[ML筆記] Introduction of Deep Learning
ML Lecture 6: Introduction of Deep Learning
本篇為台大電機系李宏毅老師 Machine Learning (2016) 課程筆記上課影片:
https://www.youtube.com/watch?v=Dr-WRlEFefw
課程網 (投影片出處):
http://speech.ee.ntu.edu.tw/~tlkagk/courses_ML16.html
Deep Learning 的發展史


第一步驟:設計 Model (Function)
一個 Logistic Regression 就是一個 Neural 把很多的連在一起就是 Neural Network

至於這些 Neural 怎麼連接呢? → 可以自己設計
最常見的做法就是全連接
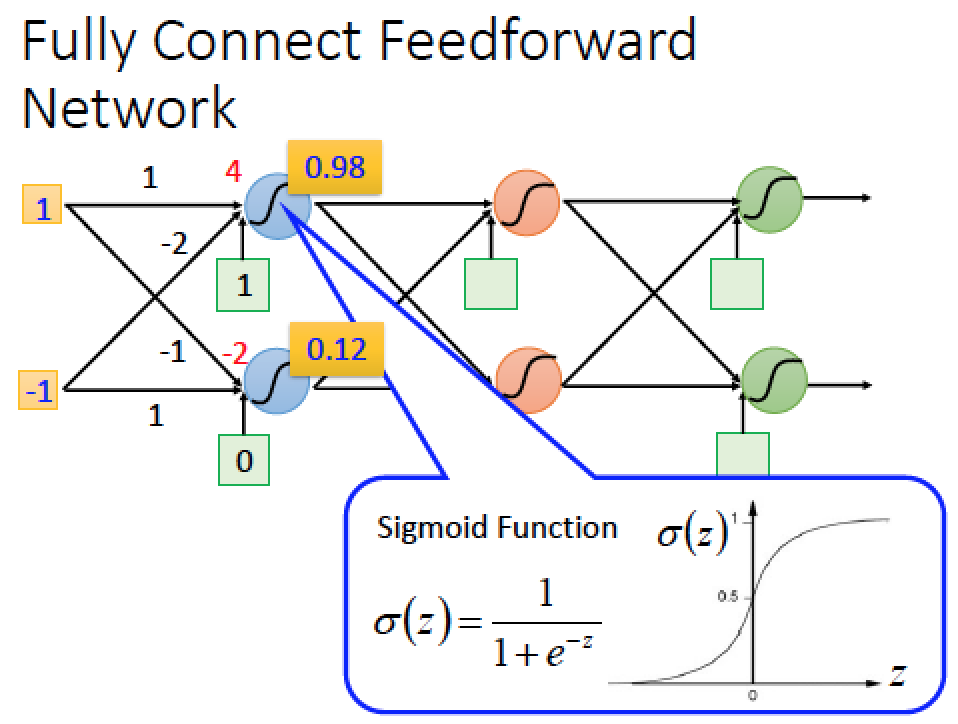
然後每個連接都有自己的 weight 跟 bias 最後在 neural 裡面過一個 sigmoid function
input,weight 與 bias 計算方法
1 * 1 + (-1)*(-2) + 1 = 4
1 * (-1) + (-1)*(1) + 0 = -2
得到的 4, -2 再拿去過 sigmoid function 然後得到 output 0.98, 0.12 做為下一層的 input
依此類推,一直算到最後一層 output 層
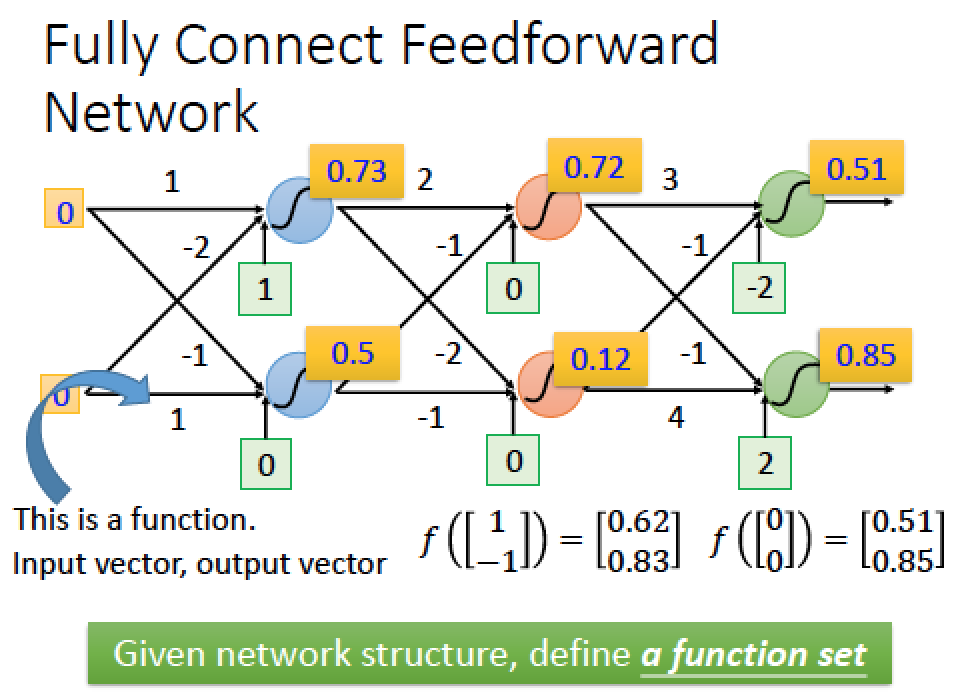
不同的 input 經過這樣得運算,會得到不同的 output 所以整個結構可以視為一個 function
只是這個 function 比較複雜,input 進去 function 可以得到 output
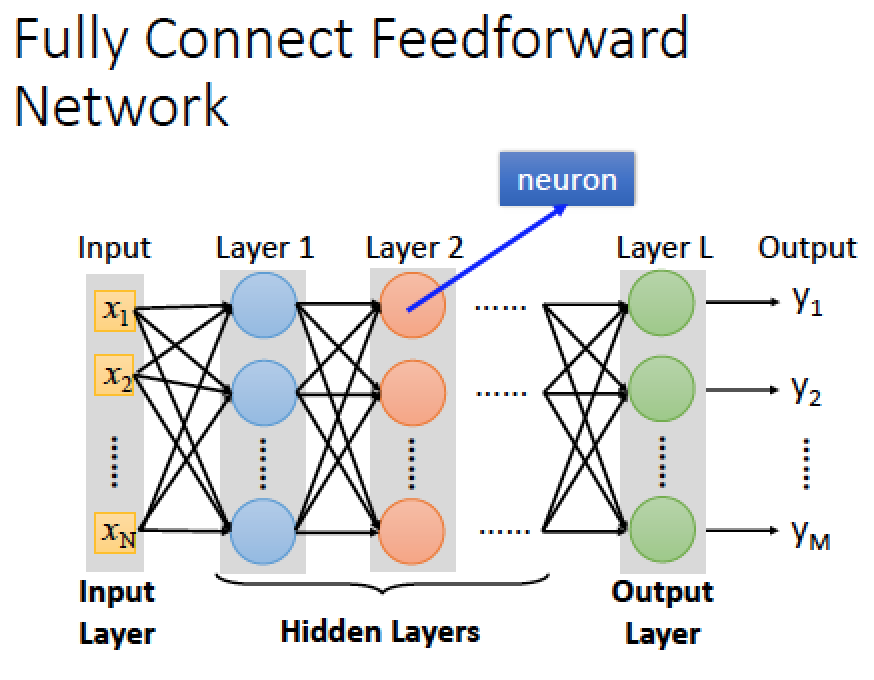
在這個結構下,第一層為 input layer,最後一層 Output Layer,中間的其他層為隱藏層
Deep 就是有很多 hidden layer
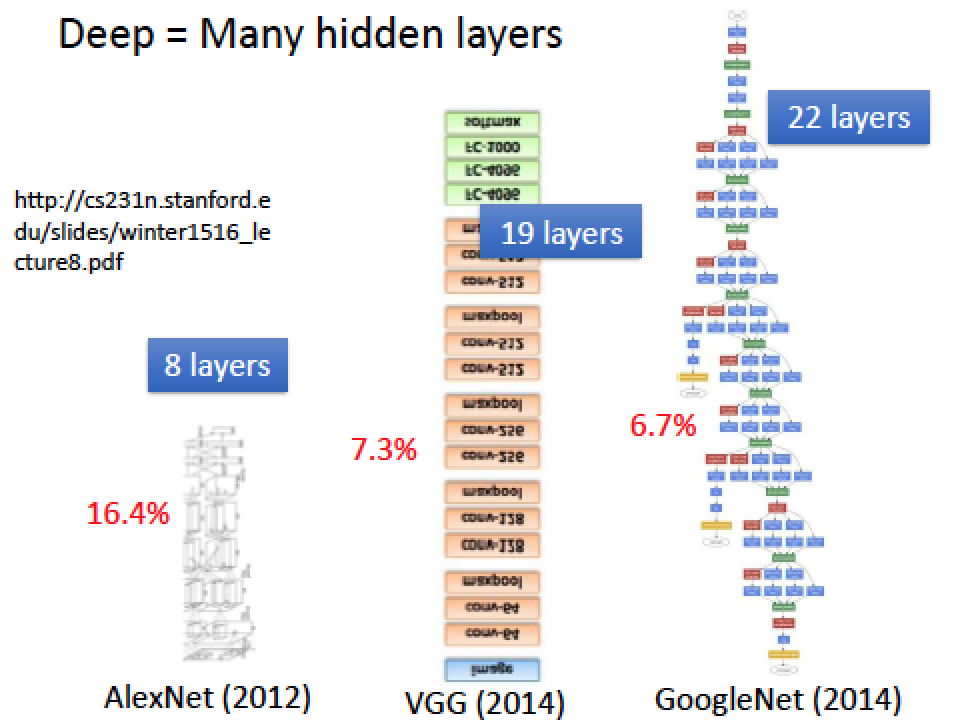 | 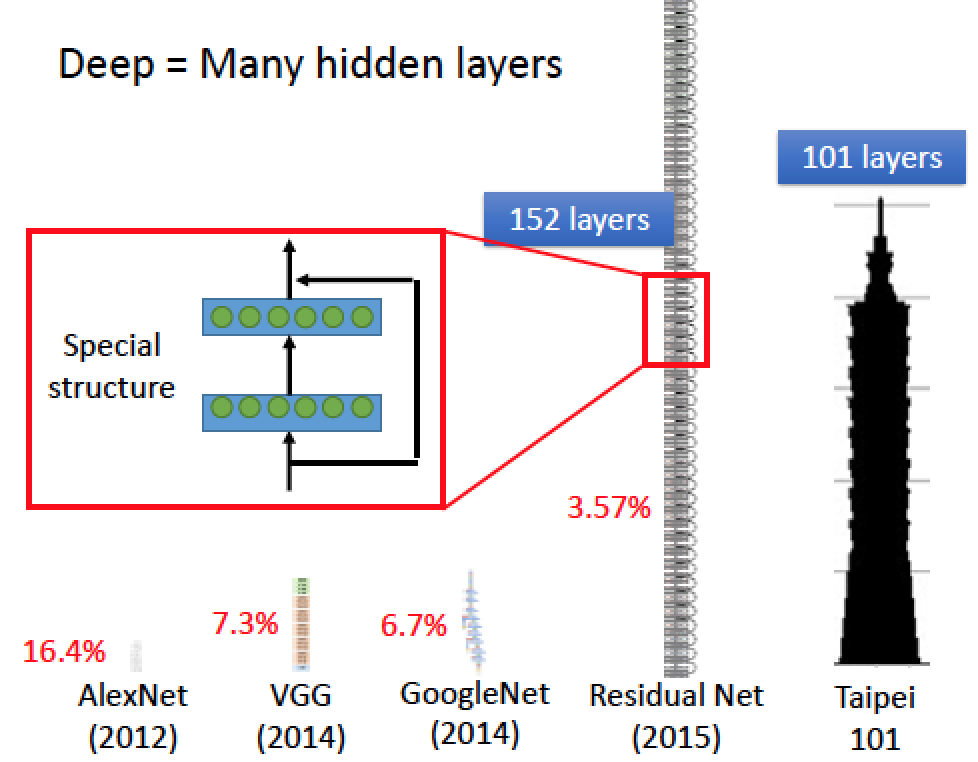 |
實驗結果顯示,隨著疊的層越深,誤差越小,準確度越高
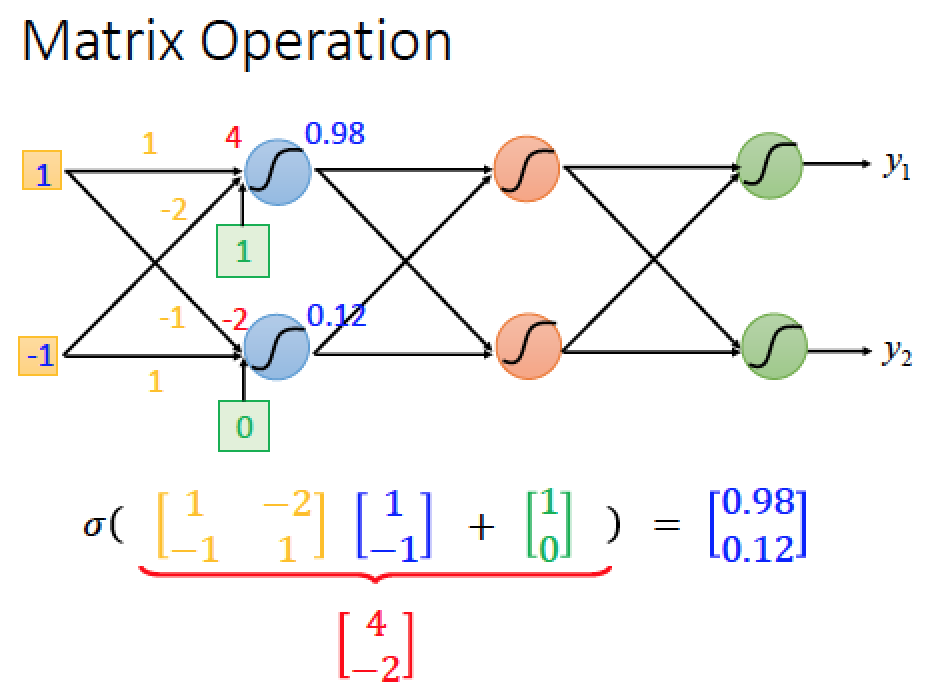
神經網路的運算可以視為矩陣運算


Weight W1 是一個 m x n 矩陣,input vector X 的維度是 n x 1 ,bias b1 維度是 m x 1
矩陣運算的部分可透過平行化來加速 (by GPU)

到 Output Layer 之前的部分,就可以看做是一個 Feature 的 Extractor
Output Layer 做的事可以視為一個 Multi-Class 的 Classifier
通常使用 softmax function
舉一個例子:手寫數字辨識
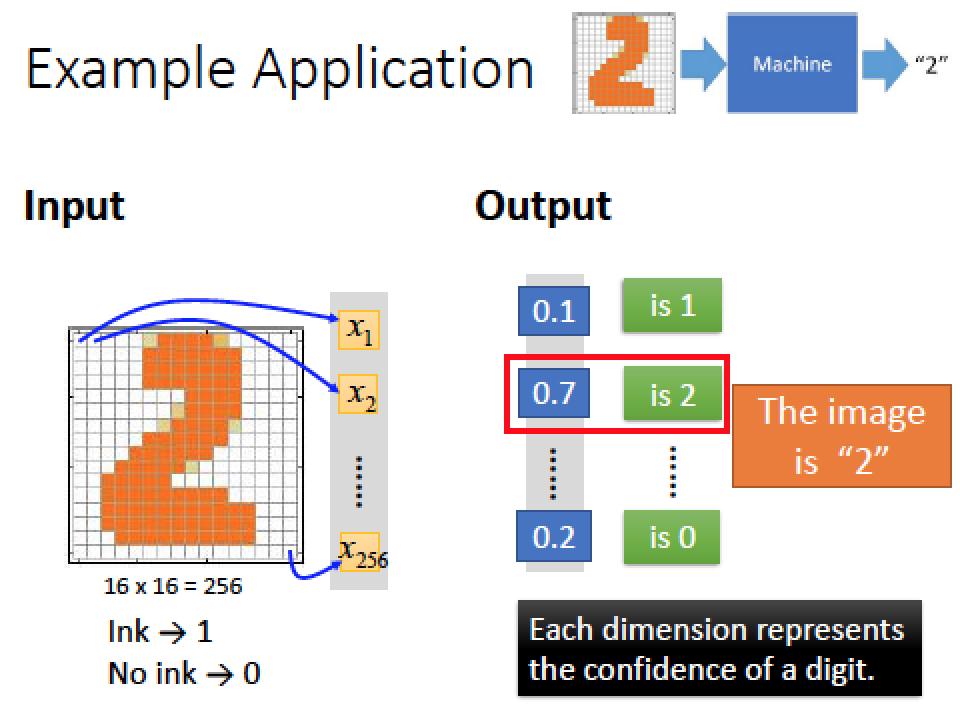
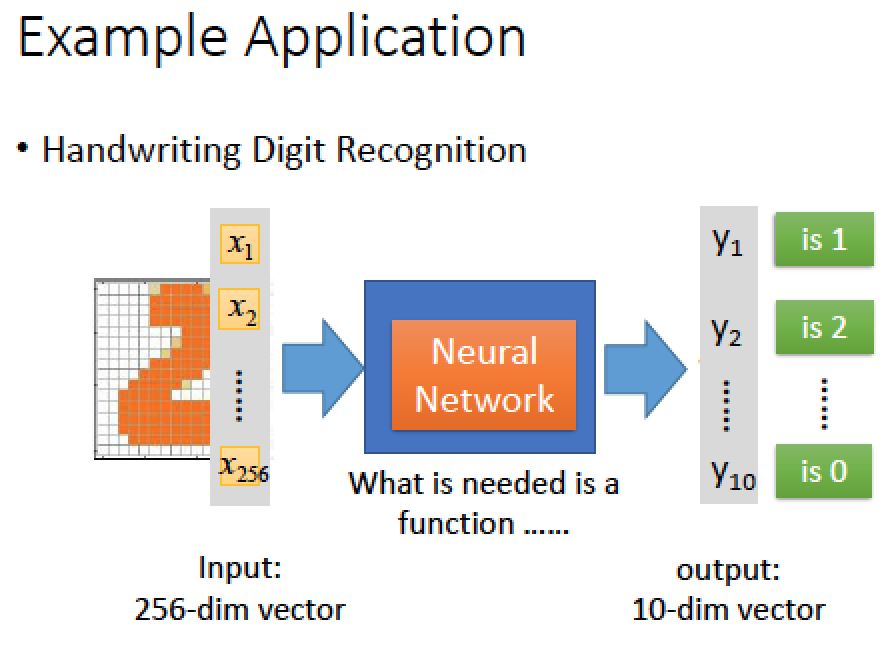
假設 image 的解析度是 16x16 所以共有 256 個 pixels 當作 input
我們想要的 output 就是十維度,每一個 dimemtion 都代表對應到一個數字的機率
上例當中數字 2 的機率最大是 0.7 所以我們的 output 辨識結果是 “數字 2”
那從 input 到 output 中間就是一個大的 function set ,這個 function 可以透過 NN 來實作
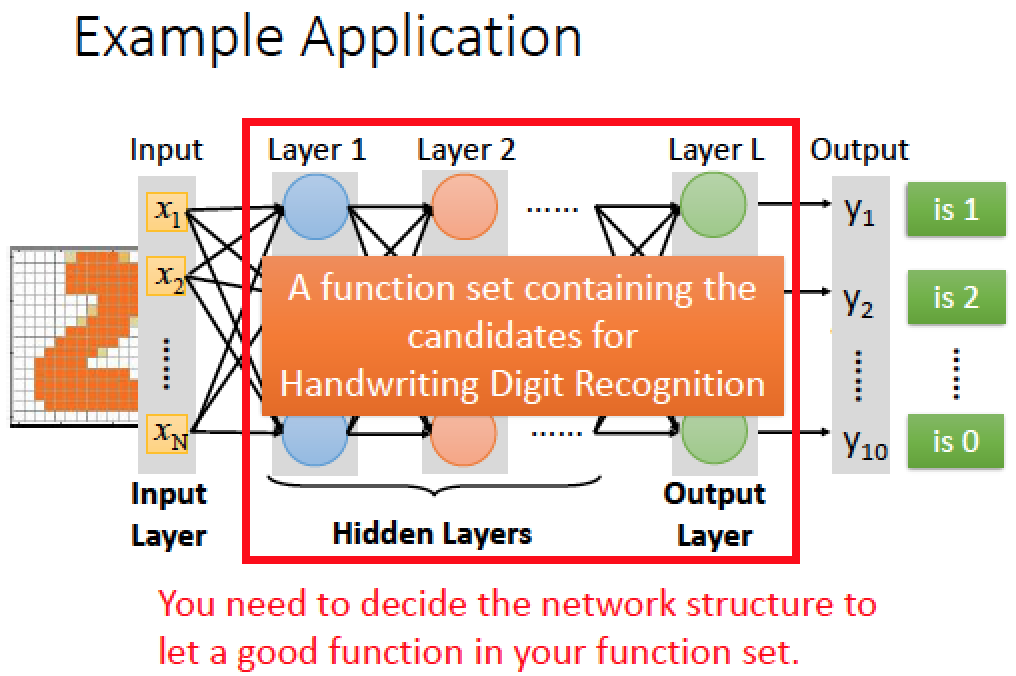
接下來我們要做的事情就是設計一個好的結構,用 Gradient Descent 挑出最好的 function
現在我們的 Model 為一個限制是 input 256 維, output 是 10 維
其他的部分,隱藏層要有幾層,結構如何連接,是沒有任何限制的
所以在 deep learning 的方法中,其實我們是從一個問題轉換到另一個問題
以影像辨識來說,一般的做法是找一組好的 feature 來辨識差異
到了 deep learning 時,問題變成要設計一個好的 Network Structure 讓 Machine 自己去找出一個好的 Function
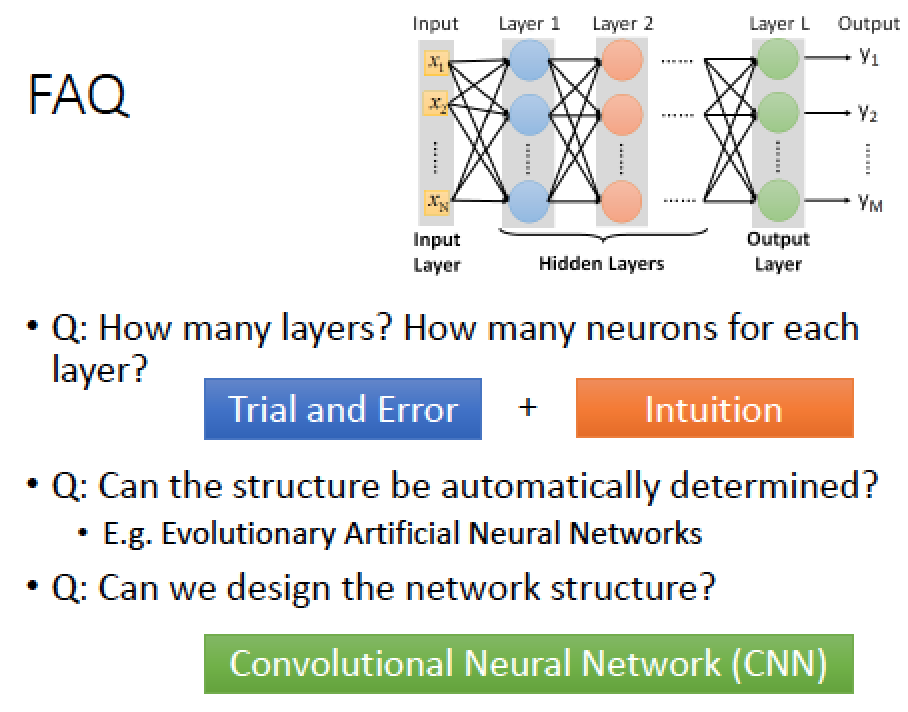
如何挑出好的結構呢?這個問題的答案就是,要自己動手實驗,還有靠經驗來設計
可以自己設計 Network Structure
第二步驟:如何計算 function 的好壞
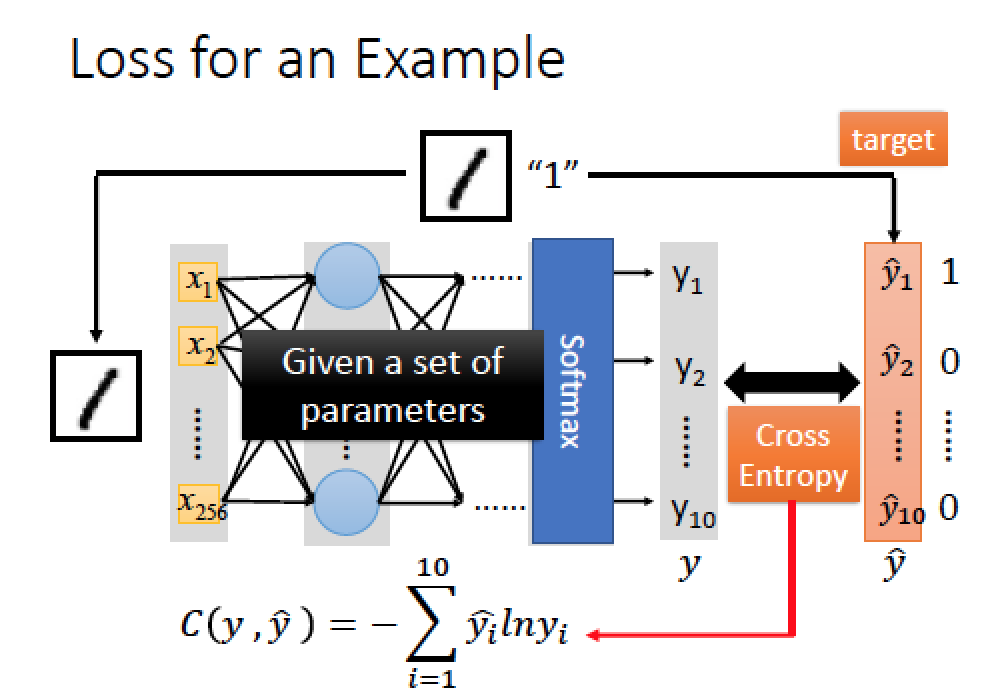 | 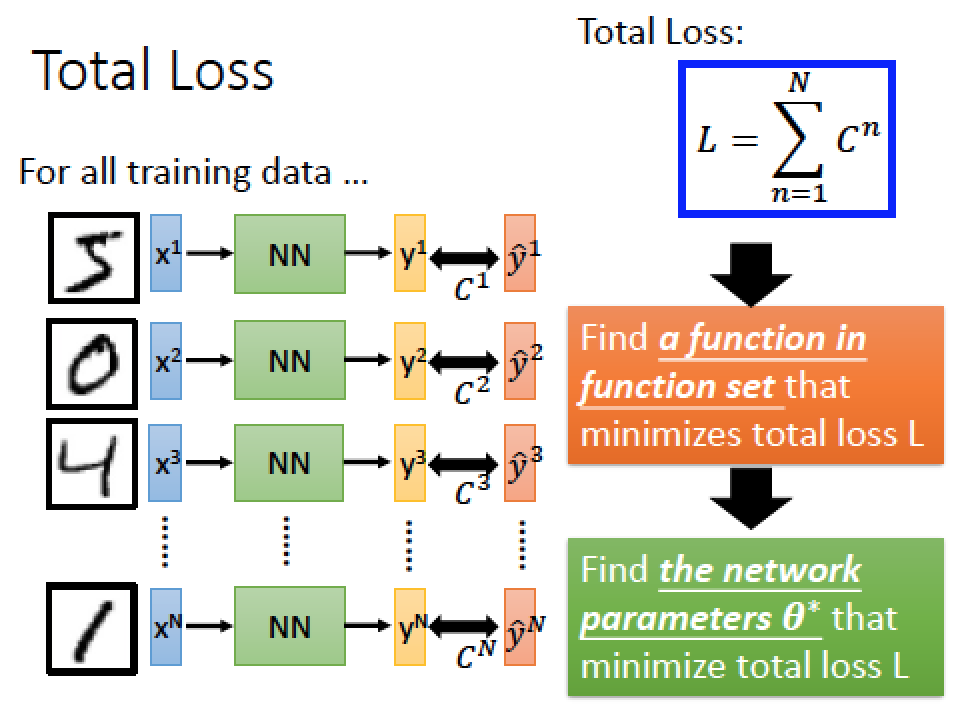 |
每一筆 data input 後計算出預測結果 y,並且跟真實的答案 y-hat 比較,計算 cross entropy
Total Loss 就是把一大堆 data 的 cross entropy 通通加起來,然後下一步驟就是在 funciont set 裡面找一組 function 可以 minimize total loss 或是找一組好的參數可以 minimize total loss
第三步驟:如何找到好的參數?
其實就是用 Gradient Descent
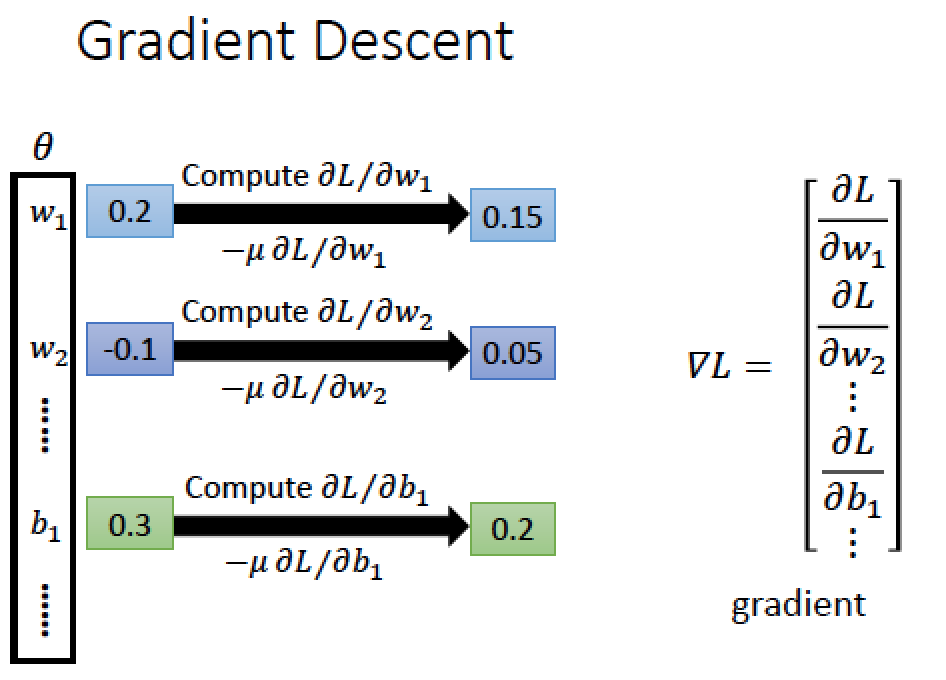

有效率計算偏微分的方法:backpropagation,目前有很多 tool kit 可以用,不用手算

Gradient Descent 實際上就像在玩世紀帝國,就是在未知的區域到處 try

討論:為什麼要 Deep 呢?

根據實驗結果,越 Deep 就會越準確
這個可以很直觀的理解,越 Deep 的 function 涵蓋的範圍就越廣

有個理論是這樣,任何一個continuous function,都可以用夠多的 hidden layer 做出來!
至於我們為何要 deep 而不是 fat 呢?這留給後續來討論






留言
張貼留言