[ML筆記] Regression part 3 - Gradient Descent
ML Lecture 3: Gradient Descent
本篇為台大電機系李宏毅老師 Machine Learning (2016) 課程筆記
上課影片:
https://www.youtube.com/watch?v=yKKNr-QKz2Q
課程網 (投影片出處):
http://speech.ee.ntu.edu.tw/~tlkagk/courses_ML16.html

Loss function L 是一個 function 的 function
做法是隨機選一組 起始的值,扣掉 learning rate 乘上對 的偏微分,就可以得到下一組

Tip 1 : 要小心調整 Learning Rate
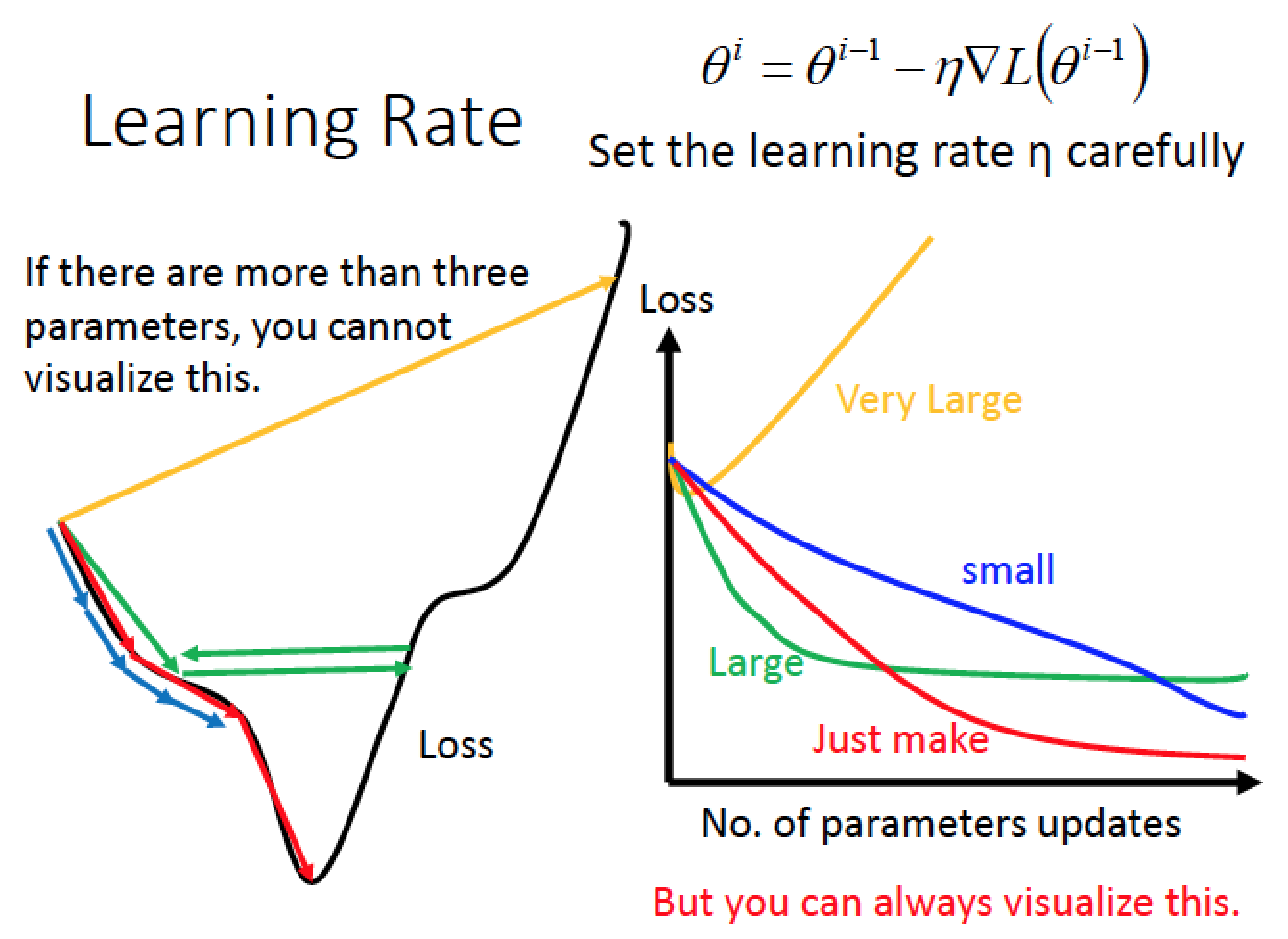
Learning Rate 剛剛好:紅色的箭頭,太大:黃色、綠色箭頭,太小:藍色箭頭
Learning Rate 設定的策略
一開始先跨大步一點,後面跨小步一點

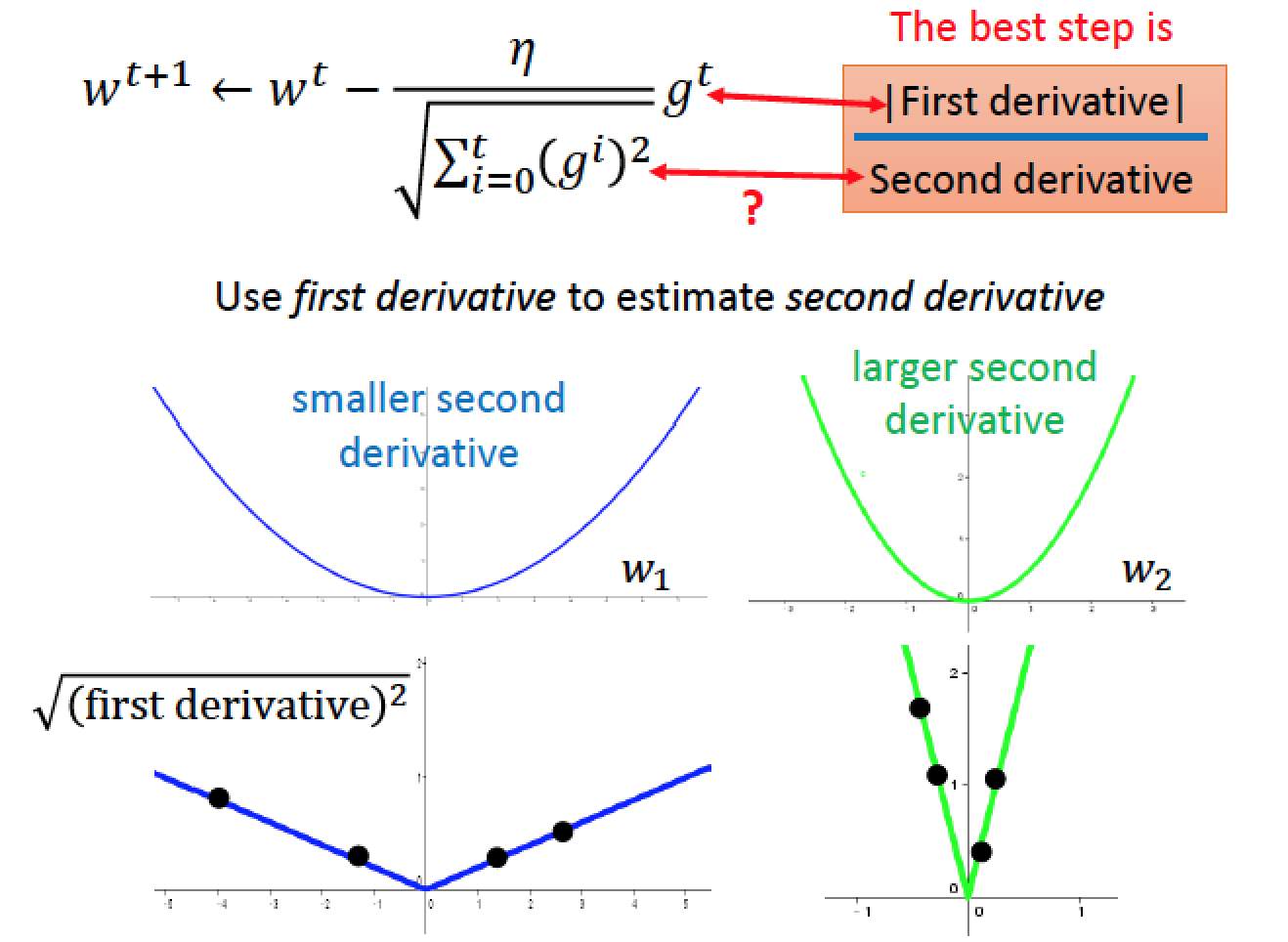
更細節的作法 “因材施教”,針對每個不同的參數,都給他不同的 Learning Rate
Adagrad (更新 learning rate 的策略)
每一個參數的 Learning Rate 都分開來考慮
 |  |
假設 w 是某一個參數,t 是時間
gt 是偏微分的值
t: Time Dependent 的 Learning Rate
t: 是過去所有微分的值的 rms (root-mean-square)
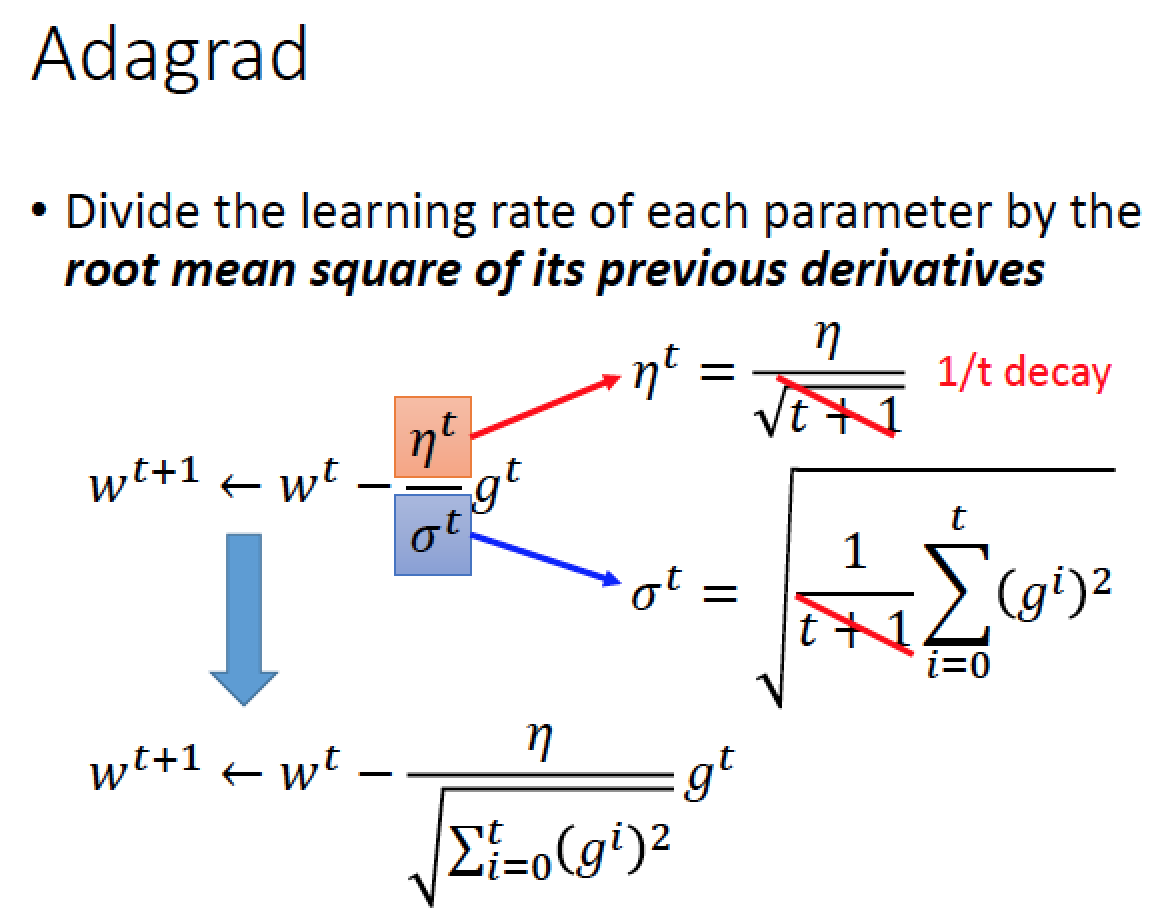
使用 Adagrad 的參數 update 的速度,整理而言是越來越慢的
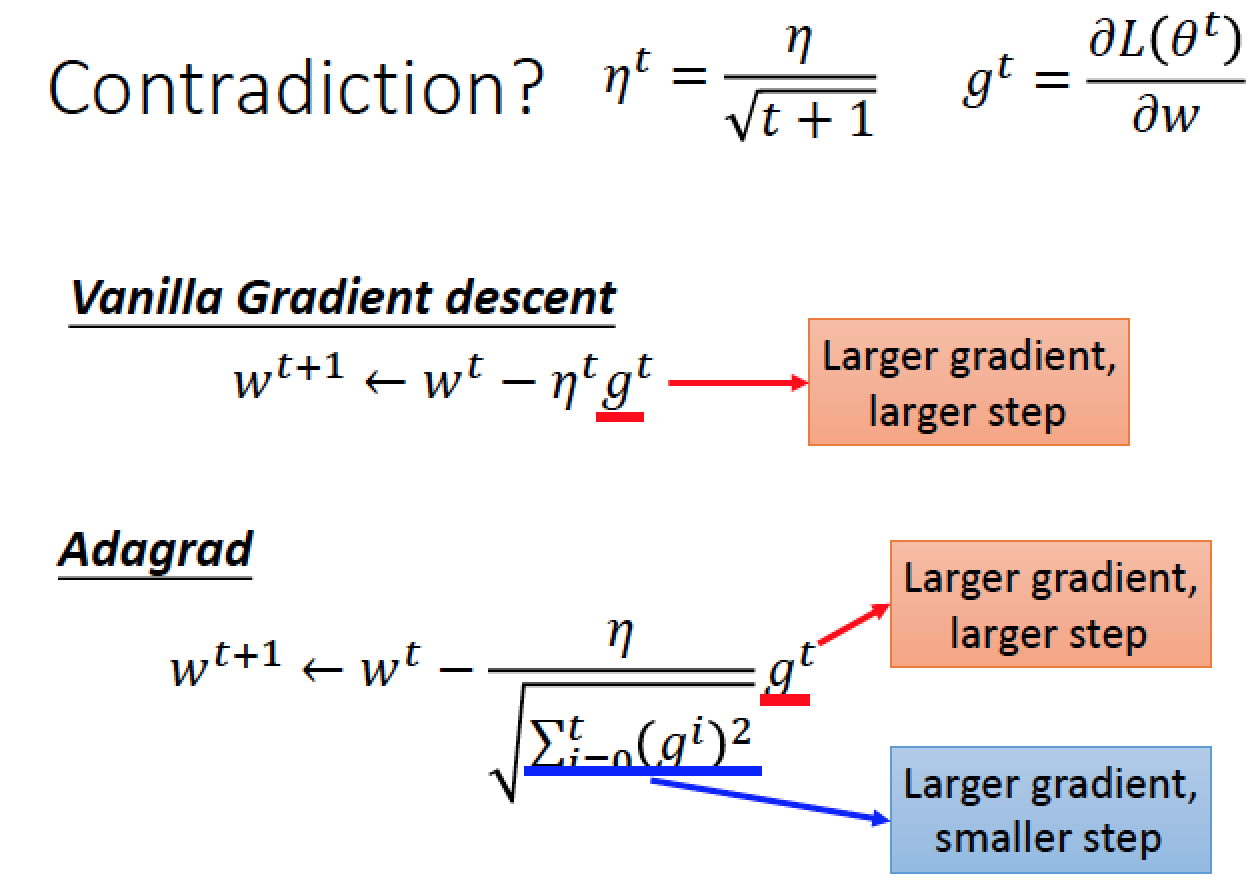
Gradiant Descent 的參數更新,要看微分的值,越大 update 越快
在 Adagrad 的公式裡面,分子紅色部分是微分越大,參數 update 的步伐越大
但是分母藍色部分的效果,影響當微分越大,參數 update 步伐越小,跟分子的影響衝突

直觀的解釋就是 Adagrad 分母這一項可以用來看單點反差的效果
假設有個參數,他算到其中一個點算出來特別大
或是算到某一次出現特別小的值
adagrad 利用過去 gradiant 的平均來看反差的效果
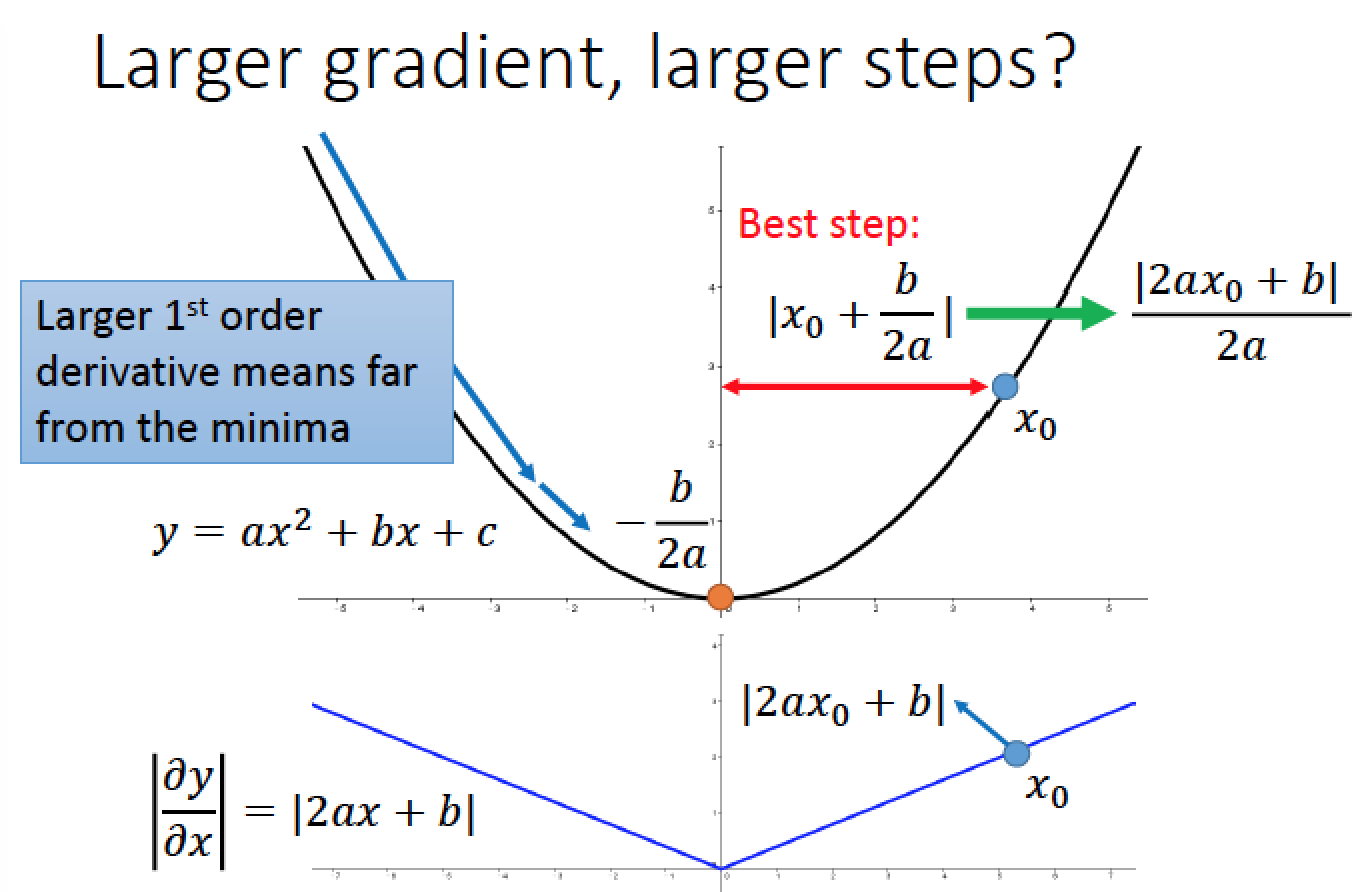
假設我們要在二次函數當中,找到最低點
那踏出去的步伐,最理想的一步到位是 (x0 + b/2a)
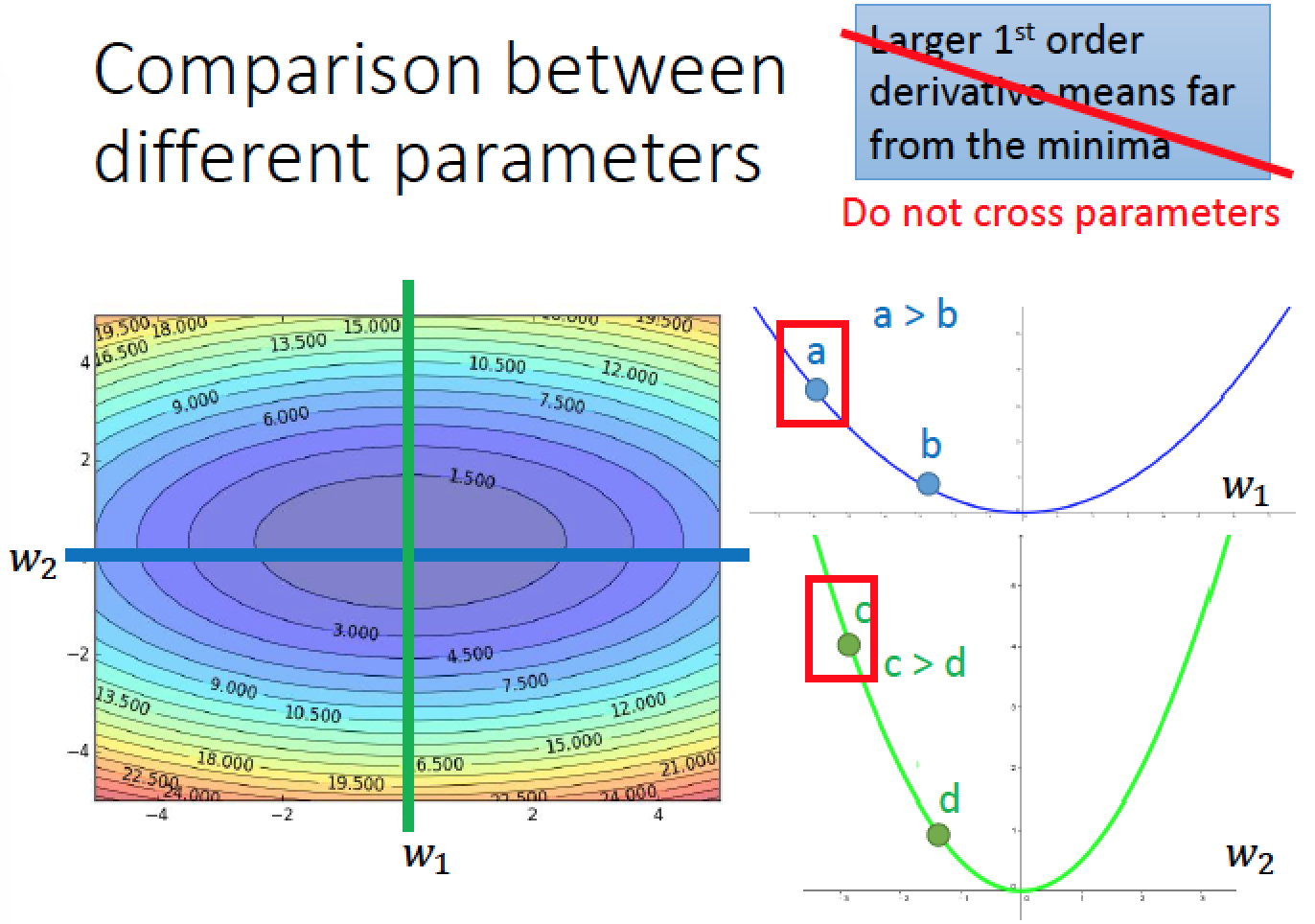
c 點離最低點比較近,微分值比較大
a 點離最低點比較遠,微分值比較小
當我們同時考慮好幾個參數時,就不能單看一次微分值的大小,還必須考慮其他的參數變化情形
所以最好的考量要把二次微分考慮進來,放在分母做平均
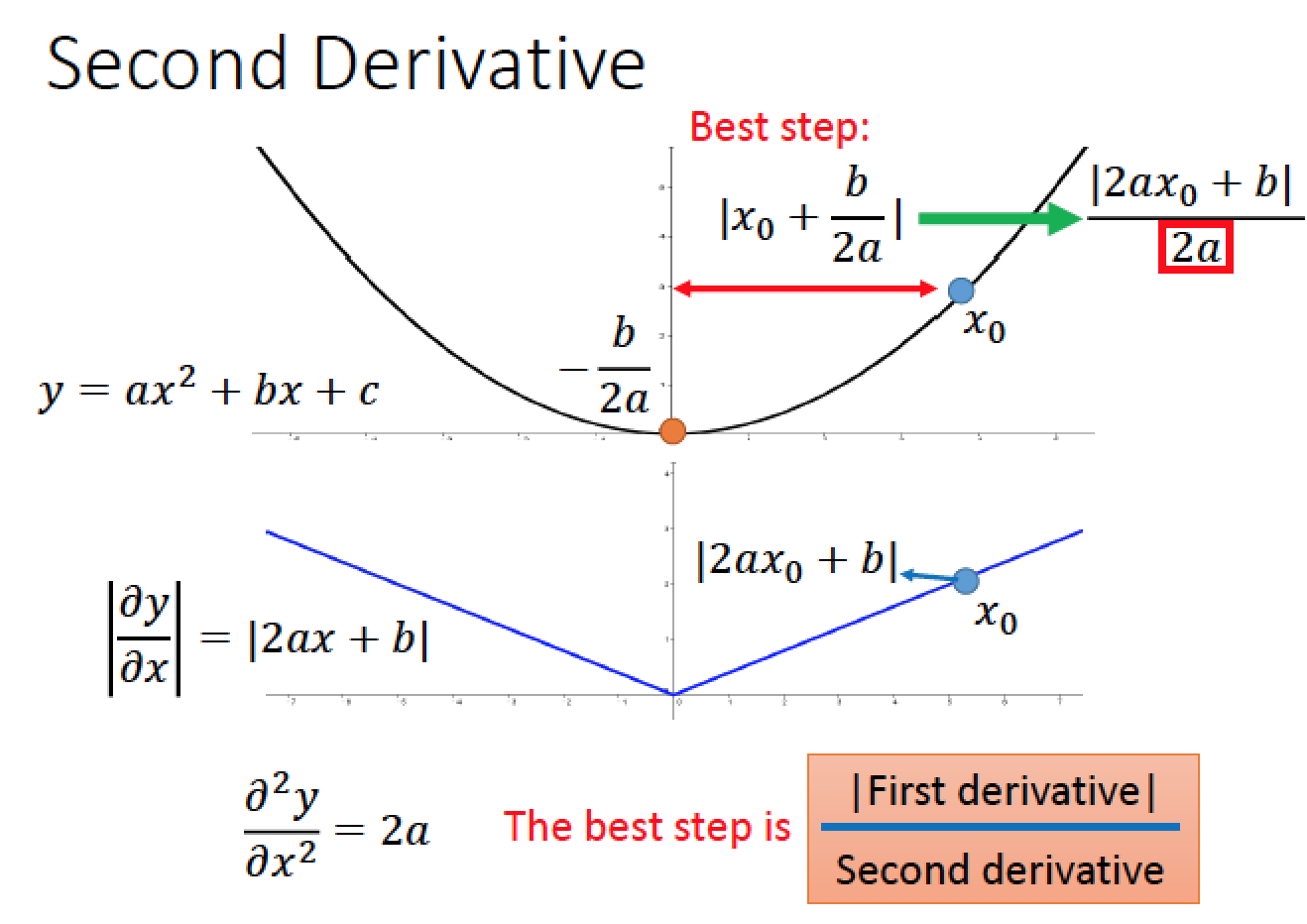 |  |
所以在 adagrad 當中,分母的那一項就是在不多做二次微分的情形下,想辦法模擬二次為分結果的情形
Tip 2 : Stochastic Gradient Descent
讓 training 加快

一般的 Gradient Descent : 看到目前為止的 sample 做 Loss 加總與平均,計算 update 參數的方向結果
Stochastic 的想法:隨機取一個 sample 出來算 Loss
update 參數的時候,只考慮那一個 sample 的情形,就直接 update 一次參數!
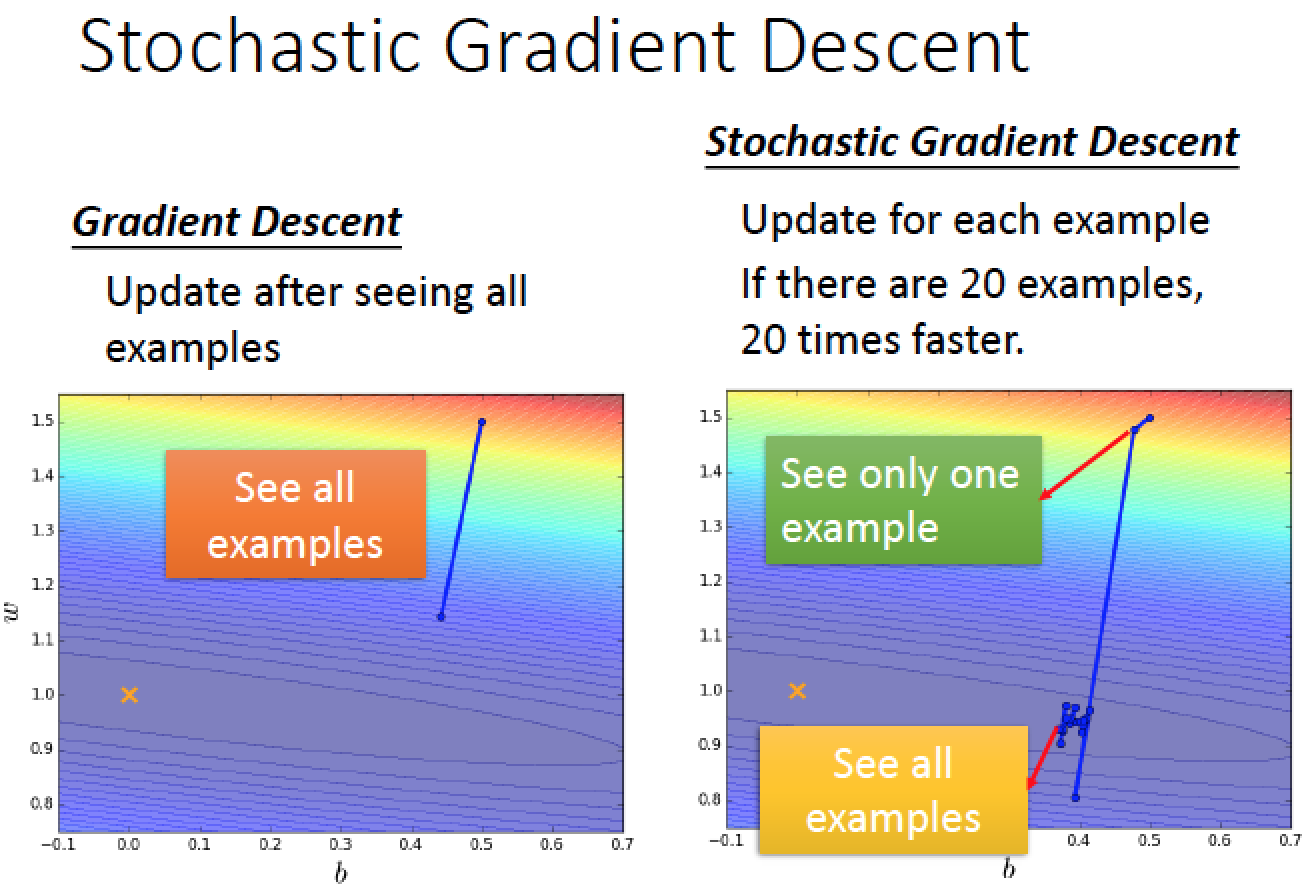
這樣做法可以很快速的更新參數,快速地找到更新參數的方向
Tip 3 : Feature Scaling
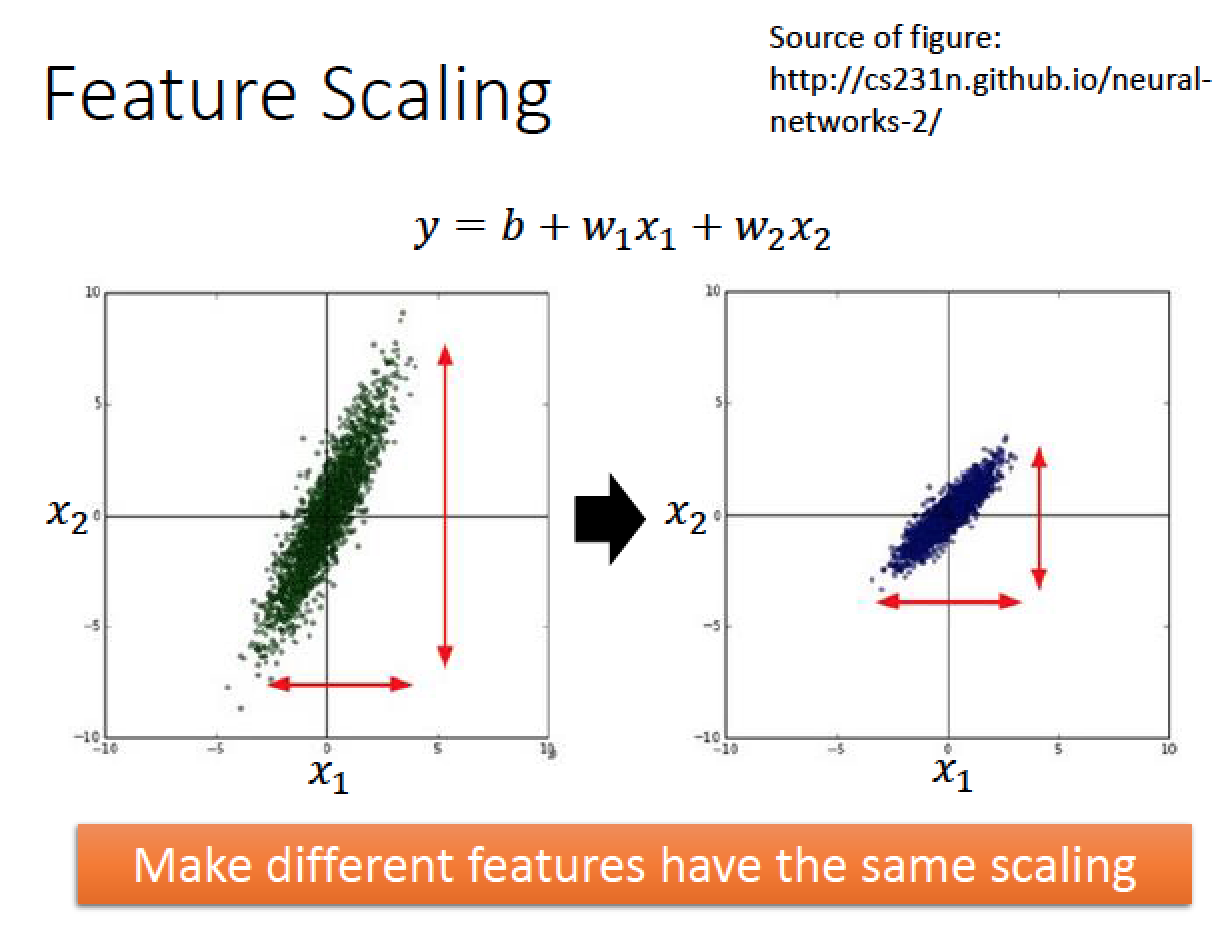
使用情境:假設我們的 model 有兩個 feature: x1 , x2 若這兩個 feature 的分布很不一樣
那我們要透過 scaling 讓他們兩個分布一致

為何要做 Feature Scaling 讓參數的影響一致呢?
如上例
w1 對於 Loss 的影響比較小 input 的值只有 1,2,3, ...
w2 對於 Loss 的影響比較大 input 的值動輒 100, 200, …
所以沒有 scaling 之前,他們的關係圖是個橢圓形
但是 after scaling 後,他們的影響關係是個正圓形,這樣的話不管在區域的哪一個點,就會像圓心走,所以做完 feature scaling 後再做 gradient descent 會比較有效率!
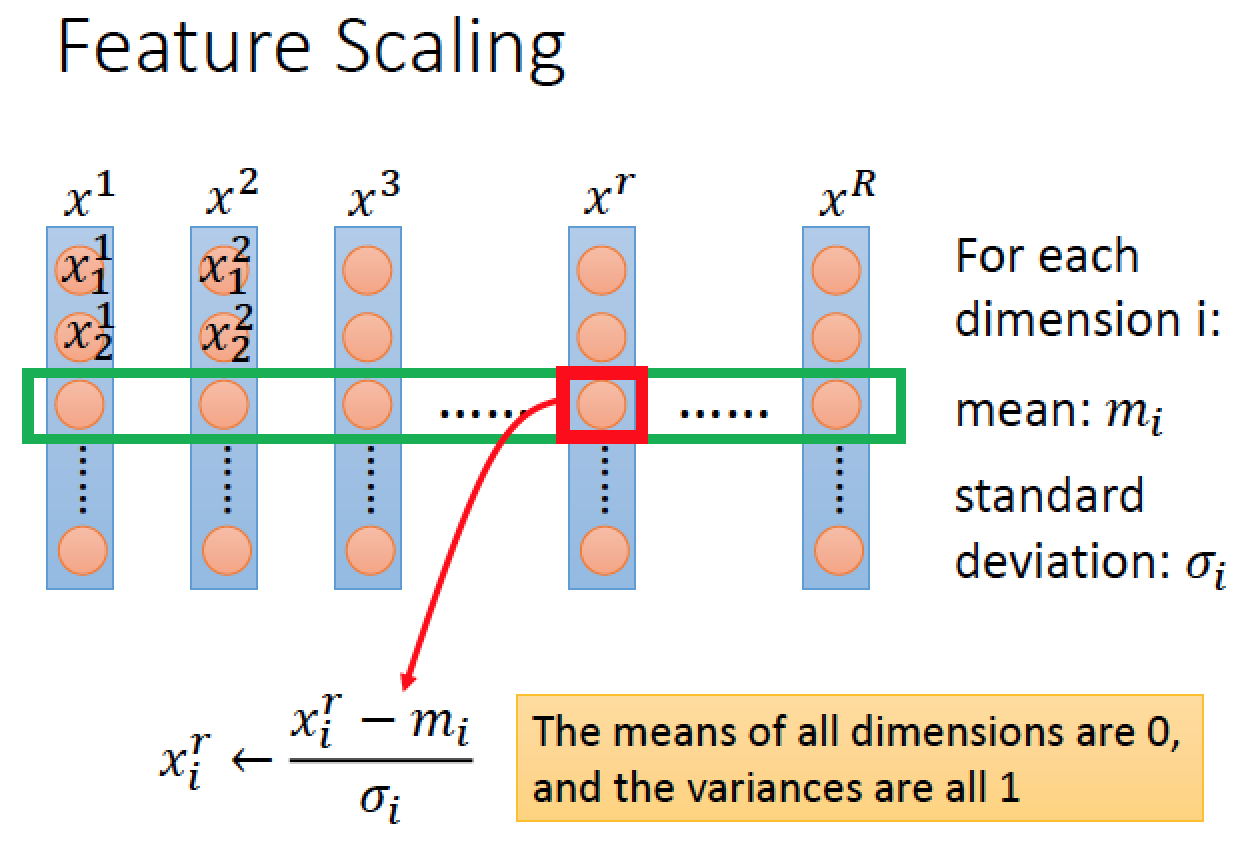 做法: 每個 data 扣掉平均 / 標準差
做法: 每個 data 扣掉平均 / 標準差
Gradient Descent Theory

問題:每次更新參數後,得到的 Loss 值也會跟著下降?
NO! 不正確,更新參數後,Loss 不見得會下降!
warning of math!
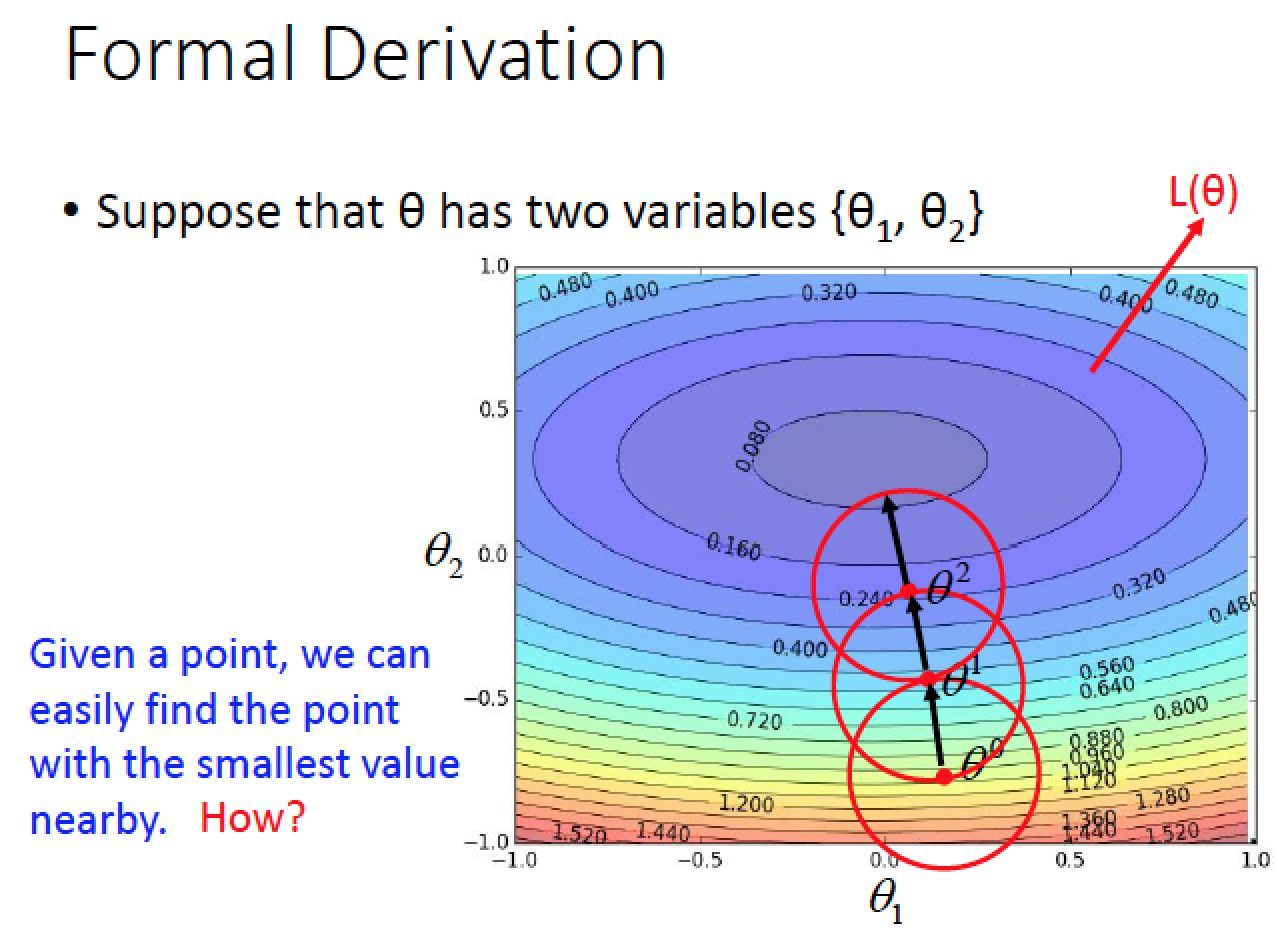
對於每一個參數 theta 畫一個範圍,找出範圍內的最小值,更新中心點參數,再畫一個區域繼續做下去,直到參數無法再更新為止
那要怎麼在紅色的圈圈區域中,找出一個可以讓 Loss 最小的參數呢?
| 
這個問題要使用泰勒展開式來看
|
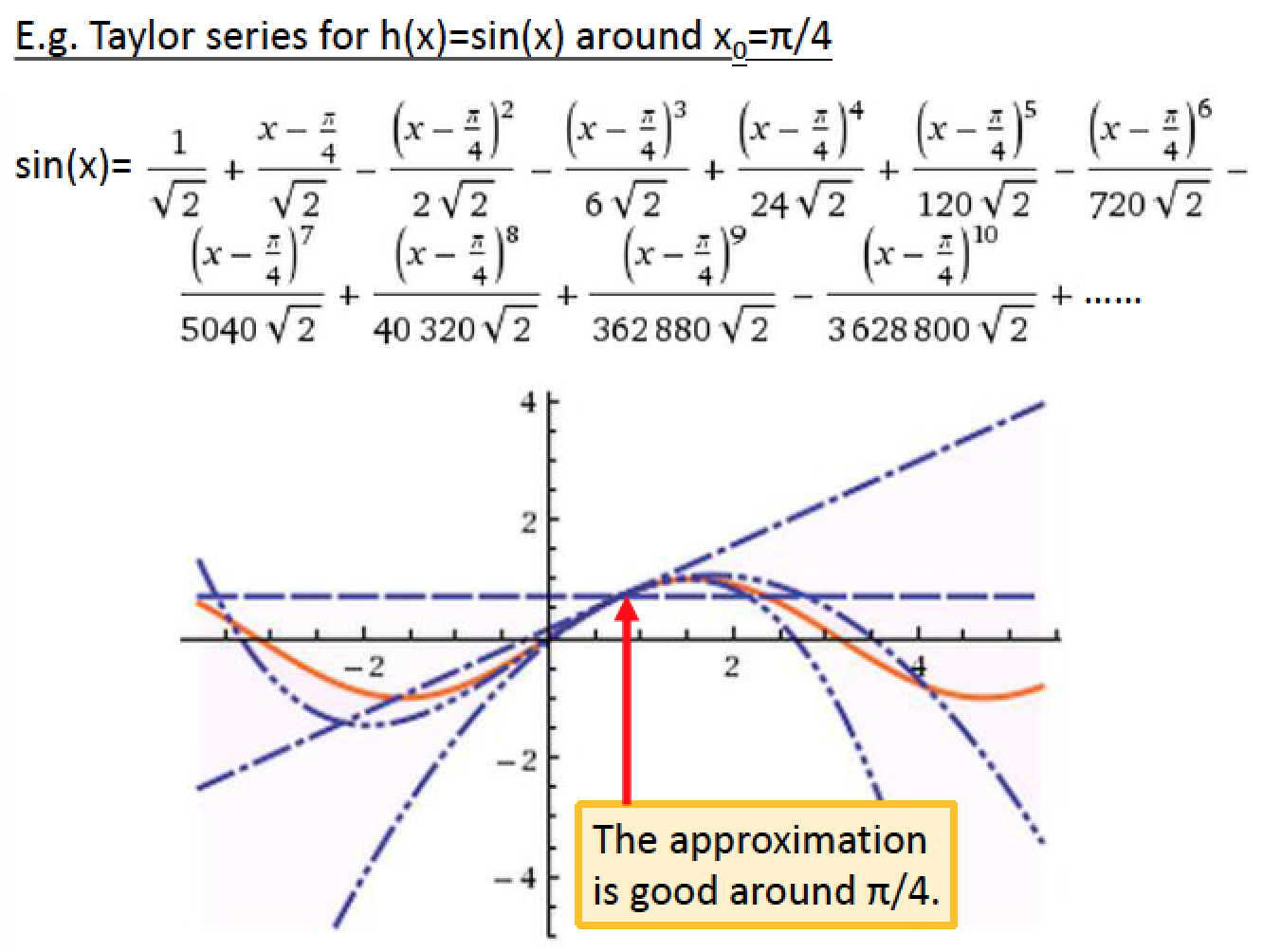
隨著考慮進來的式子越複雜,就越接近橙色這條線,本例中的 Model 考慮的次數越高越複雜,就能模擬越接近 sin function 的形狀
| 
泰勒展開式: for 多參數的情形
|
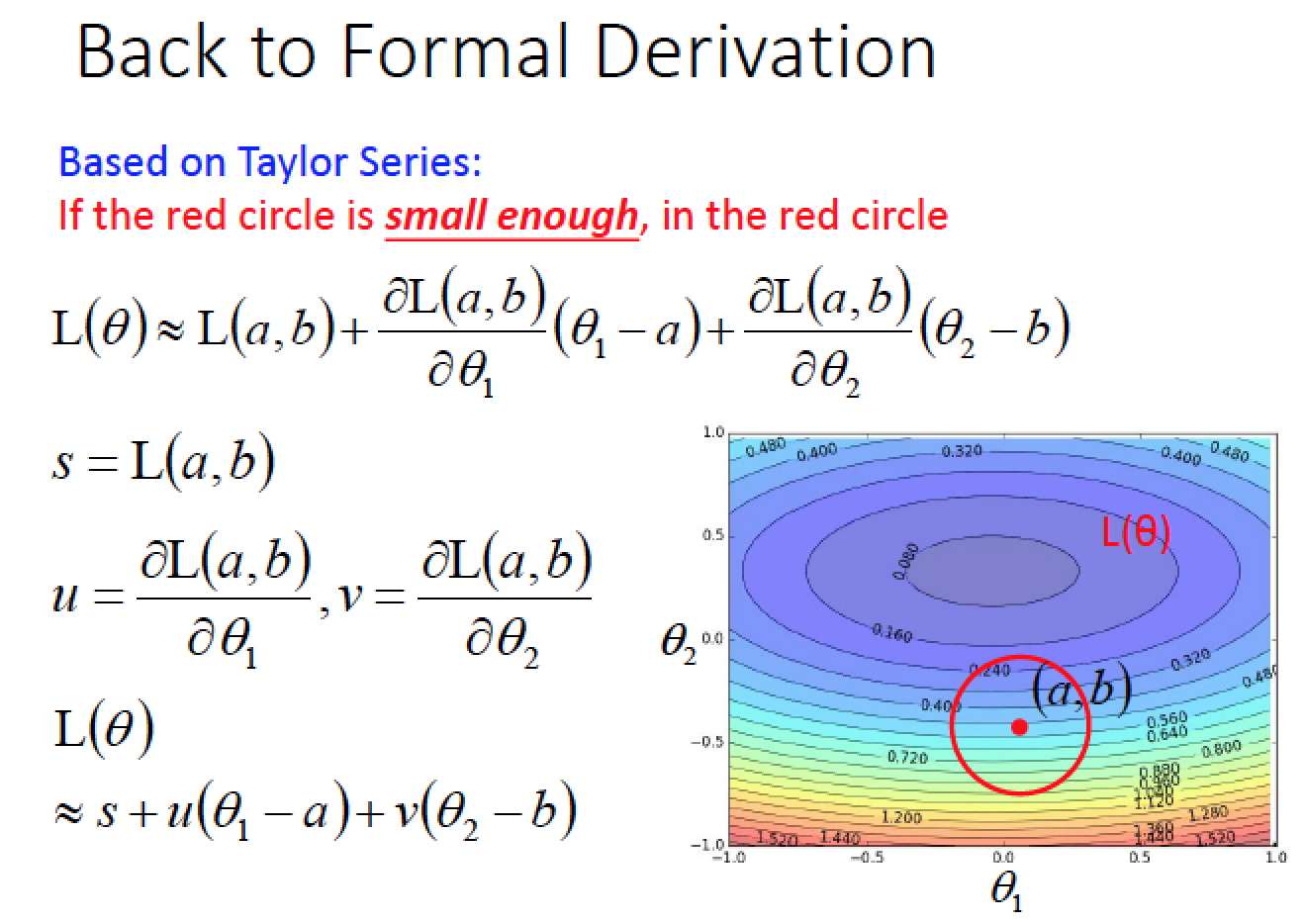
紅色圈圈內的式子,可以簡化成最下面那行
| 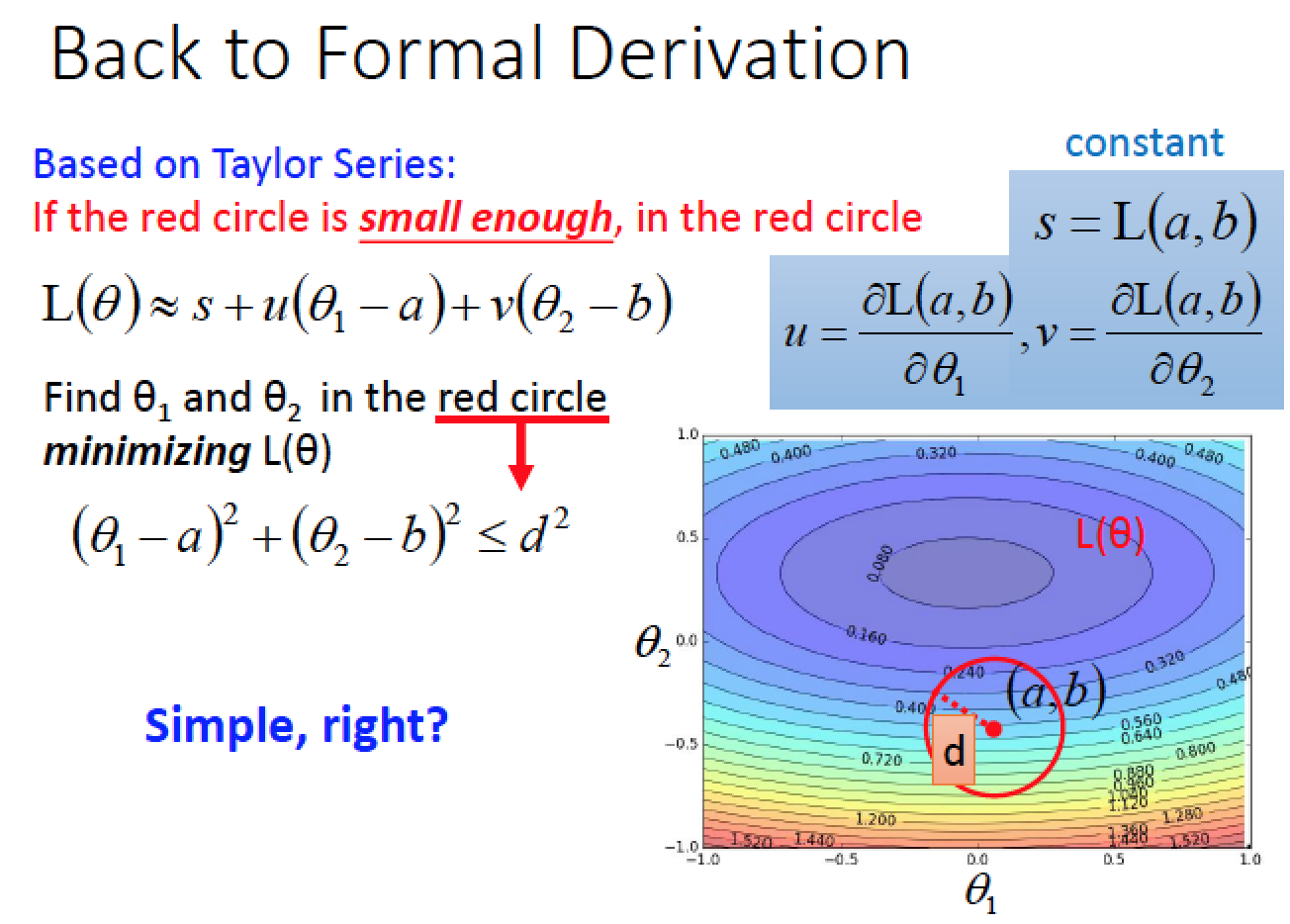
在紅色圈圈內找最小的 L
|

s 不用管
|  |
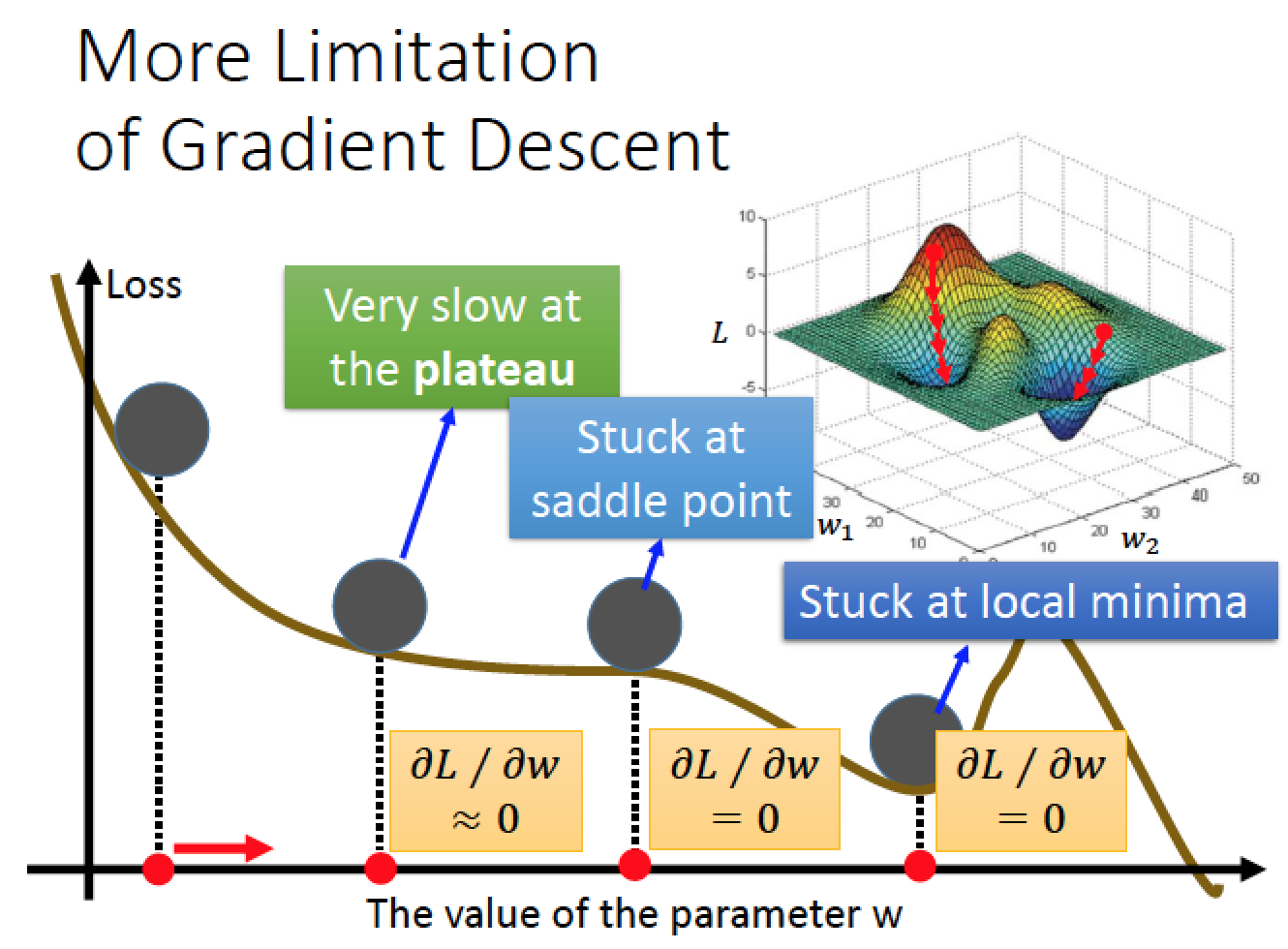
Gradient Descent 的限制
會卡在 Local Minima 或是 saddle point






留言
張貼留言