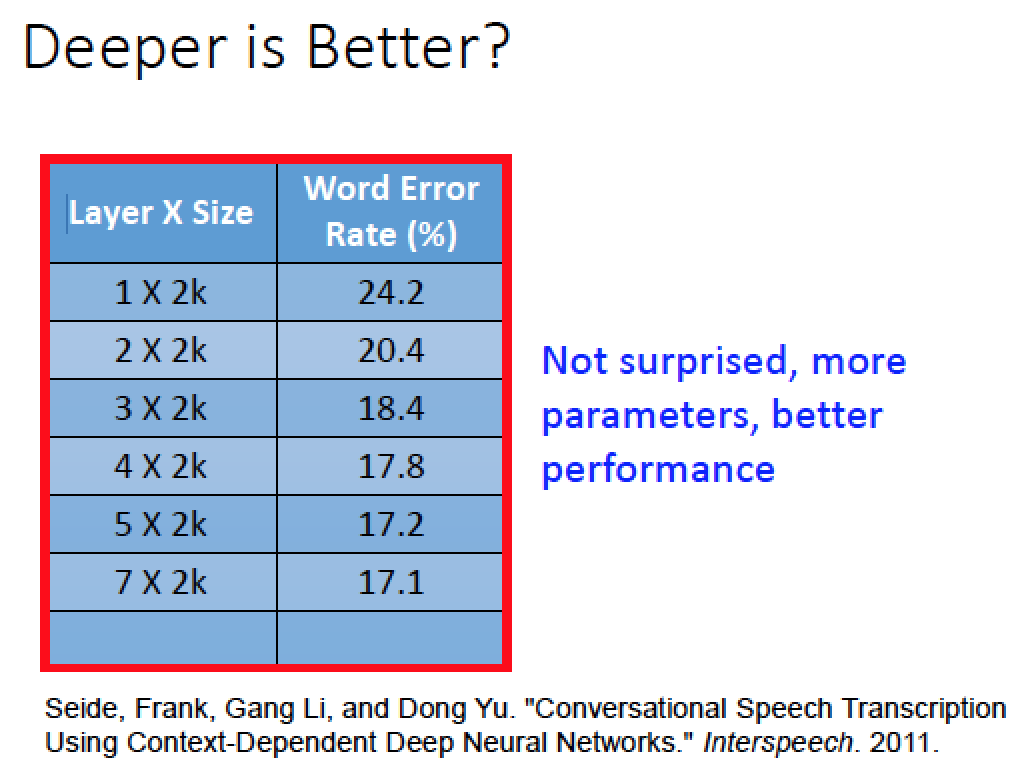 |
一層,每層 2000個 neuron 得到的 Error rate 24.2%
兩層,每層 2000個 neuron 共有 4000 個參數,得到的結果 Error rate 20.4%
依此類推 …
使用七層時,每層 2000 個 neuron 共有 14000 個神經元,得到的結果 error rate 降為 17.2 %
這個結果很直觀,因為我們使用的參數越多, Model 就會越複雜,越能 match 我們的 data
|
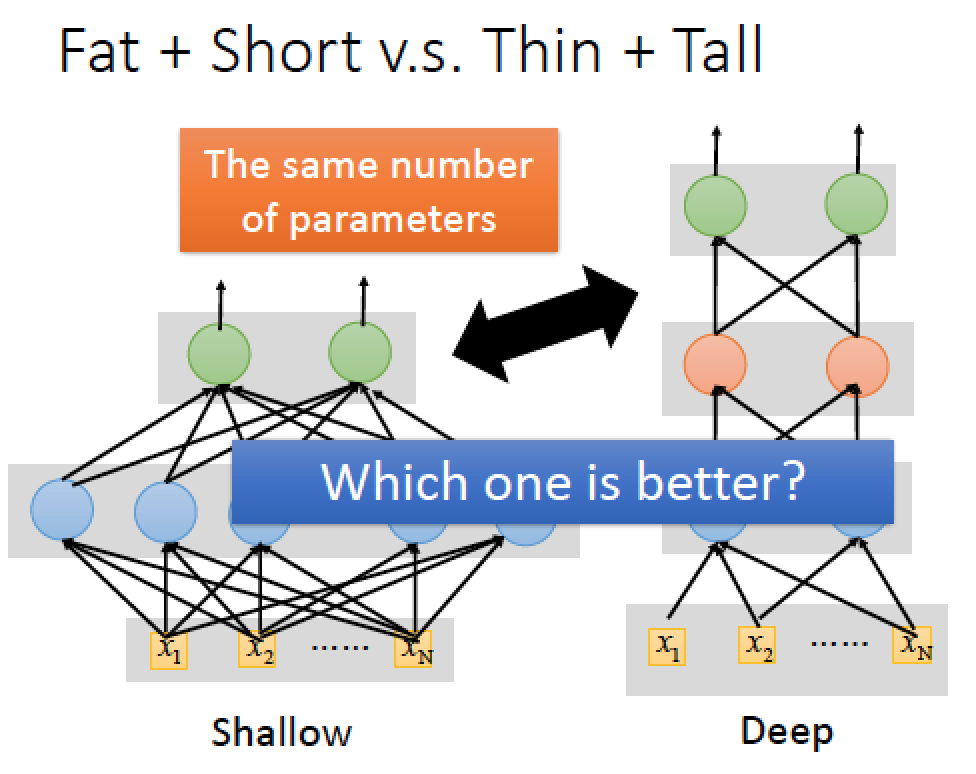
可以藉由使用 “相同數量” 的參數,但是分別用不同結構,下去比較 error rate
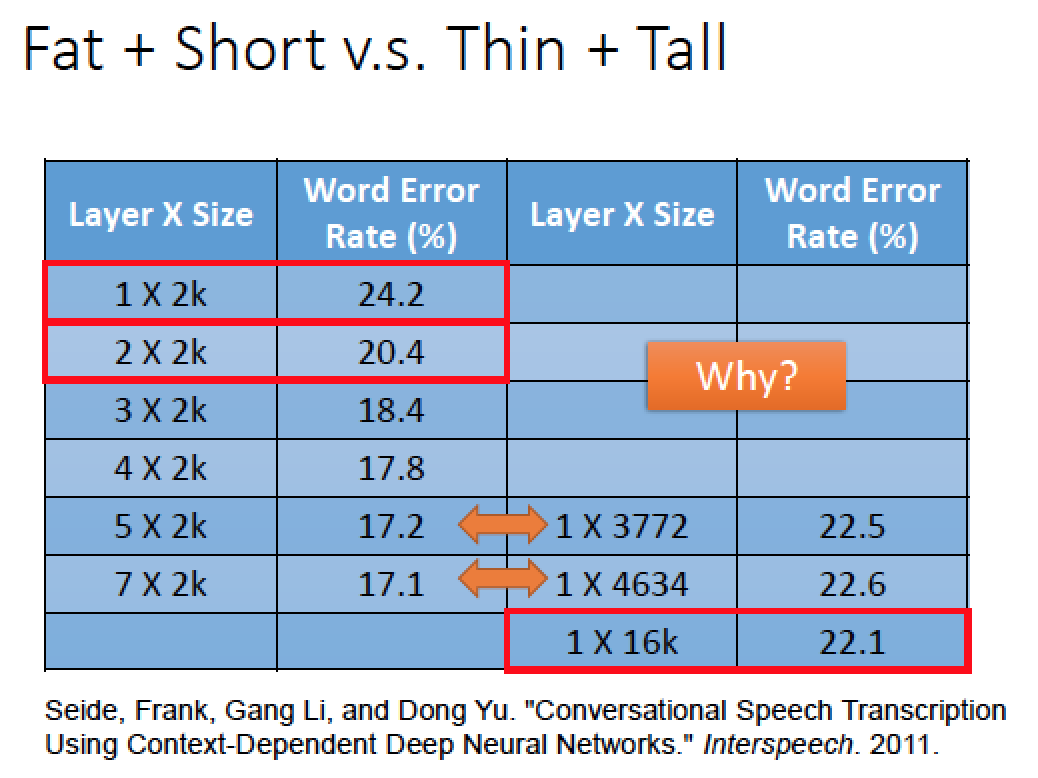
我們用 5 層,每層 2000 個 neuron
1 層 3772 個 neural 跟 5 層,每層 2000 個 neuron 他們的參數是接近的!
→ 根據實驗結果,我們初步發現,相同參數數量的情況下,架構越深越好
接下來的問題是,為什麼會這樣?
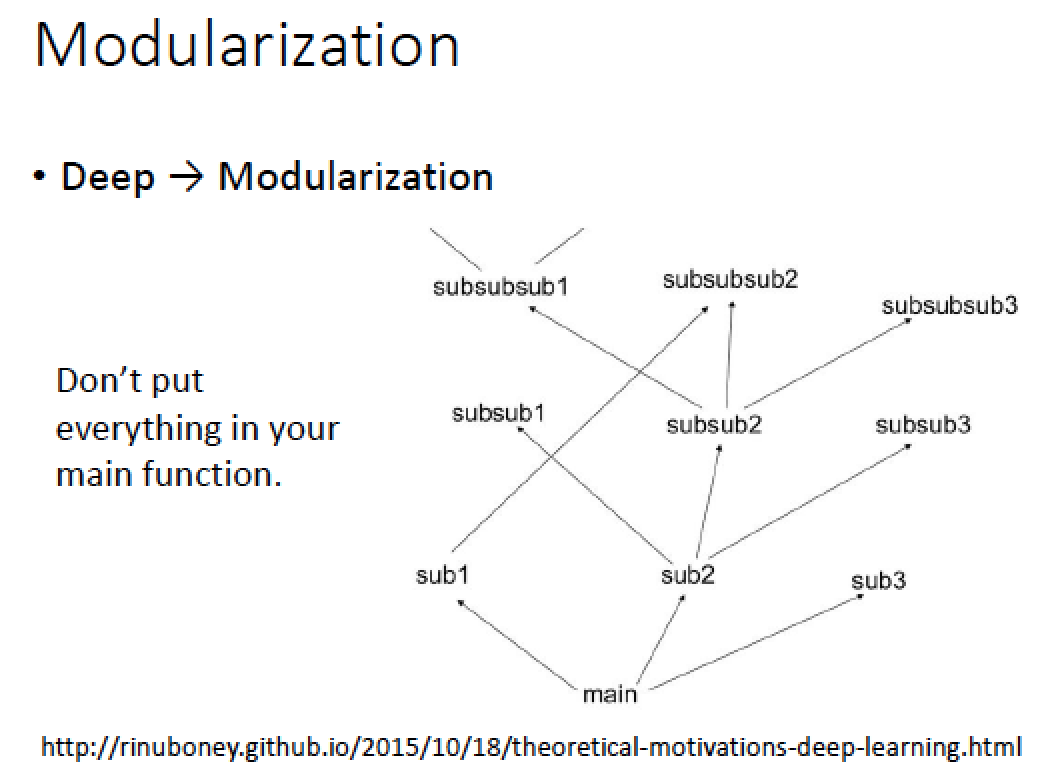
其實 deep 的架構就是模組化的動作
我們在寫程式時,不會把所有的程式都寫在 main function 裡面
我們會在 main 裡面 call sub-funtion,在 sub-function 裡面再 call sub sub function
這樣做的好處是,同樣的事情可以不用重複寫,結構化要做的動作
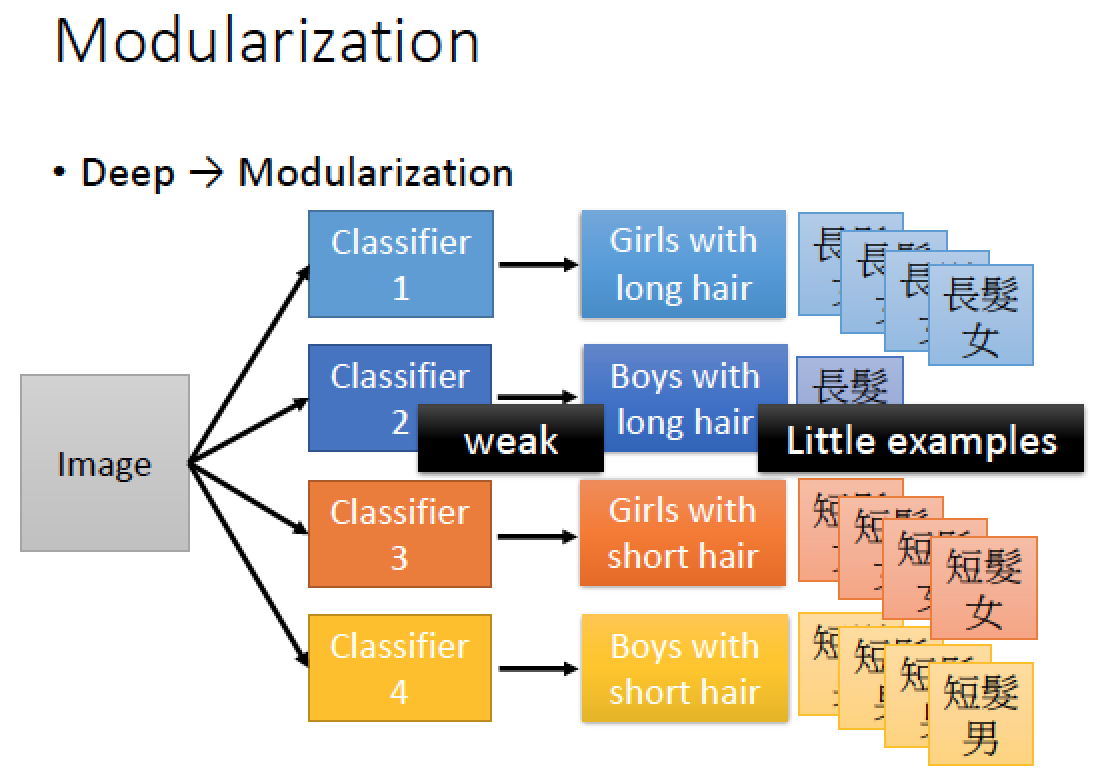
假設我們要針對,長髮女,長髮男,短髮女,短髮男來做分類
但是我們搜集到的資料當中,長髮男資料比較少,以至於我們對於該分類能力比較弱
該怎麼辦呢?
此時就可以用模組化來做這件事情!
模組化先把問題切成比較小的問題,先決定分類是男是女,然後再分類是長髮還是短髮,這樣我們在 train 基本的 classifier 時,都有足夠的 data 可以讓他訓練好!

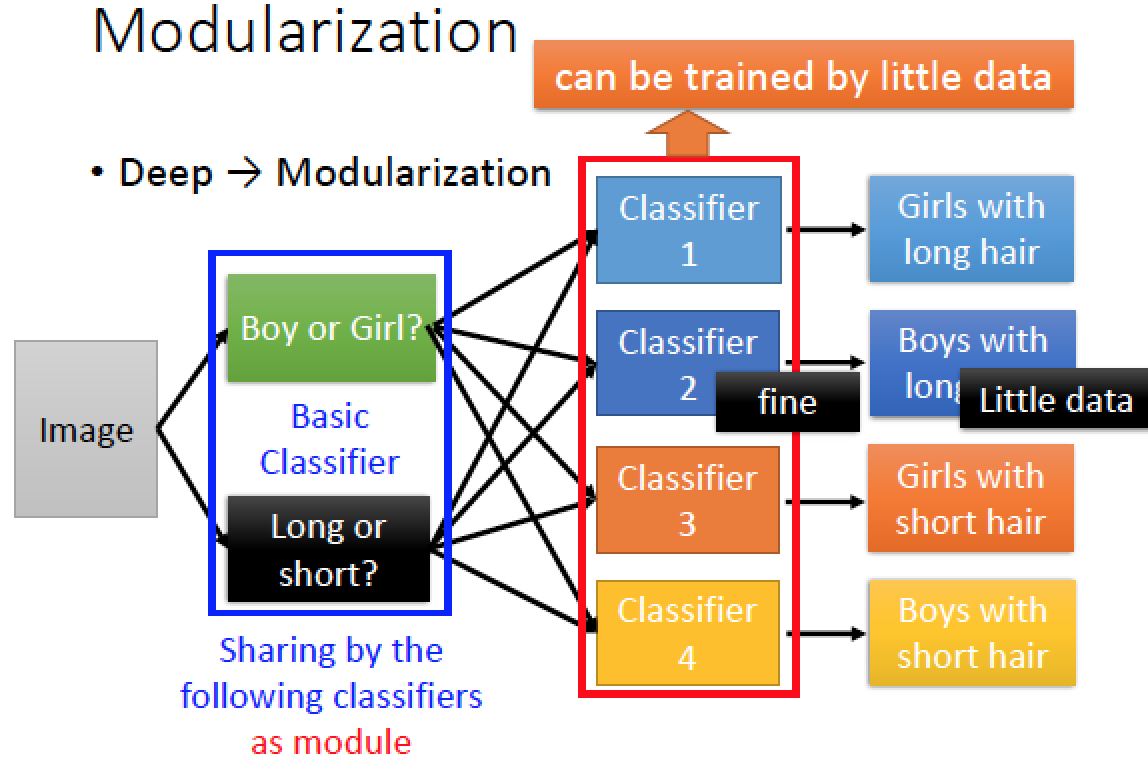
我們每一個 classifier 會把前面的基本的 Classifier 的結果當作 module 去 call 它的 output,
後面的 classifier 可以利用且共用前面的 module 結果,所以可以做比較簡單的事情,真正複雜的事情都被基本的 classifier 做掉了,而比較簡單的事情會比較好訓練,可以透過比較少的資料訓練好,然後再把大家做的簡單事情整體組合起來,就可以做到比較複雜的分類!

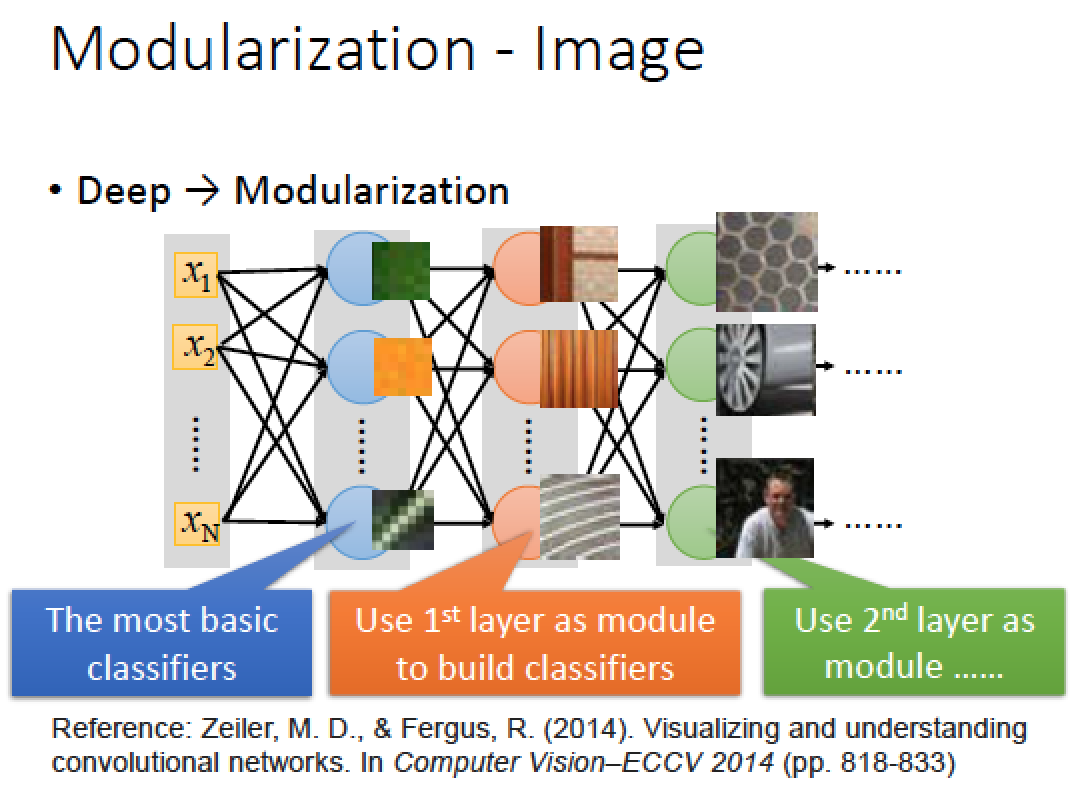
Deep Learning 架構中,每一層 neuron 都是 basic classifier ,第一層做比較簡單的事情,第二層就建構在得到第一層的結論後得延伸!
當然在做 Deep Learning 的時候,如何做模組化這件事情,是 machine 自動學到的!
做 Modularization 的好處是,讓我們的問題變簡單了,這就是模組化的精神
如果 Deep Learning 做模組化的時候,神奇的事情就是,Deep Learning 需要的 Data 比較少!
很多人都說 AI = Deep Learning + Big Data
實際上並不是這樣子的! → 假設我們擁有真正很大的 database ,大到全世界所有照片都在我的資料庫裡,那他屬於什麼分類直接 table lookup 就可以啦,不用 deep learning !
我們做 Deep Learning 實際上就是在做模組化這件事情,帶給我們的優勢就是,我們不需要太大量的 data 就可以訓練我們的 model
人類語音處理
Phoneme: 音素,語言學家定義的名詞,可以想成 “音標”

因為人類口腔的限制,我們沒有辦法每次發 u 音都會一模一樣
我們的發音會受到前後的影響
Tri-phone 的表達方式就是把 u 加上前面的字或是後面的字,不同的 model 來描述它
可以分成不同種的 states
語音處理的第一步驟:把連續的 feature 把它分成很多的 state

聲音訊號轉成 state 後再轉成 phoneme 再根據 phoneme 去轉成文字

在任何語言,例如中文或英文,他的 Tri-phone 超多如果每個 state 都要用一個 Gaussion 混合模型分佈來描述的話,Model 參數量會爆炸多
所以實際上的處理方式是:
有些 State 之間,他們的 distribution 是共用的,或是部分共用的
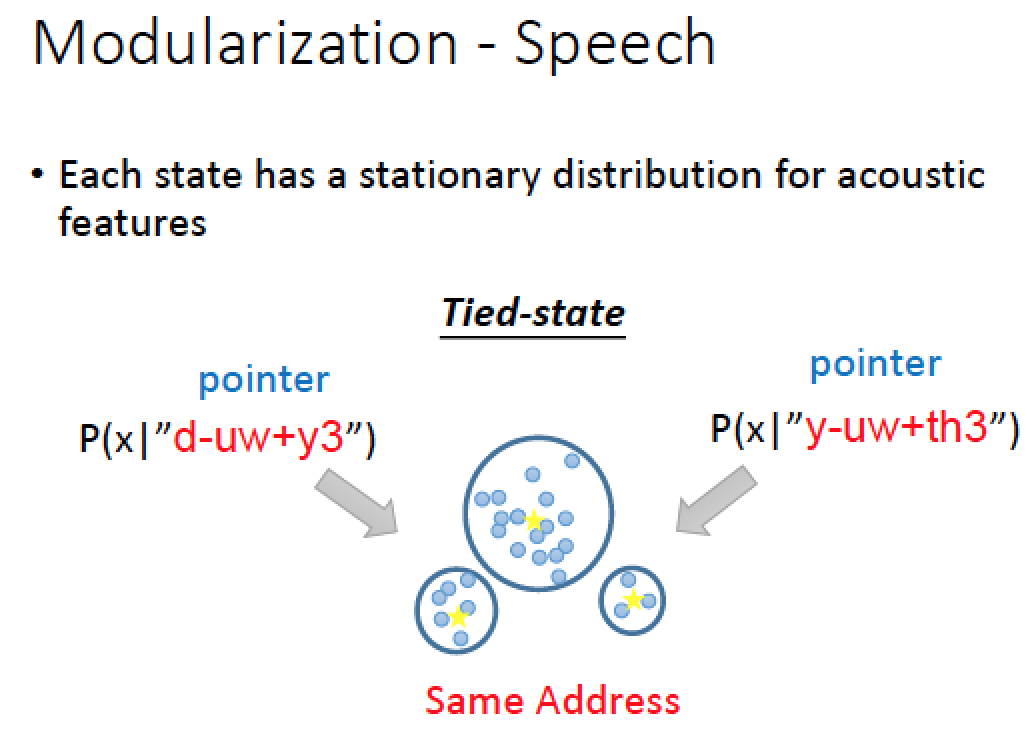
以上是傳統語音處理的做法,在 DNN 火紅之前的做法
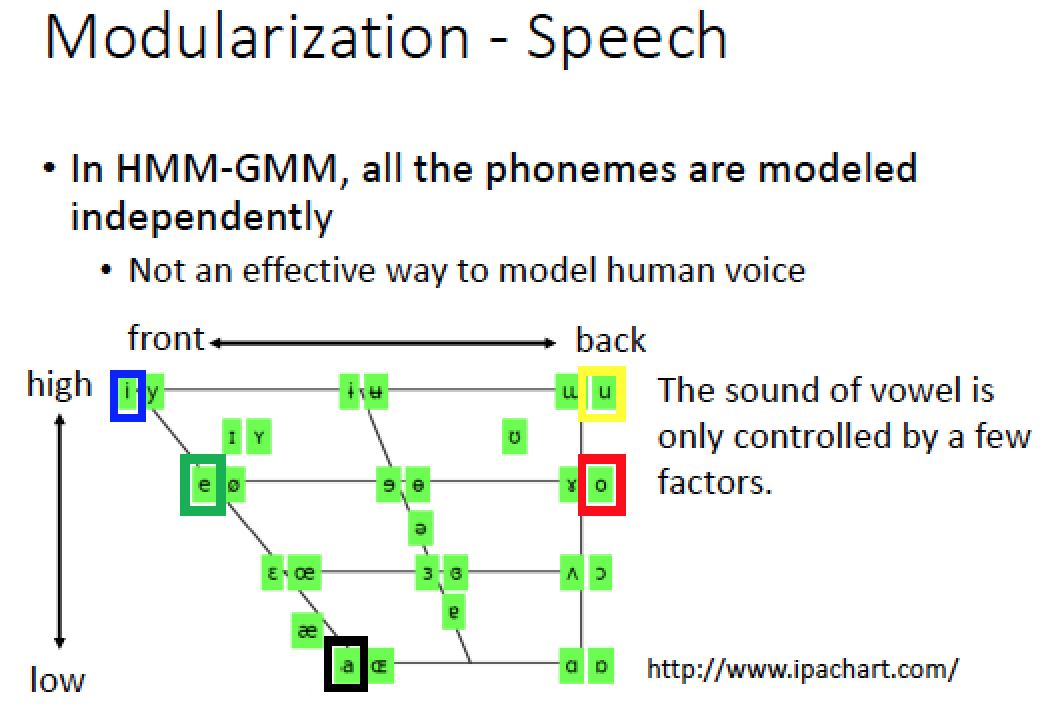
其實人類的聲音,不同的 phoneme 並非完全無關的,並非獨立的,舉例來說,圖上畫出人類語言所有的母音,其實母音的發音只受到三件事情影響:
一個是舌頭前後的位置
一個是舌頭上下的位子
另一個就是嘴型!
所以母音的發音只受到這三件事情影響,可用英文的母音來實驗感受一下 [a], [e], [i], [o], [u]
如果是 Deep Learning 怎麼做呢?
input:acoustic feature
output:這個 feature 屬於哪個 state
所有的 state 都共用同一個 DNN
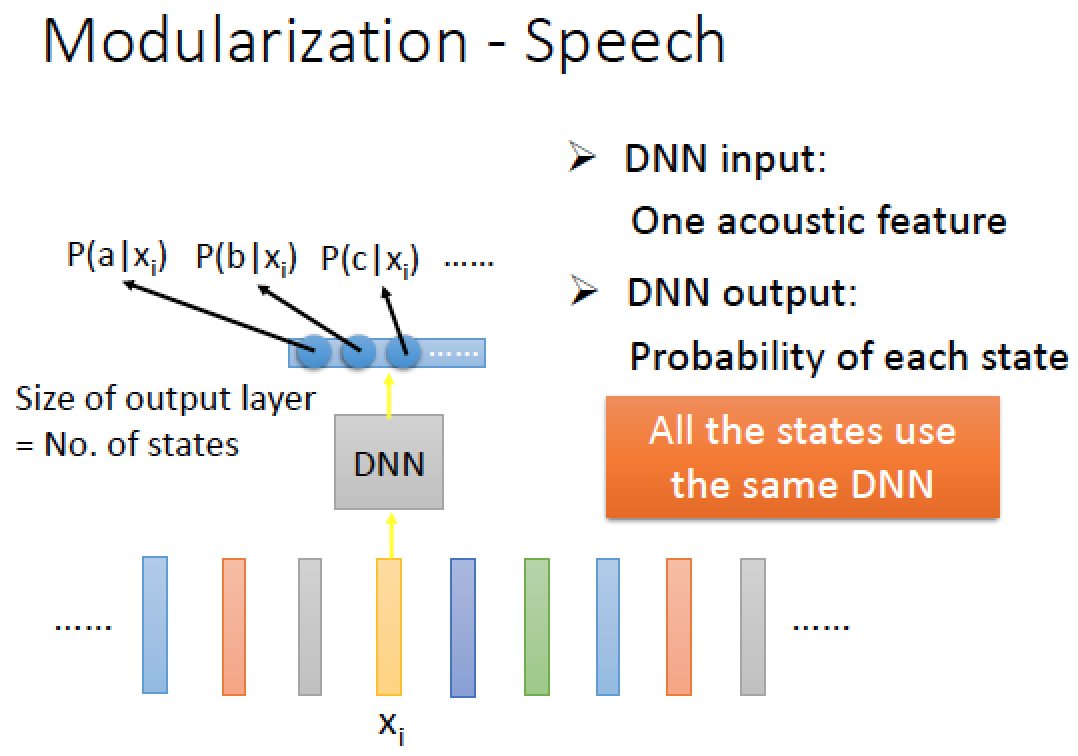
DNN 把所有個 state 通通用同一個 model 來做分類,會是比較有效率的方法!
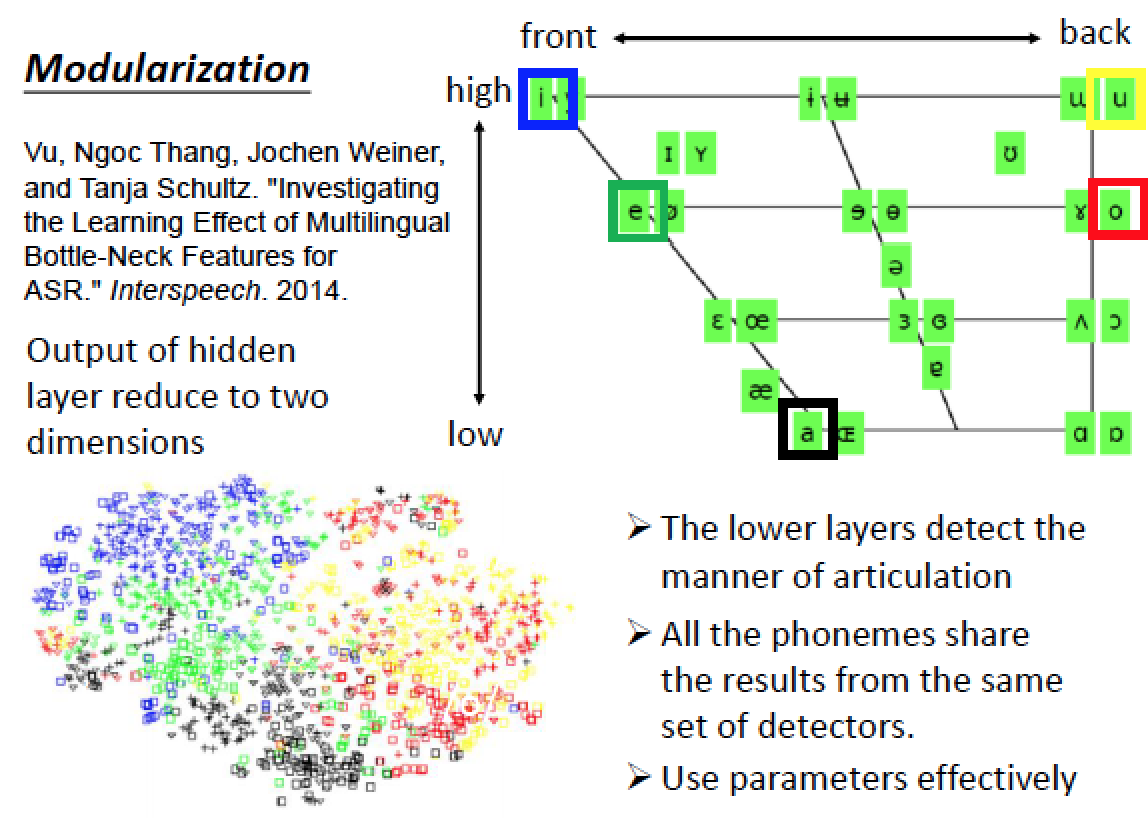
左下圖上的顏色分別代表五個母音,我們發現這五個顏色的分佈,跟我們右上的發音方式分類的分布相似!
所以 Deep Learning 比較 lower 的 layer 比較靠近 input 的那端,其實會共用同一組 detector 去偵測這些 form
回到很久以前的理論!
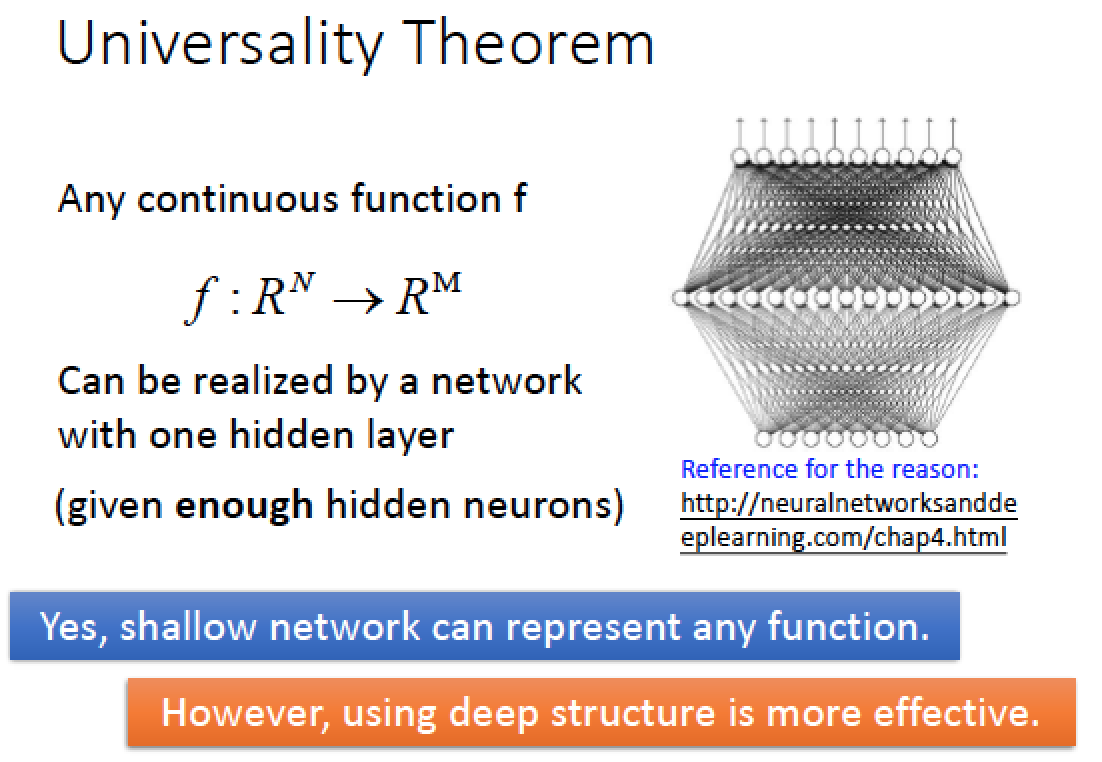
任何一個 continuous function 可以用一層 neural network 來完成!只要那一層 neural network 夠大就可以!
這是早期很多人放棄做 Deep Learning 的原因,因為只要一層就可以做出所有的 function
但是這個理論只告訴我們可能性,沒有告訴我們如何做比較有效率
我們用另一個例子來說明,會什麼 Deep 會比較 Powerful
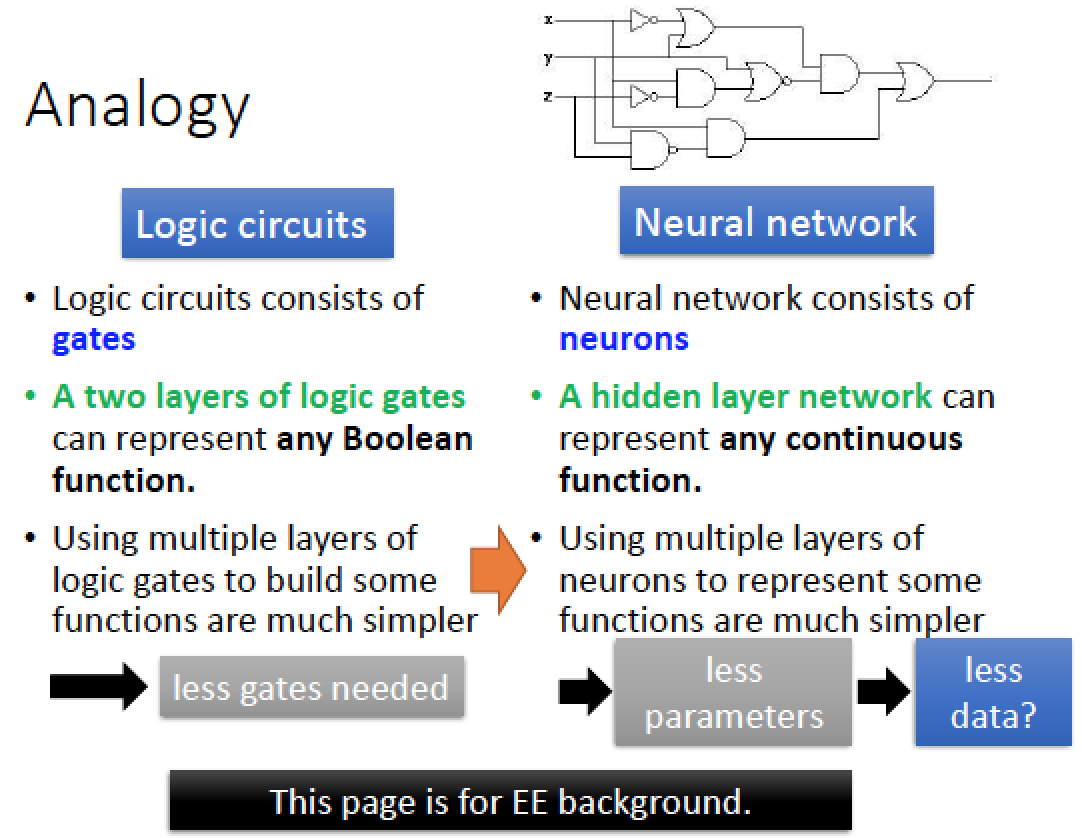
在邏輯電路裡面,有很多邏輯閘相連。
我們知道,只要兩層的邏輯閘,就可以描述任何的 boolean function
但是實際上我們在做邏輯電路時,我們並不會這樣做
當我們只用兩個邏輯閘來做,是比較沒有效率的,而我們用多層階層性的架構時,拿來設計電路,是比較有效率的!
所以雖然只有一層的 Neural Network 可以表示任何的 function ,但是當我們採用比較多層的 Neural Nerwork,就可以用比較少的 neural 就能完成同樣的 function,也使用比較少的參數,意味著比較不容易 overfitting ,只需要比較少的 data 就可以完成 train 的任務!

我們只用兩層邏輯閘,來做奇數偶數偵測時,我們如果 input sequence 長度為 d 個 bits,則我們需要 2d 個 gates 才能來描述這樣的架構
但是如果我們用下圖比較多層次的架構來做這件事的話,我們只需要 O(d) 個 gates 來做這件事情
以下再舉一個日常生活的例子來說明!
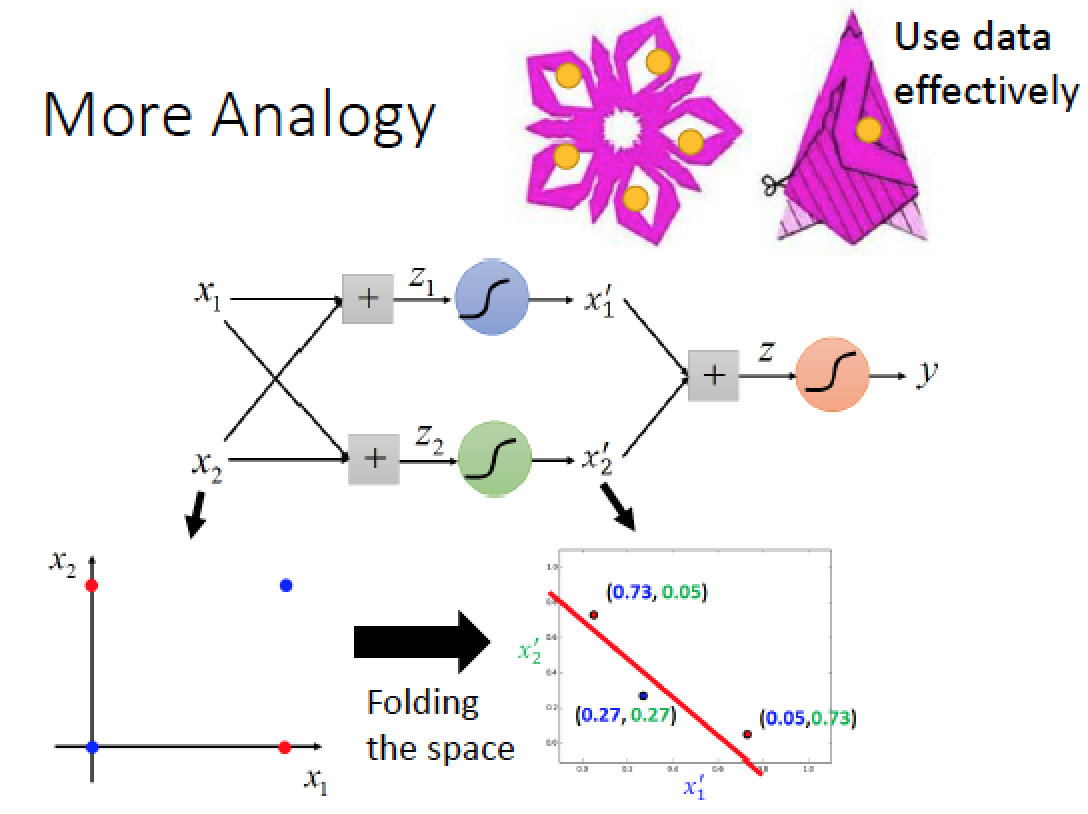
當我們加了一個 hidden layer 時,其實就好像是把原來的平面對摺了!
就好像是我們在剪窗花時,把色紙對折了!如果我們在對摺的狀況下戳一個洞,攤開時,相對應的位置都已經剪好了!
所以我們在色紙對摺多次的狀況下,把 training data 想要分類的區域剪出來,當我們攤開來時,我們就可以做出很複雜的區域分割!這是個比較有效率的方式來使用 data

另一個例子,我們有個 funciton 他的長相是地毯形狀的
如果資料在紅色菱形範圍 output = 1,藍色範圍 output = 0
為求公平評比,我們使用 1 層架構時,他是個很胖的 NN,使用 3 層 hidden layer 時是比較瘦的 NN,他們的參數總量是接近的!
然後我們分別用 100000 筆與 20000 筆資料去訓練,
根據實驗結果,我們發現比較瘦比較深的 NN 他的結果圖比胖的 Network 還要好
雖然在資料少的情況下,比較深的 3 層的 NN 也會崩壞,但是他的崩壞是有次序的崩壞,比起只有 1 層胖的 NN 的崩壞情況好很多!
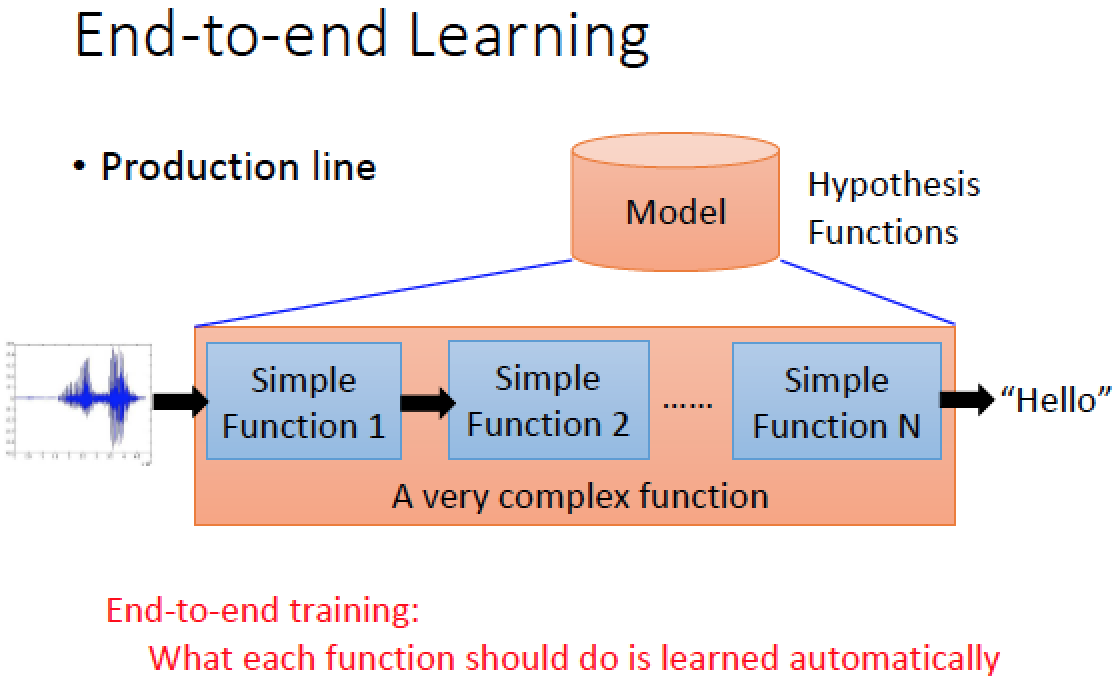
當我們只做 End-to-end Learning 時,我們只給 input 跟 output
至於每一層要做什麼樣的事情,是讓 Network 自己去學!

在傳統的語音辨識系統架構中,只有最後一個 GMM 是根據 output data 學來的
綠色架構當中,是根據古聖先賢的經驗所訂出來的方法!
但是有了 deep learning 以後
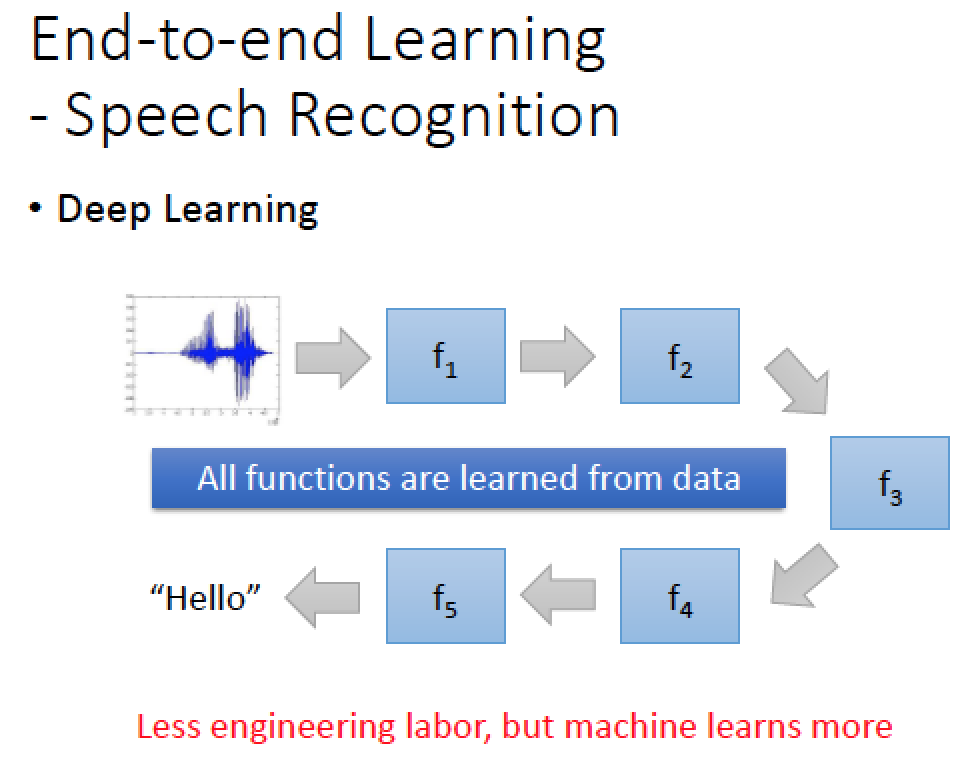
現在我們就直接讓整個架構自動藉由 output 結果來調整與學習!
唯一要做的事情就是疊 deep 一點,來模擬這些 function 來做的事情
那我們有辦法直接透過 input 訊號跟 output 結果來做語音辨識嗎?
根據 google 用硬幹法來做實驗,發現花了大把力氣,用很深的架構去 train 做出來的結果,也頂多只有跟傅立葉轉換的結果一樣好
所以在這個領域當中,要經過 NN 之前,還是先過一下傅立葉吧!
影像領域的處理也類似,就不贅述
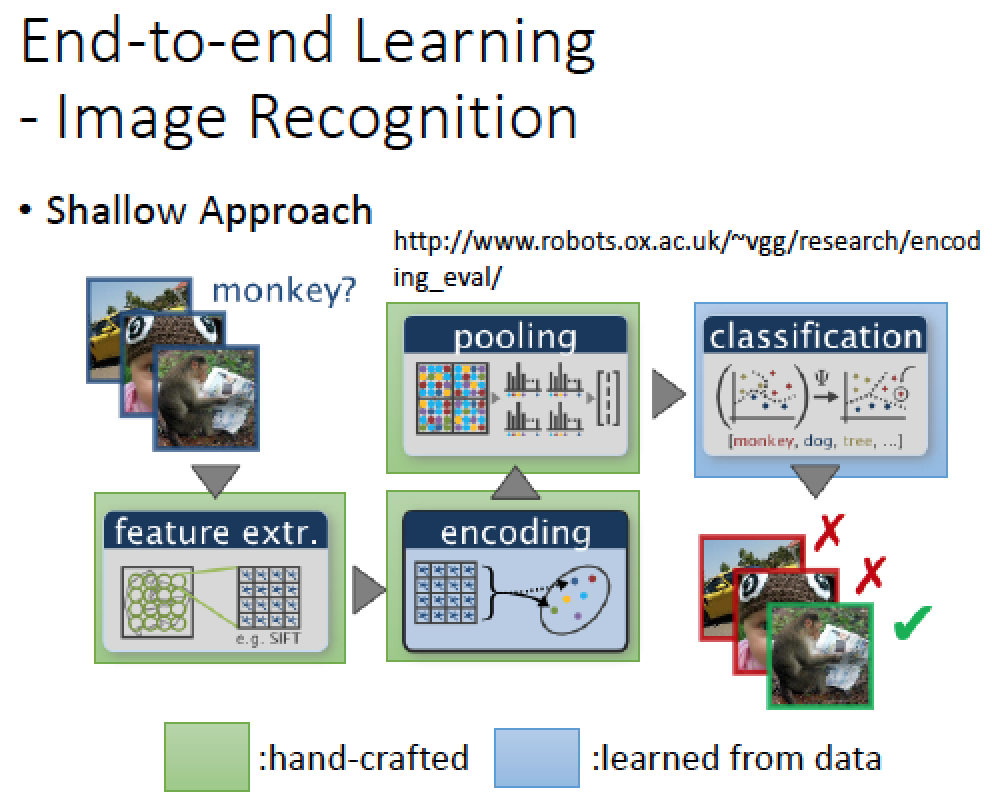 |  |
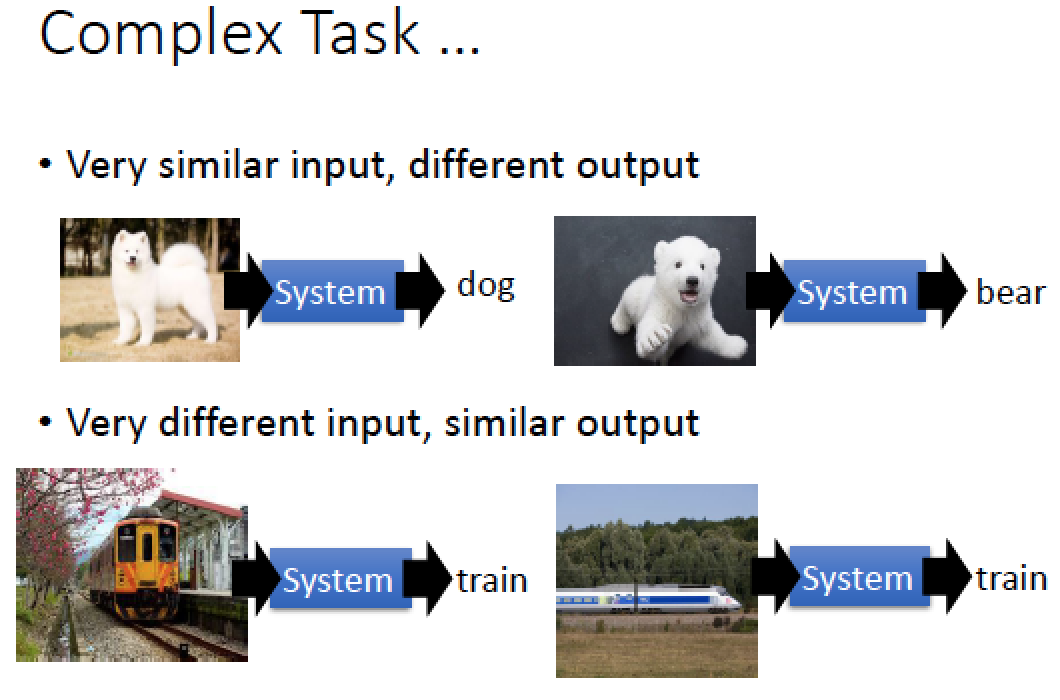
有時候...
看起來很像的東西其實是不一樣的,比如說白色的狗跟北極熊
或是看起來不像的東西其實是一樣的,比如說正面的火車跟側面的火車!
語音辨識領域的例子:

不同的人說同一句話,看起來完全沒有相關,塗上以不同顏色代表不同人說的話,我們只看第 1 層 Layer 的 output 結果一樣是亂的
| 
但是如果看第 8 個 Hidden layer output 時,可以發現,不同人說的 output 經過很多個 layer 的轉化後,他們被兜再一起了!
|
手寫數字辨識的例子:

隨著層數越深,不同的數字它們被分得更開








留言
張貼留言