[ML 筆記] Transformer(上)
Transformer 筆記(上)
本篇為台大電機系李宏毅老師 Machine Learning (2021) 課程筆記
上課影片:https://youtu.be/n9TlOhRjYoc
首先複習一下所謂的 Sequence-to-sequence (Seq2seq) Model 要解決的問題
想想有哪些任務的 input 是一個 sequence,
output 是由機器自己決定應該要輸出的長度呢?
案例:語音辨識
input:聲音訊號
output:由機器決定輸出的文字長度
案例:翻譯 中翻英
input:中文句子:你好 (2個字)
output:英文句子:How are you? (3個字)
案例:語音翻譯 英翻中
input:英文句子聲音檔
output:中文句子
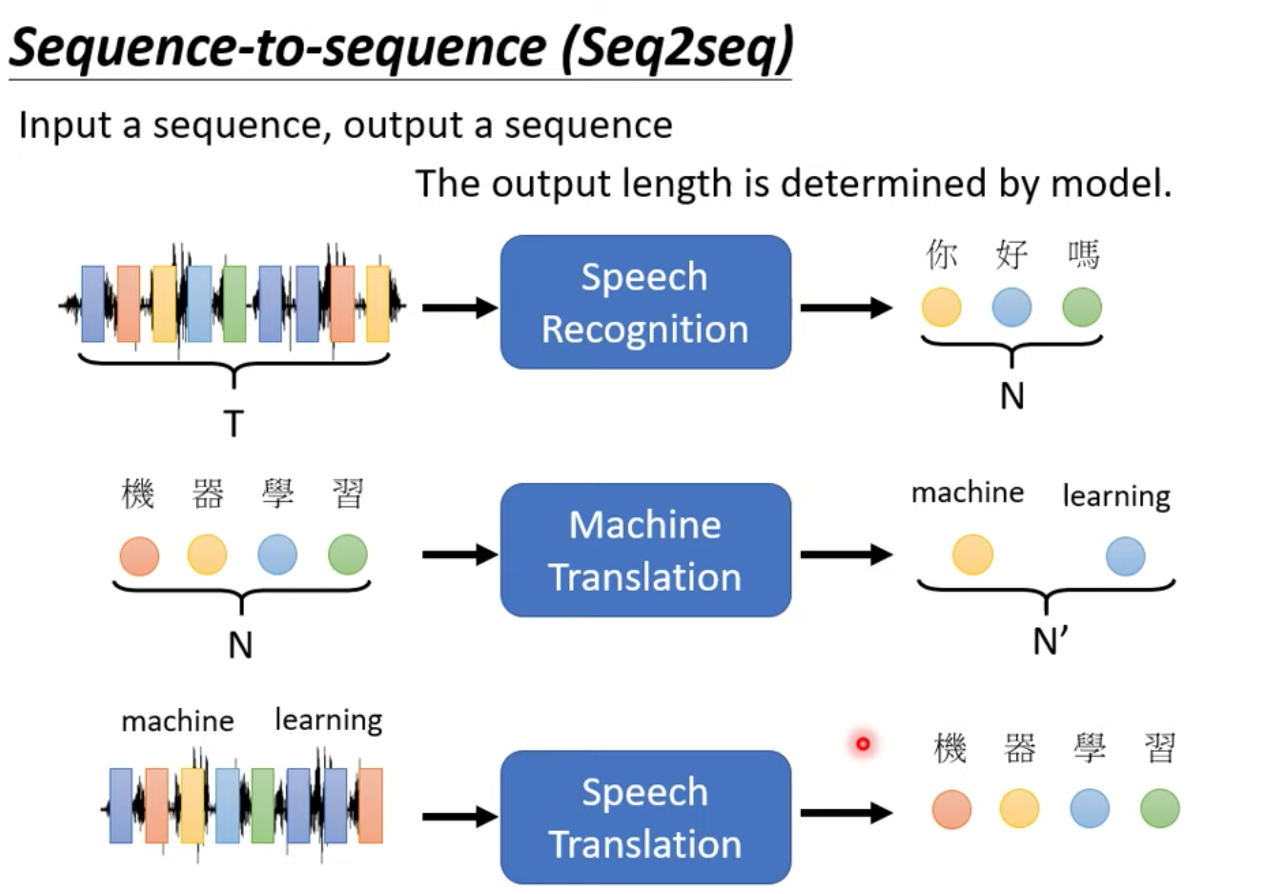
Seq2seq model 可以做到各式各樣的任務,但不一定能舉得最好的 performance
針對各式各樣任務做出的客製化的模型,往往會比單純用 Seq2seq 解來得更準

案例:想一想 Seq2seq model 如何應用在文法頗析任務上
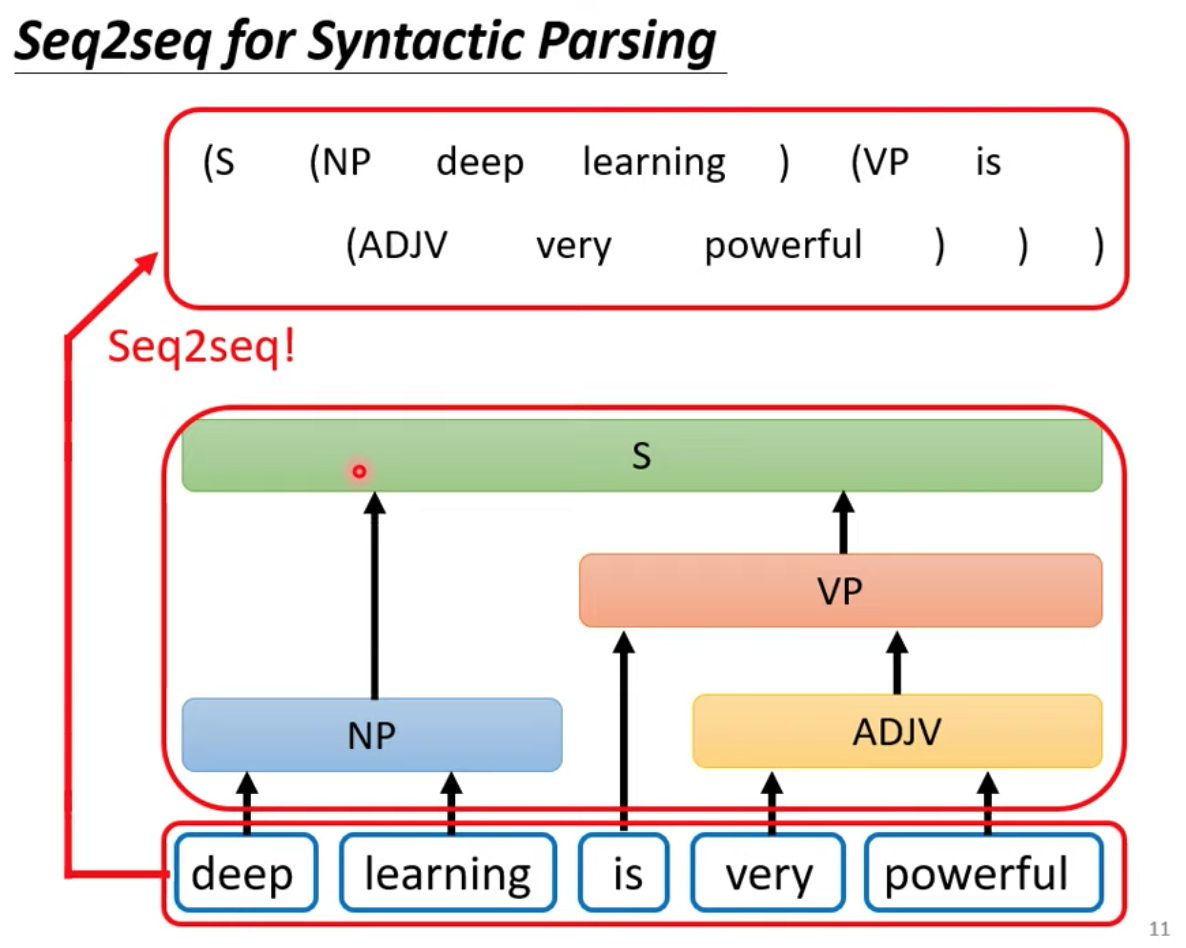
可以把文法分析的架構,encode 成一串 sequence ,這樣就可以當作 seq2seq model 的 output 端,用這個 seq2seq model 來解

相關論文附在這兒 https://arxiv.org/abs/1412.7559
案例:想想 Seq2seq 如何做 Multi-label Classification
讓機器自己決定,每篇文章要吐出幾個 tag,也就是 output 端可以是一個不固定長度的 Tag sequence 恰好適合用 seq2seq model 來解
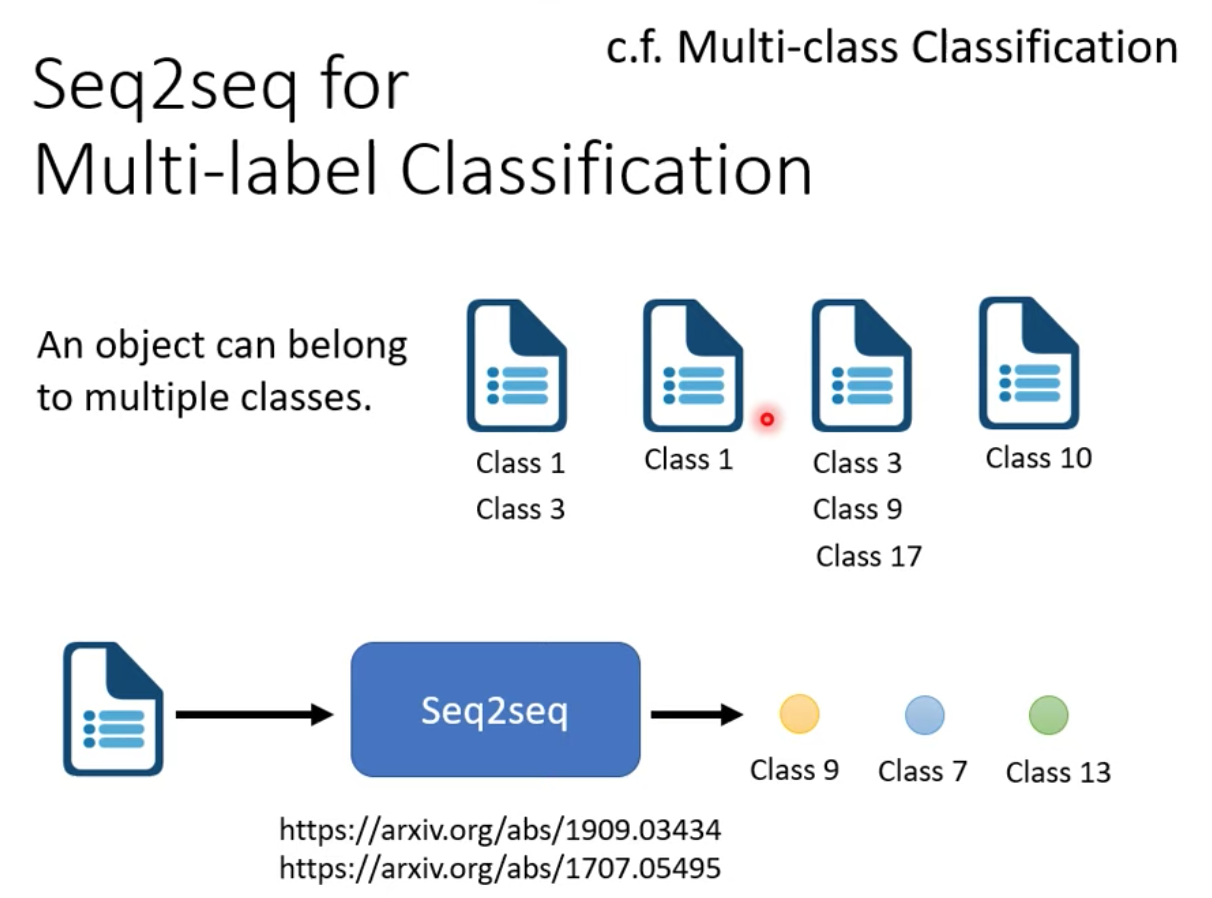
Seq2seq model 甚至可以用在 Object Detection 上!
在此就不多討論,一樣論文附上連結 https://arxiv.org/abs/2005.12872
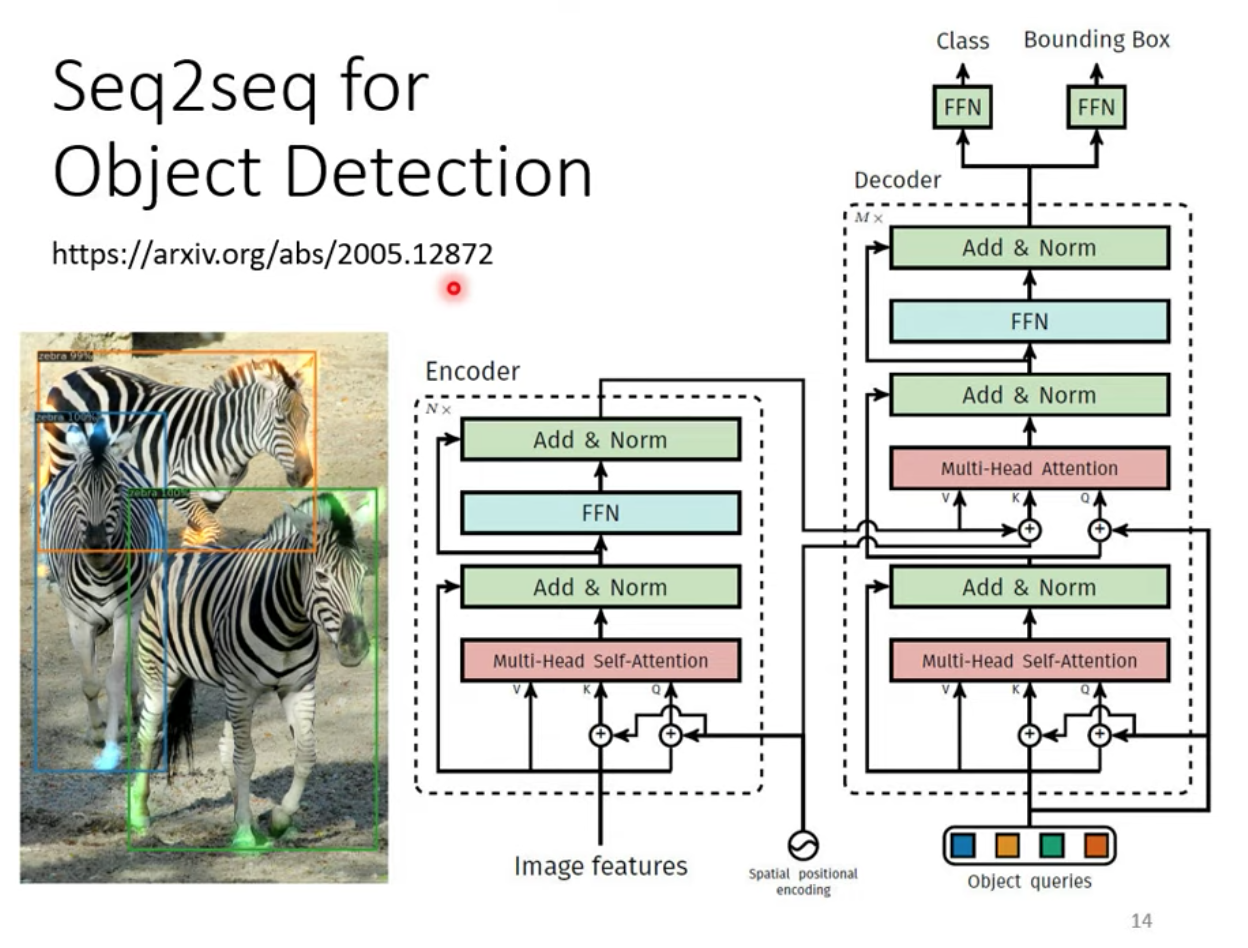
認識了 Seq2seq model 可以做到這麼多事情後,
現在來深入探討 Seq2seq model 的架構
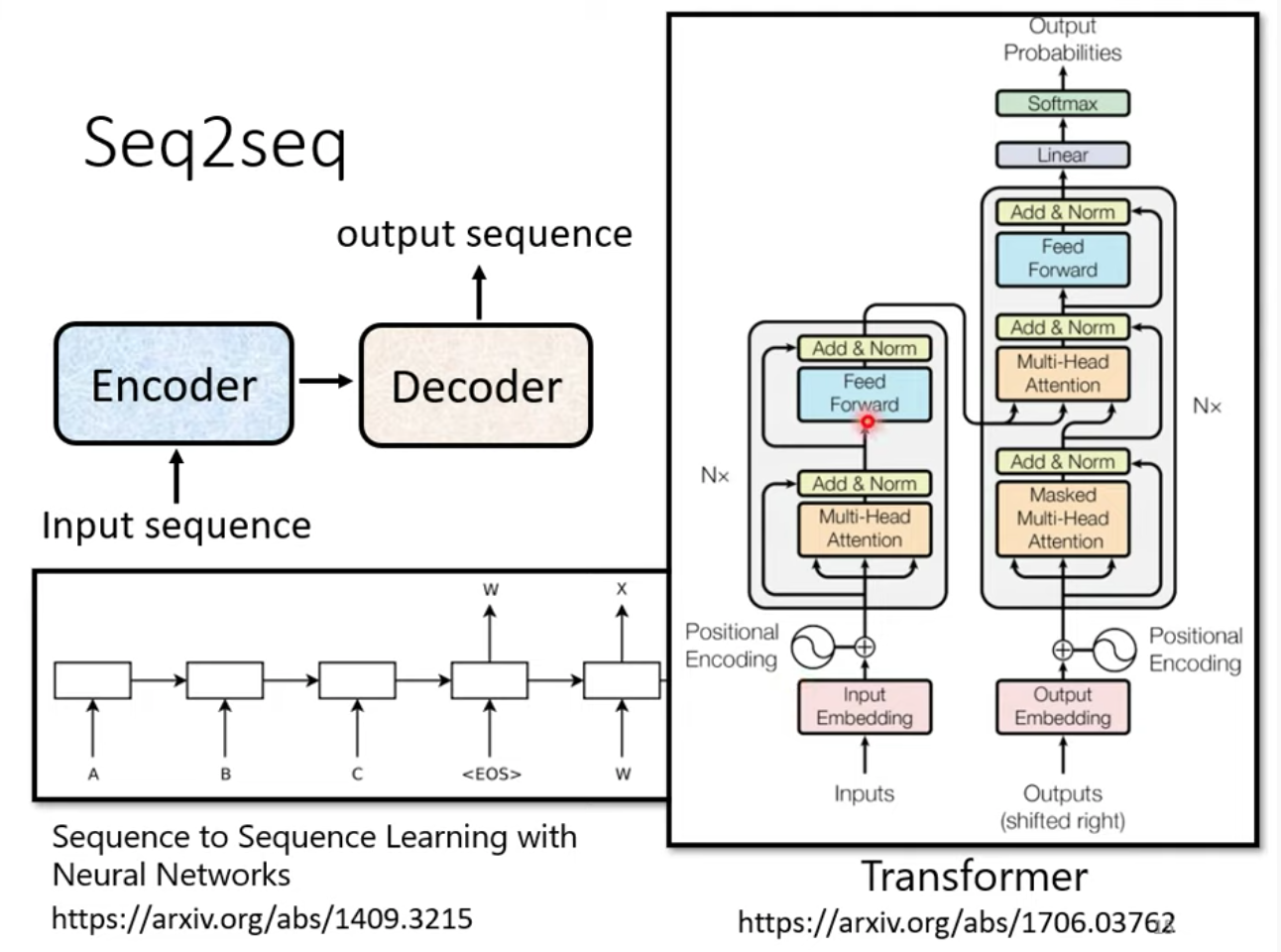
一般的 Seq2seq model 會分成兩塊:Encoder 跟 Decoder
input 丟給 encoder 輸出後丟給 Decoder 讓 Decoder 決定要輸出怎麼樣的向量
Encoder
Encoder 要做的事情就是
給一排向量,output 另一排向量
CNN, RNN 以及 self-attention 都可以做到這樣的事情

在 Transformer 裡面使用的是 Self-attention

Transformer Encoder 裡面每一個 Block 做了一連串事情:先過一層 self-attention後再過 FC 後得到輸出的 vector
此外,transformer encoder 裡還採用了 residual connection 的設計

residual: 把 input 跟 output 的結果加起來
做完 residual 後還做了 Normalization
這裡的 Normalization 不是 batch normalization 而是 layer normalization
Layer Normalization 做的事情比 batch normalization 更簡單一點
輸入一個向量後,計算該向量的 mean 跟 standard deviation (std.) 要注意一下
Batch Normaliztion v.s. Layer Normalization
Batch Normaliztion:
對同一個 dimension,不同的 feature 去計算 mean 跟 std.
Layer Normalization
對同一個 feature vector,不同的 dimention 去計算 mean 跟 std.
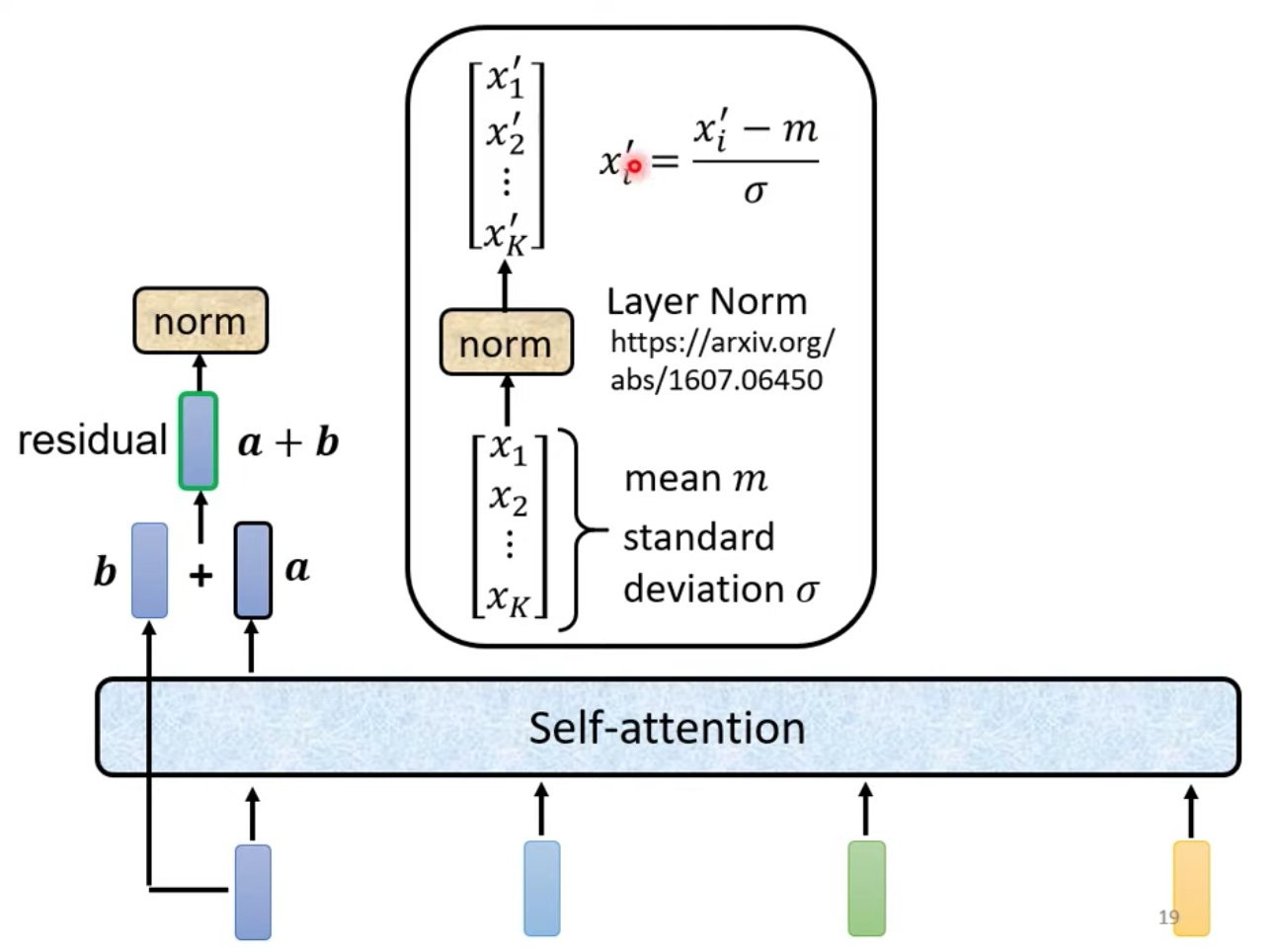
(p.s. 上圖當中紅色點指到的 x’i 更正為沒有 ’ 的 xi )

input vector 過了 self-attention 後得到 vector a
將 vector a 與 input vector b 加起來得到新的 output (綠色框)這個動作稱為 residual connection
將 output(綠色框) 過完 norm 之後,得到一組輸出 vector (深藍色)
再將目前這個深藍色的 vector ,過了 Fully Connected layer (FC) 後得到新的 vector (黑色框)
再做一次 residual connection 後的輸出,最後再做一次 (layer) normalization 得到的輸出才是這個 Block 最終的輸出!
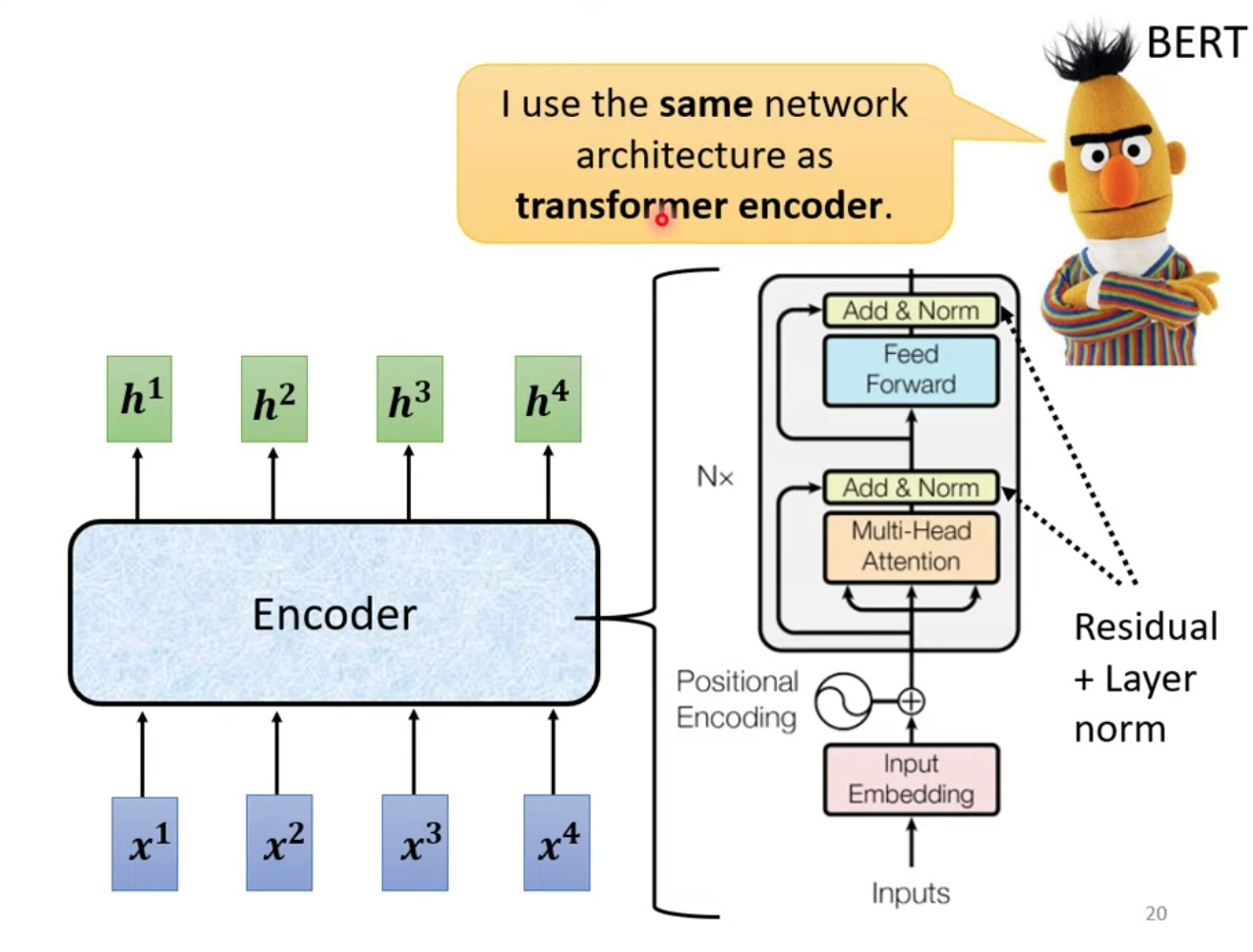
我們用別個圖再複習一次:
input 的地方 還有加上 positional encoding 擷取 positional 的資訊
圖中的 Multi-Head Attention 區塊就是我們剛剛的 self-attention 的架構
圖中的 Add & Norm 區塊就是剛剛講的 residual connect + layer normalization 的動作
圖中的 Fead Forward 區塊就是剛剛說的 FC 連接
這個複雜的 Block 之後會用在 BERT 的 Encoder 部分
到這裡可能會有疑問,為什麼 Encoder 要這樣設計呢?有沒有其他的設計方法

當然有!Encoder 的設計可以有很多不同的變化
有一篇文章叫做 On Layer Normalization in the Transformer Architecture 裡面有討論到
為什麼我們先做 residucal 在做 layer norm 呢?
例如
圖中的 (a) 原始的論文設計架構,Encoder 端先做 residual 後在做 layer norm 再加進去
圖中的 (b) 則是先做完 layer norm 才過 attention,FC 之前先過 layer norm
PowerNorm 這篇論文會討論,為什麼在這個應用中做 Batch Normalization 會不如使用 Layer Normaliztion 效果更好
(下集待續)
相關文章整理






留言
張貼留言