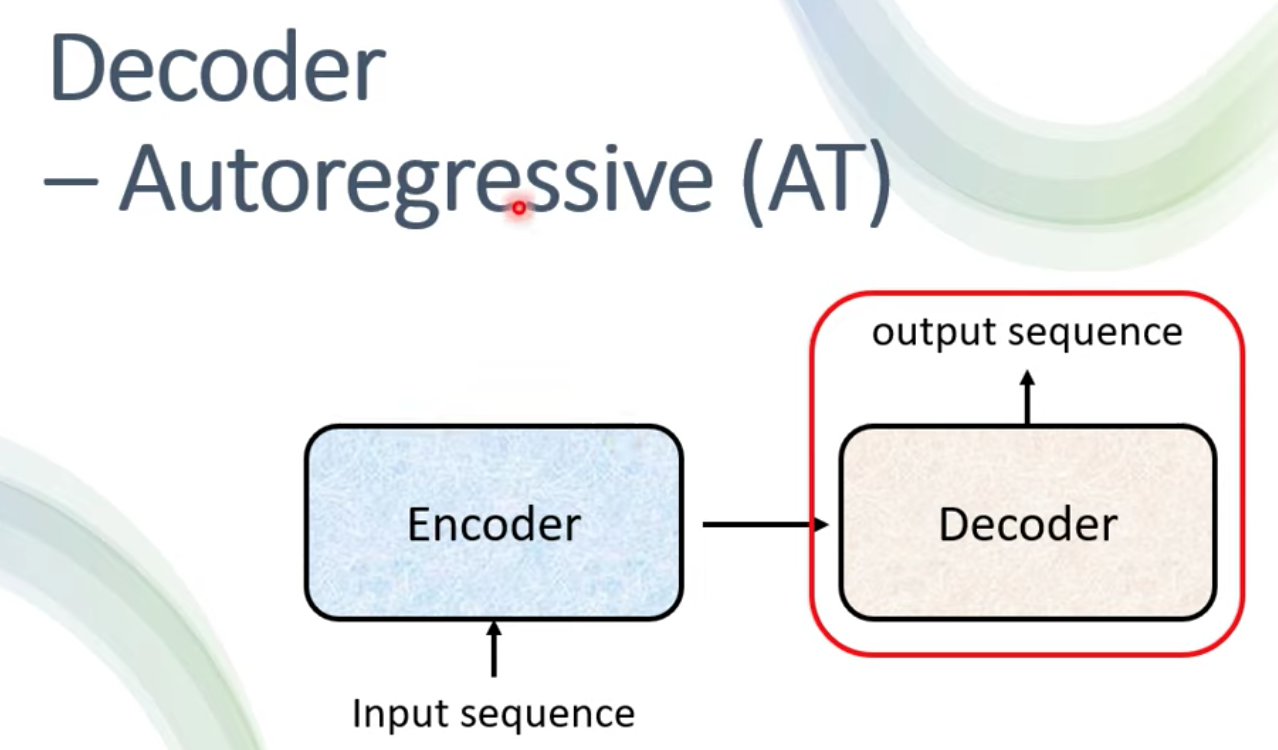
[ML 筆記] Transformer(下) 取得連結 Facebook X Pinterest 以電子郵件傳送 其他應用程式 12月 13, 2021 Transformer 筆記(下) 本篇為台大電機系李宏毅老師 Machine Learning (2021) 課程筆記 上課影片: https://youtu.be/N6aRv06iv2g 延續上一篇: [ML 筆記] Transformer ( 上) 我們這篇來介紹 Transformer 裡面的 Decoder 部分 Read more »
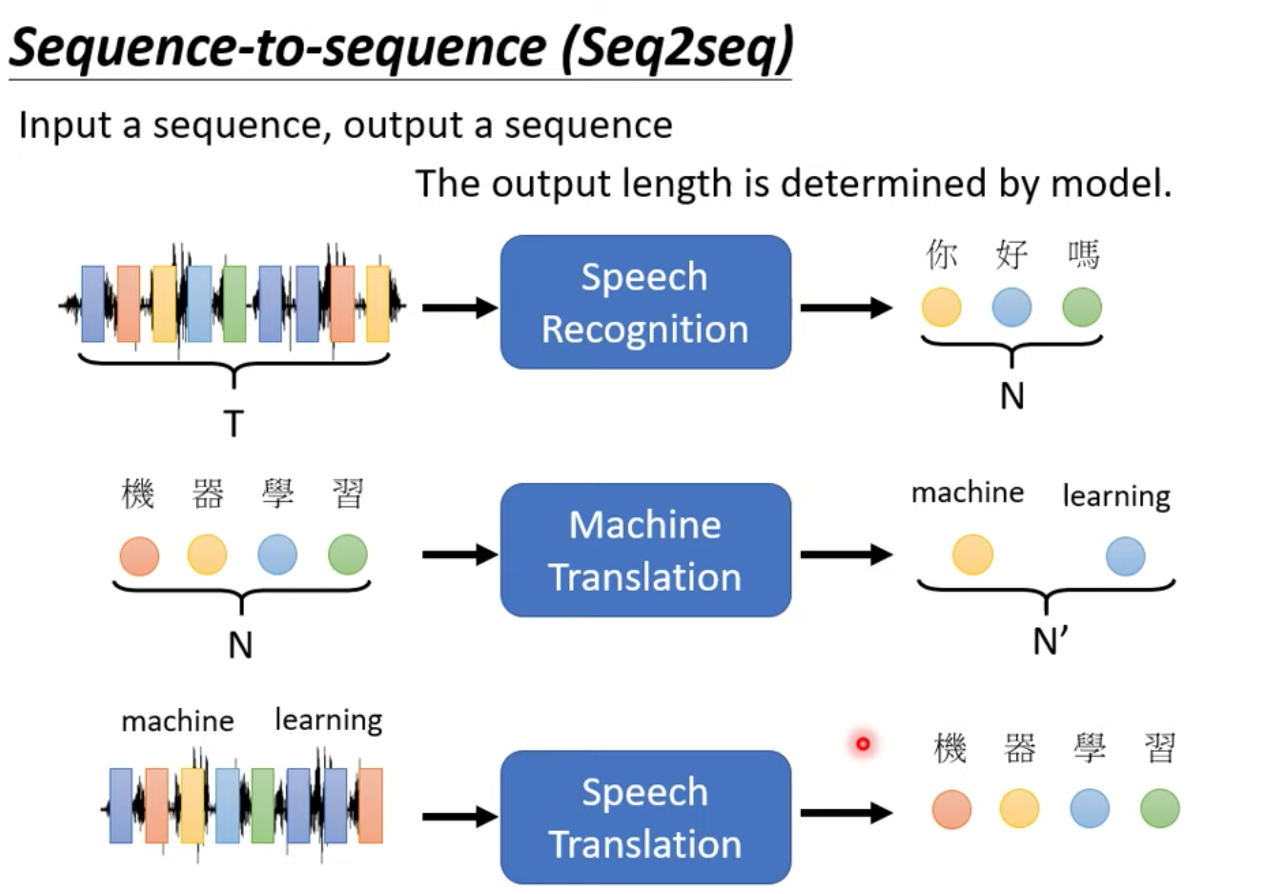
[ML 筆記] Transformer(上) 取得連結 Facebook X Pinterest 以電子郵件傳送 其他應用程式 12月 13, 2021 Transformer 筆記(上) 本篇為台大電機系李宏毅老師 Machine Learning (2021) 課程筆記 上課影片: https://youtu.be/n9TlOhRjYoc 首先複習一下所謂的 Sequence-to-sequence (Seq2seq) Model 要解決的問題 想想有哪些任務的 input 是一個 sequence, output 是由機器自己決定應該要輸出的長度呢? Read more »
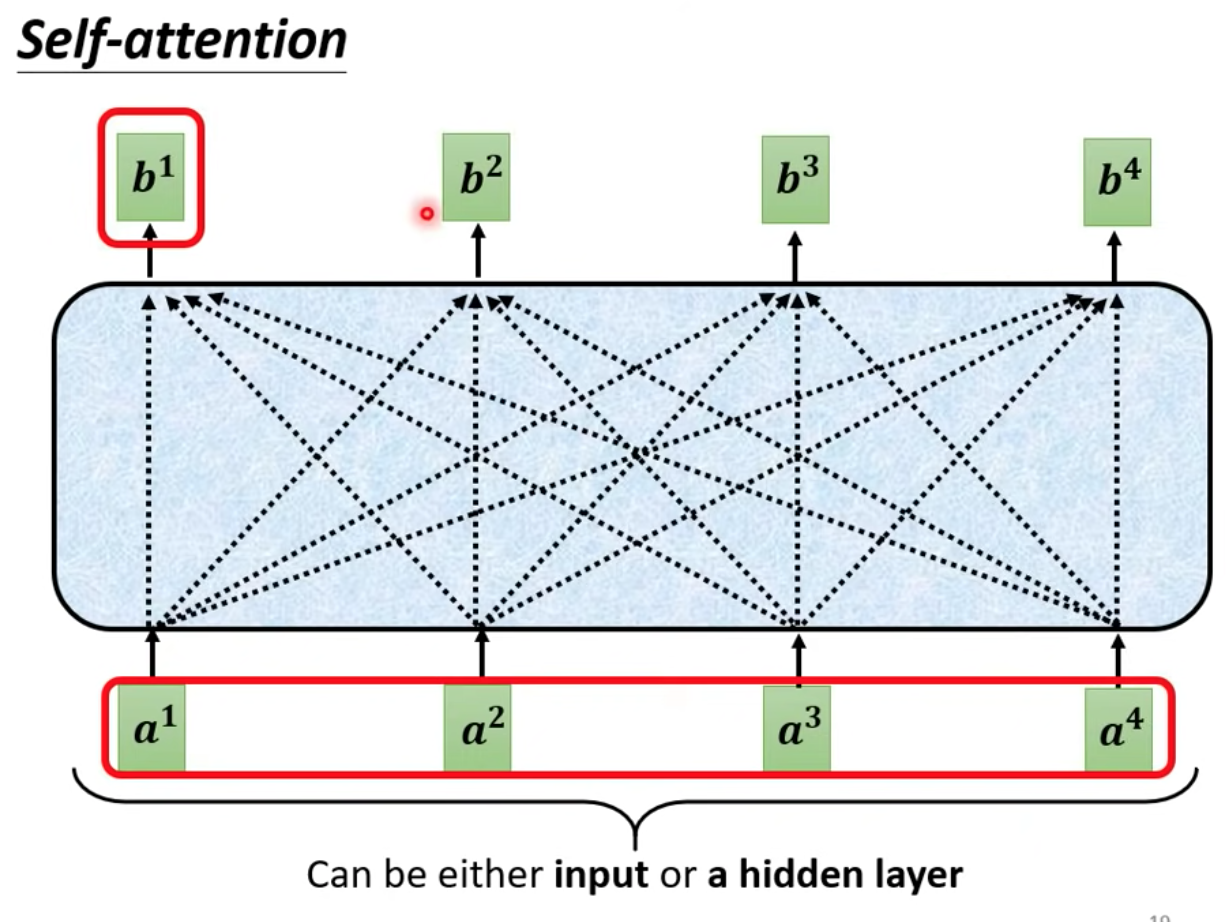
[ML 筆記] 自注意機制 Self-attention (下) 取得連結 Facebook X Pinterest 以電子郵件傳送 其他應用程式 12月 02, 2021 Self-attention 筆記(下) 本篇為台大電機系李宏毅老師 Machine Learning (2021) 課程筆記 上課影片: https://youtu.be/gmsMY5kc-zw 延續上一篇 [ML 筆記] 自注意機制 Self-attention (上) Self-attention 的詳細架構介紹,先複習一下 我們的 Self-attention 的 input 是個 sequence (a1 ~ a4) output 端是另一個 vector (b1 ~ b4) Read more »
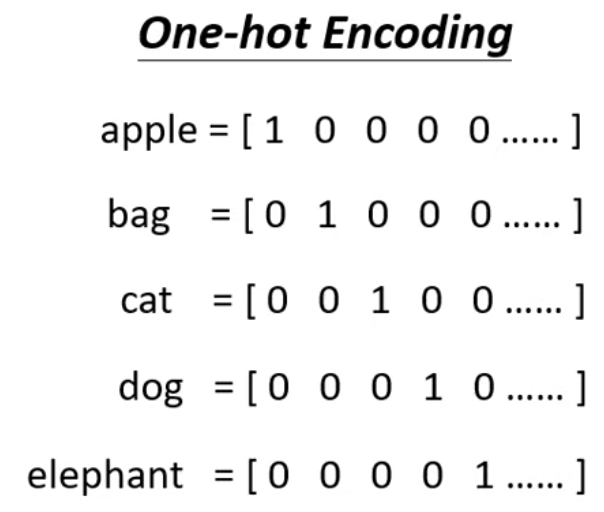
[ML 筆記] 自注意機制 Self-attention (上) 取得連結 Facebook X Pinterest 以電子郵件傳送 其他應用程式 12月 02, 2021 Self-attention 筆記(上) 本篇為台大電機系李宏毅老師 Machine Learning (2021) 課程筆記 上課影片: https://youtu.be/hYdO9CscNes 定義 Sequence-to-Sequence (Seq2seq) 的問題 將 Input 視為一個 Sequence: 例如文字資料處理,我們可以把句子中每個詞彙都描述成向量集 Vector set 而把文字表示成向量的方法很多,其中一種做法是 One-hot Encoding 這個 encoding 有個很明顯的缺點,就是它假設所有詞彙都是沒有關係的 例如下圖當中,我們無法從 encode 後的 vector 看出這五個單字哪些比較相近 Read more »