[ML筆記] Regression part 2 - Where does the error come from?
ML Lecture 2: Where does the error come from?
本篇為台大電機系李宏毅老師 Machine Learning (2016) 課程筆記上課影片:
https://www.youtube.com/watch?v=D_S6y0Jm6dQ
課程網 (投影片出處):
http://speech.ee.ntu.edu.tw/~tlkagk/courses_ML16.html
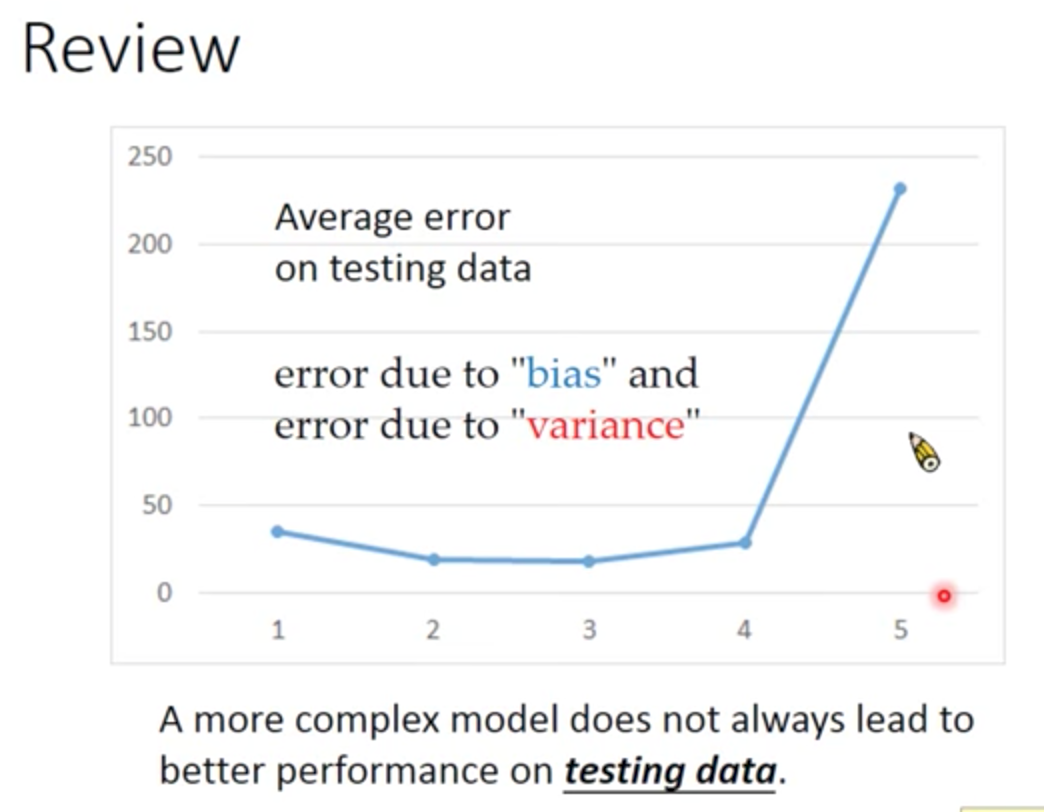
error from “variance”
如果可以診斷 error 的來源,就可以挑選出適當的方法來 improve model
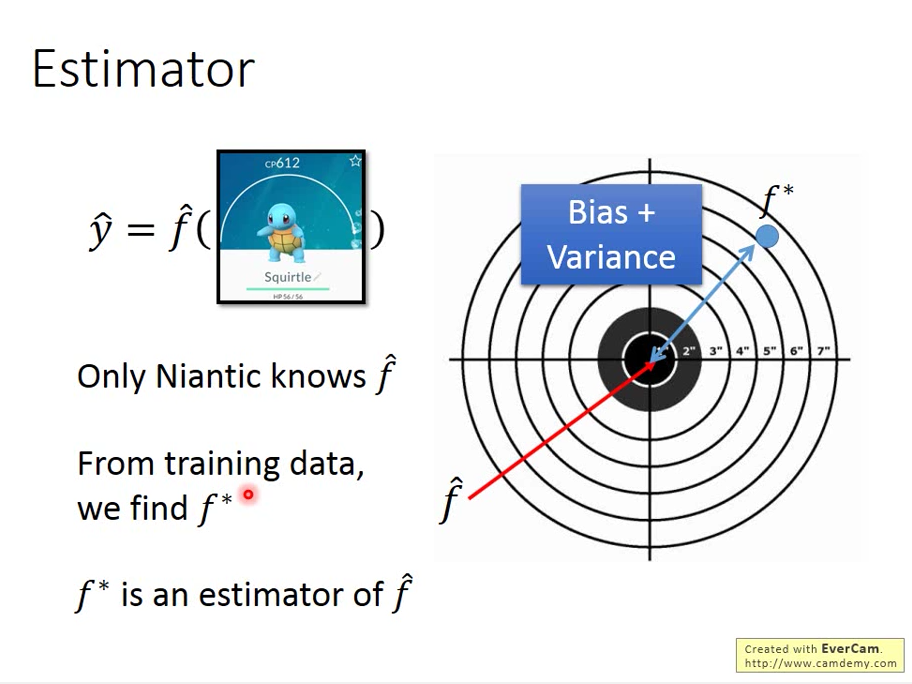
f-hat : 真正的 function
f* : 學出來後,目前最好的 funtion,他跟 f-hat 中間的一段距離(誤差)可能來自於 bias 也可能在於 variance
f* 就好比是 真正的 f-hat 的估測值
註:Niantic 是做寶可夢的那家公司

舉個機率統計的例子:隨機變數 x 平均值為 u
為了要估測值,我們從母體中抽樣 N個點來計算平均 m
由於是抽樣,所以得出來的 m 不等於 u
我的多抽樣幾次,每次抽出 N個點去計算平均值 m
則做了六次實驗分別得到平均值為 m1 m2 m3 m4 m5 m6每次跟真正的的接近程度都不一樣,則(做多次實驗可得) m 的期望值,其實就是我們母體數據的平均值
每一個 m 都不一定跟 u 一樣,但是如果取多個 m 去計算期望值,算出來會跟 u 一樣!
就好像在打靶時,打出去的子彈,散佈在準心的周圍會 "散的多開",取決於 variance
 variance = sigma 平方 除以 N 如果取比較多的 N 時,variance 小,散佈就會比較集中,取比較少的 N 時,散佈就會比較分開 |  s 平方要拿來估測 sigma 平方 如果取 s平方的期望值,算出來並非正好等於 sigma 平方, 而是還要乘以 (N-1)/N 如果 N 比較大的話,則 sigma 平方跟 s 平方的差距就會比較小 |
我們目標是要估測靶的中心
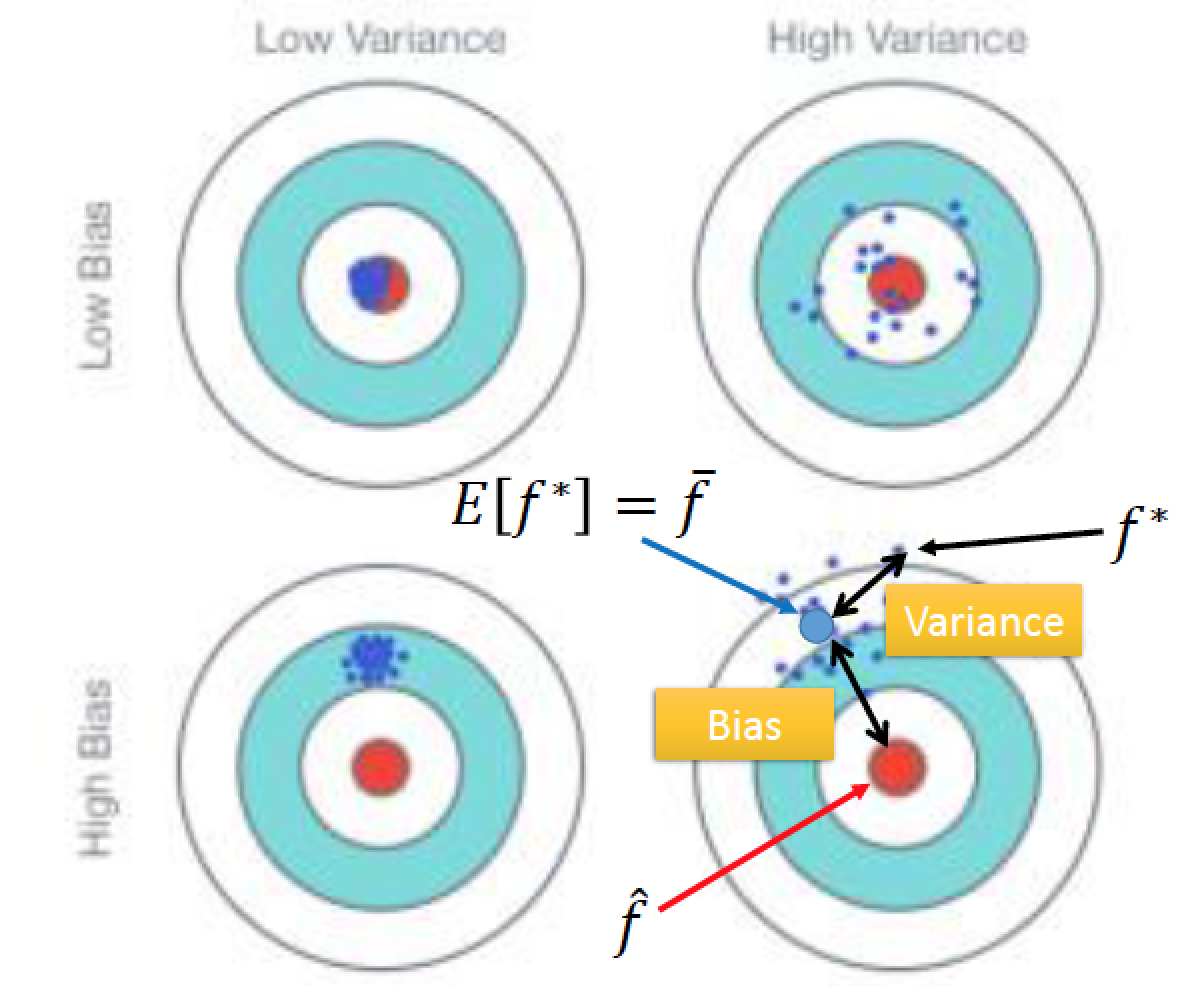
error 的位置,取決於兩件事
第一件事:瞄準的位置在哪裡 (bias) ,瞄的時候,沒有瞄準!
第二件事:雖然瞄準了一個位置,但是子彈射出去還是有偏移 (Variance)
知道了以上兩件事:
左下角:bias 很大,variance 小
右上角:bias 小,variance 大
我們想像在平行宇宙中,每個人都抓十隻寶可夢,並且都用同一種 model 去估測他的 CP 值
 | 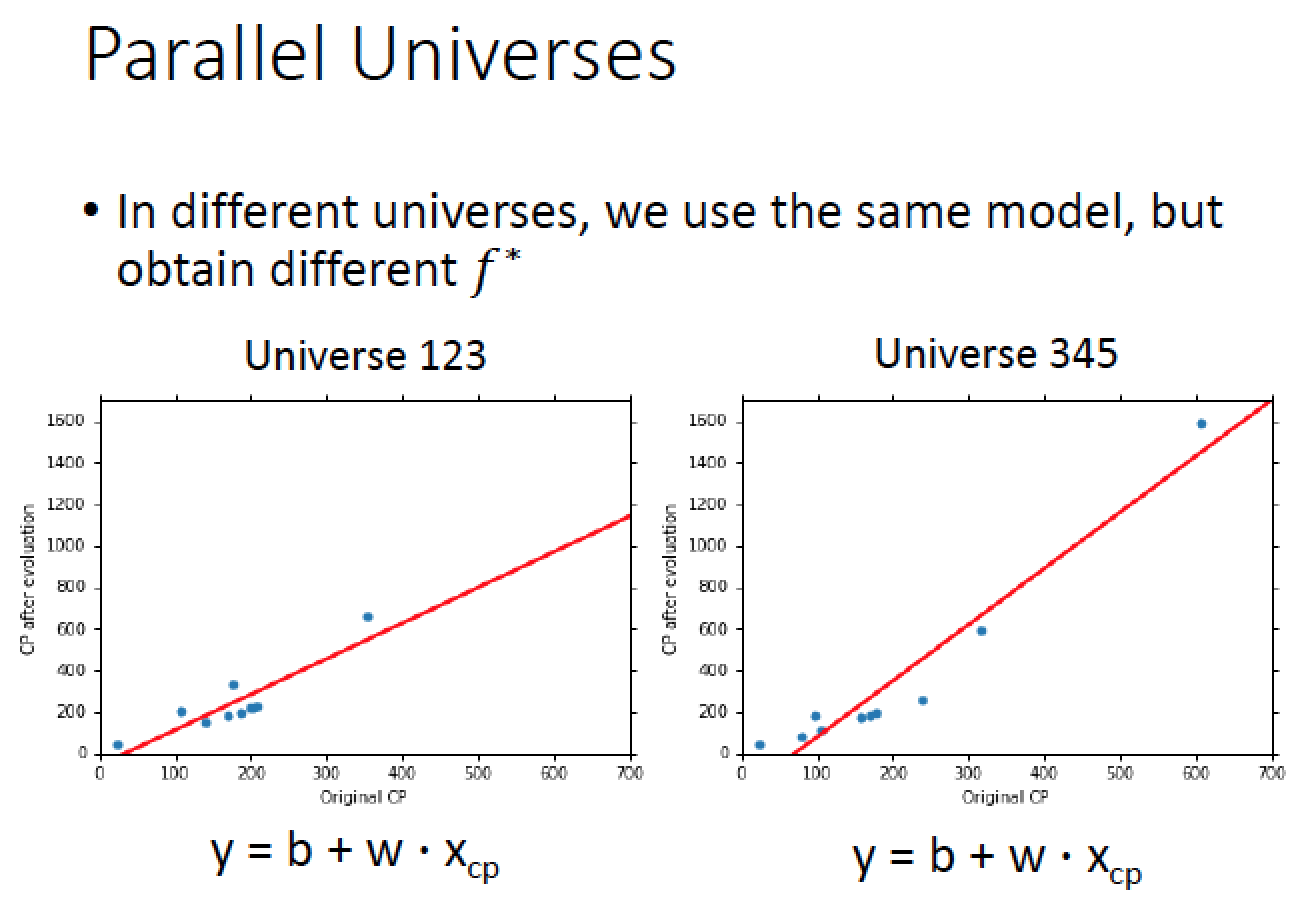 |
 做 100 次實驗,把每次的 model 畫出來
做 100 次實驗,把每次的 model 畫出來
隨著 model 複雜度更高,到五次的 model 時整個結果就崩壞了!
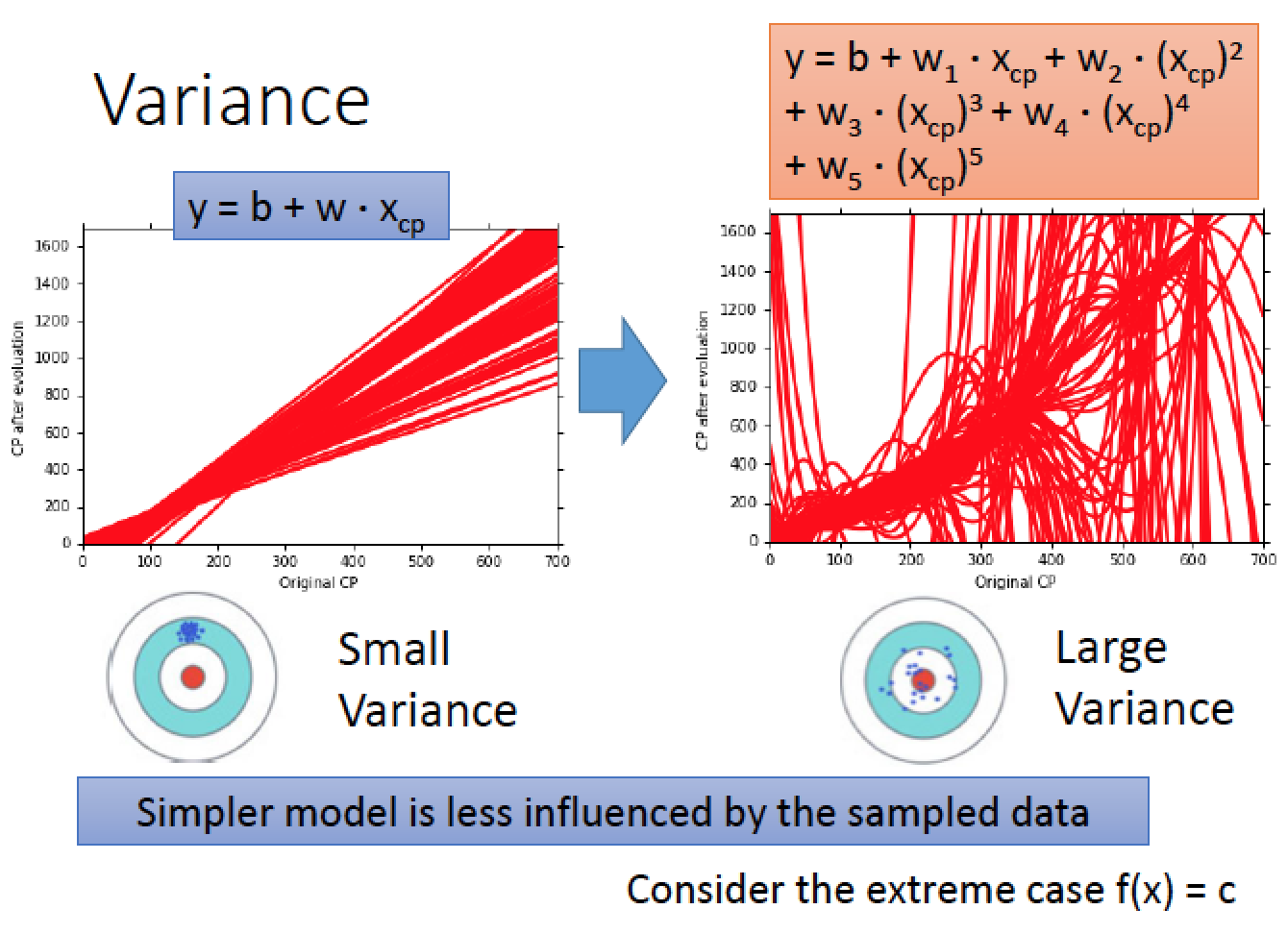
因此,得到一結論,越簡單的 model 會比較集中
比較複雜的 model 他的散佈就會比較開!
比較簡單的 model 受到不同 data 的影響比較小
比較複雜的 model 受到不同 data 的影響就會比較大
接下來來看 Bias
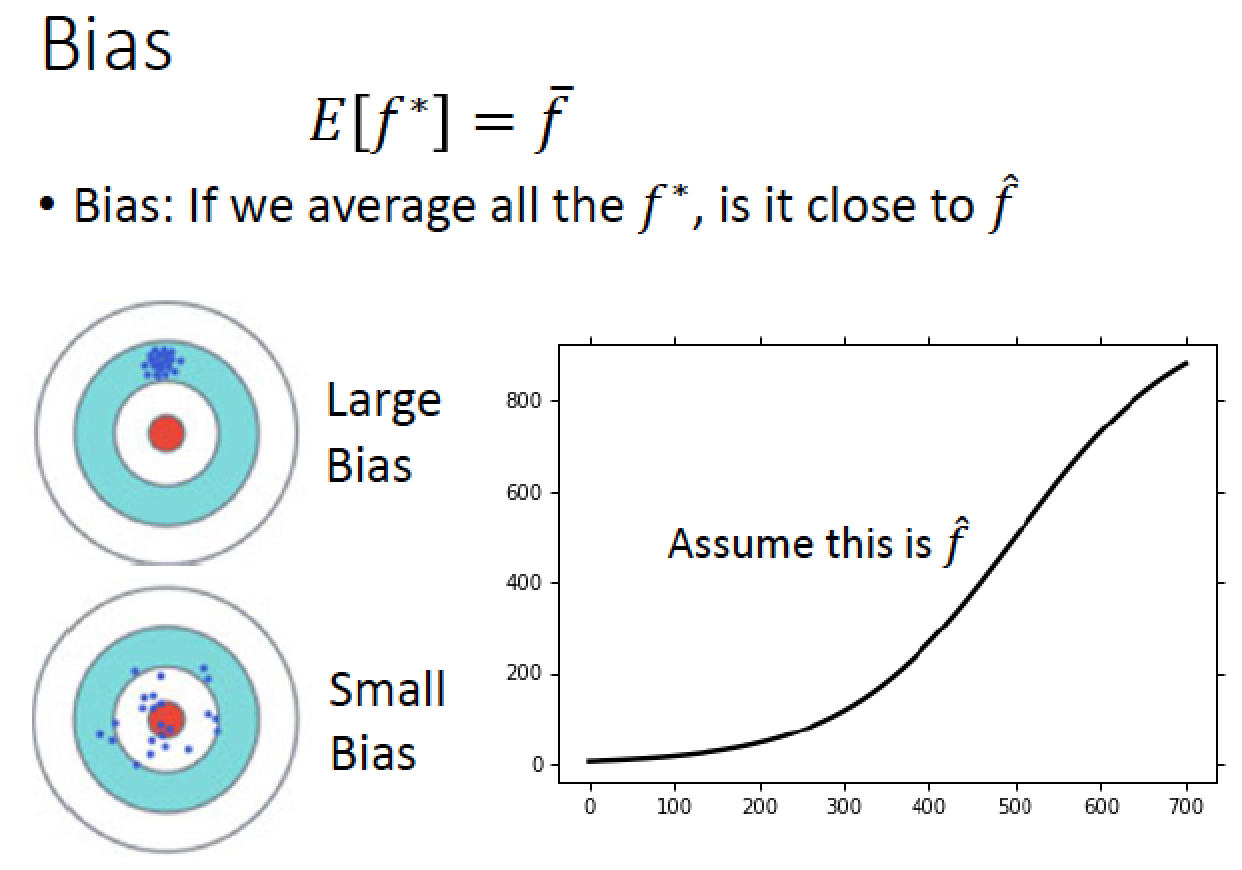 | 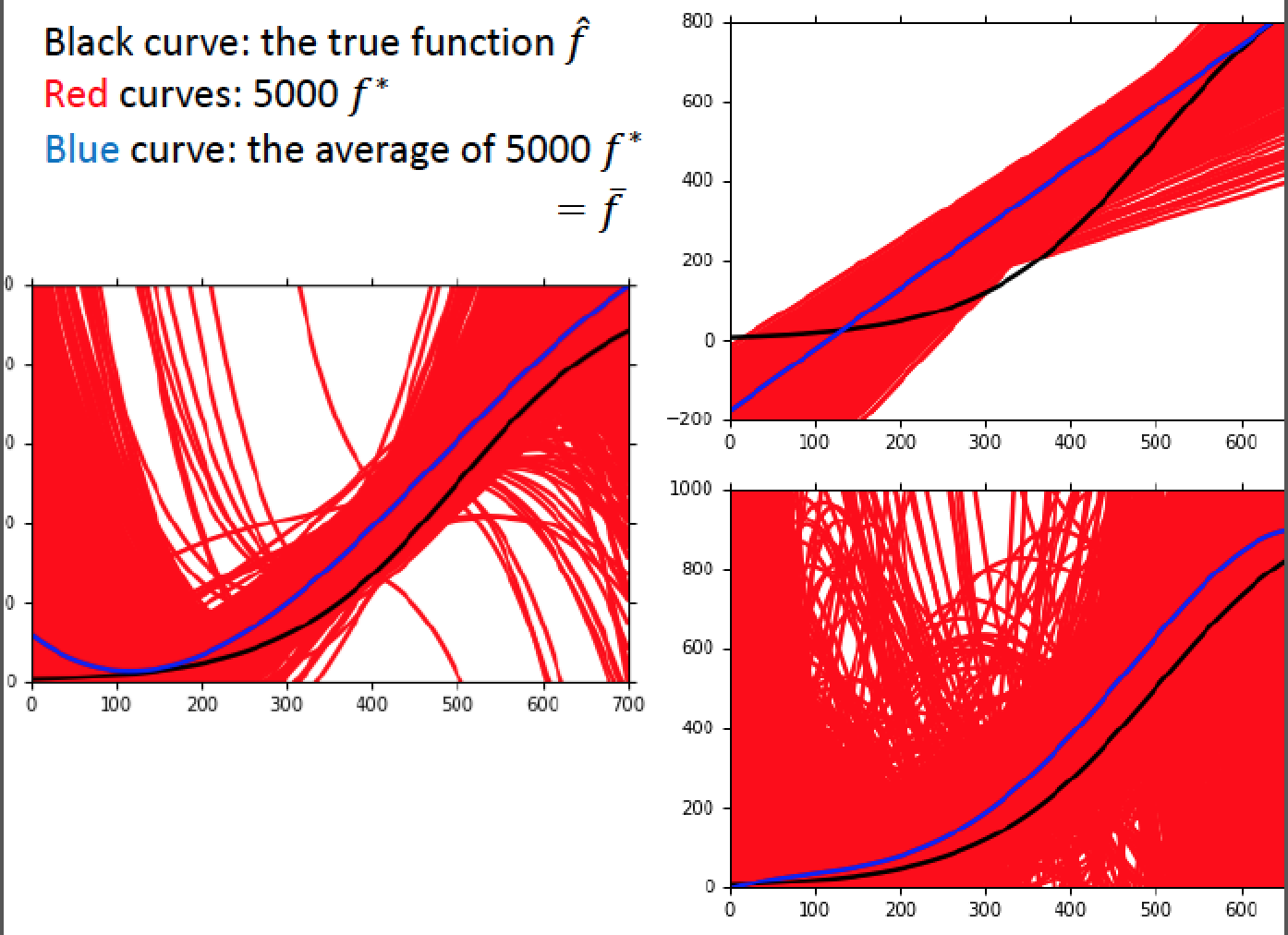
實驗結果:黑色線是答案 true function
紅色線是實驗,5000次實驗
藍色線是實驗結果的平均值
|
根據實驗結果,我們發現複雜的 model ( 五次 ) 實驗結果的平均,得到藍色的線,居然跟真正的結果很接近! 這樣的結論可用下圖來說明:
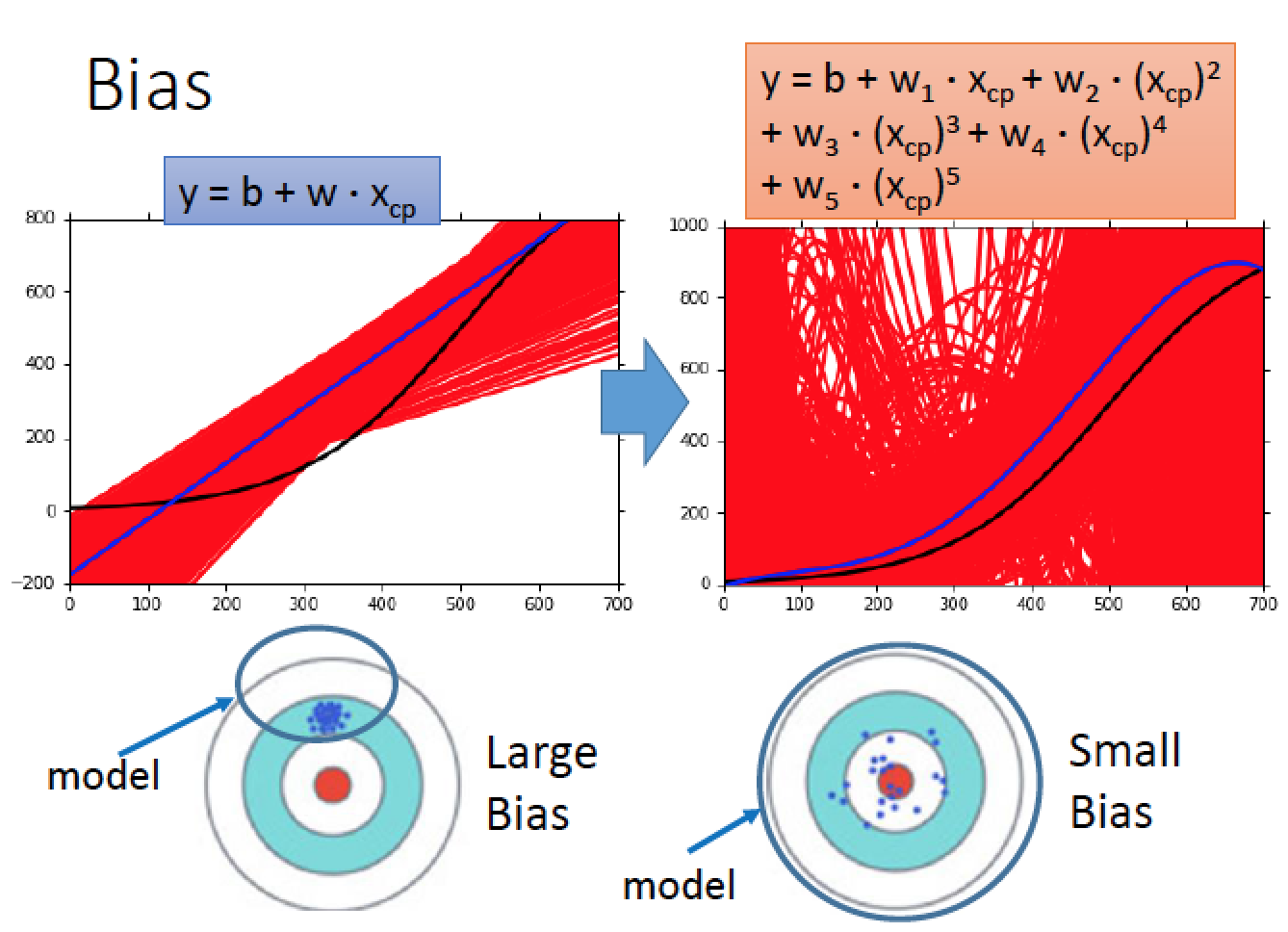 用五次的 function space 比較大
用五次的 function space 比較大
Model 對 Testing Data 所畫出來的線
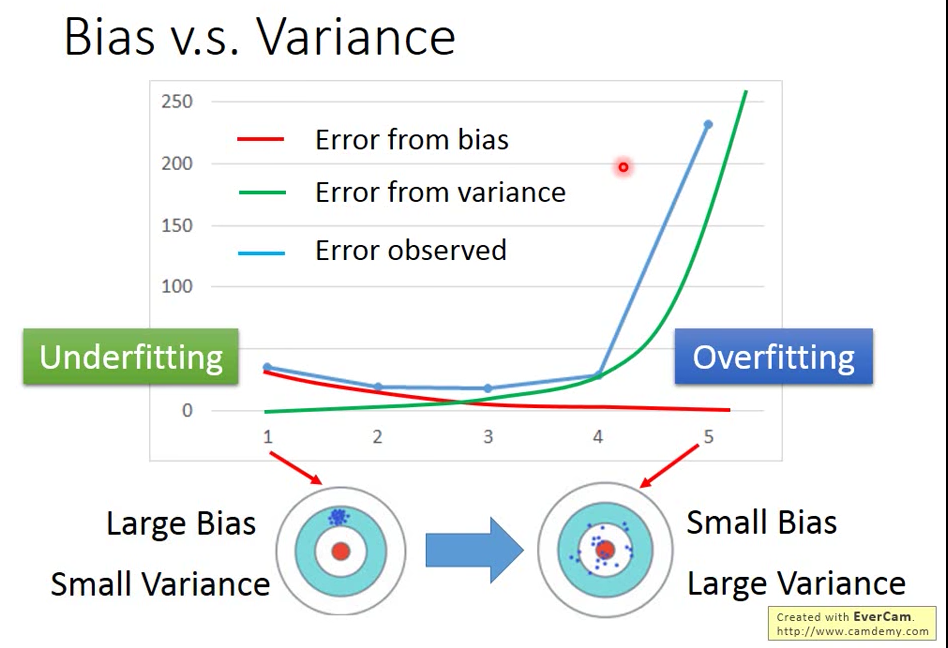
比較簡單的 model: bias 比較大,variance 比較小
比較複雜的 model: bias 比較小,variance 比較大
error 來自於 bias 很大,稱為 Underfitting
error 來自於 variance 大,稱為 Overfitting
→ error 來自於 bias 大的話,要 re-design model ! 例如把更多的 feature 加進去,或是換個複雜點的 Model 可能一次不夠,增加為二次三次
→ error 來自於 variance 大的話,增加 data 量!或是做 Regularization 強迫曲線更平滑,但有可能會傷害 bias

redesign model
重新設計 model 直到讓他可以包含到我們要的目標。
| 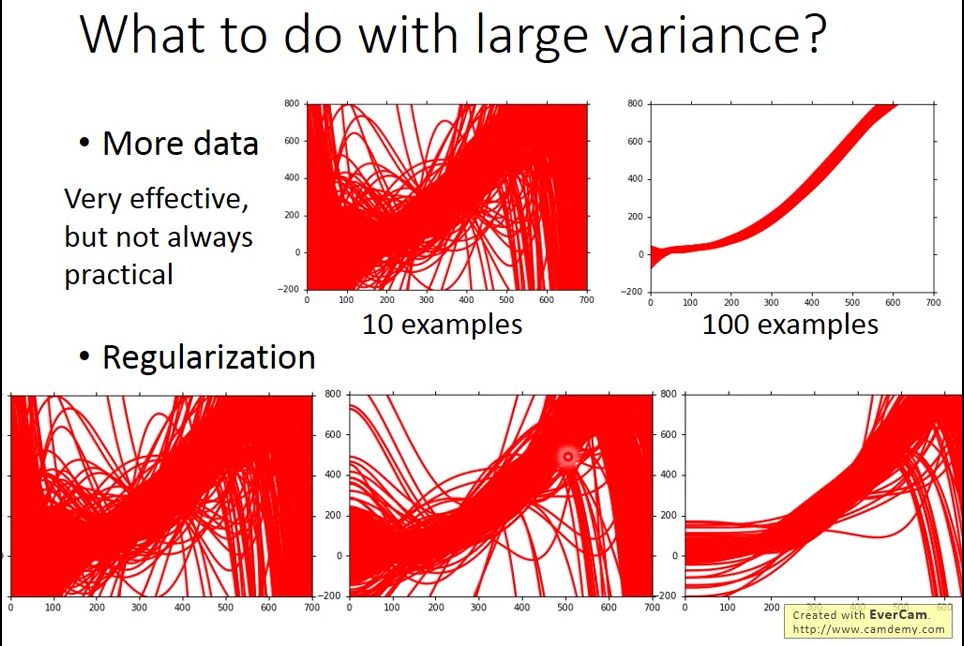
增加 data 是一個有效控制 variance 的方法
Regularization: 在 loss function 上再加一個 term,加上 regularization 後所有曲線都會變平滑,所以會集中在平滑的區域
|
增加 data 的小技巧,根據你對於 data 的了解,製造 data
例如手寫辨識:把所有的文字左轉 15 度,右轉 15 度
或是 你只有火車從左邊開出來的圖片,那就把照片反轉一下,就有右邊的 data
選擇 Model 時

不該這麼做:
把 Model 1,2,3 train 好之後,挑選 testing set 裡面 error 最小的那個
但是這個 testing set 是你手上的 testing
所以不是真正的 testing set
挑選 model 的時候,只看自己手上的 testing set 是有自己的 bias
所以不見得能夠挑到最好的
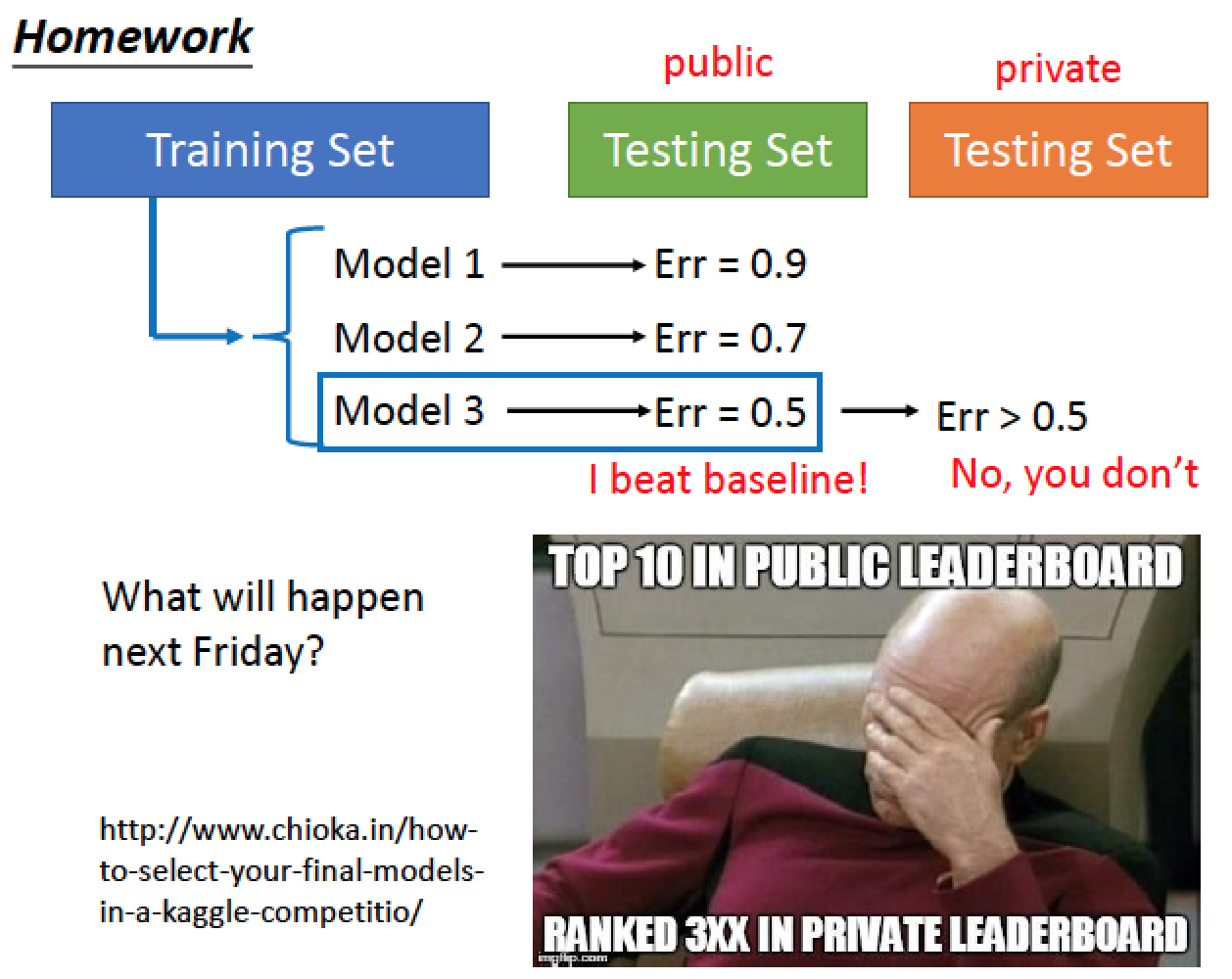
在寫作業的時候,我們上傳測資都是 Public set ,因為看不到 Private Set
所以就算目前準確度高,但是不保證 private set 的資料準確度會高
因此,Public set 的結果是不可靠的,那要怎麼做才會可靠呢?
把 Training Set 分兩組
一組拿來 train model (training set)
另一組拿來 “選” model (validation set)
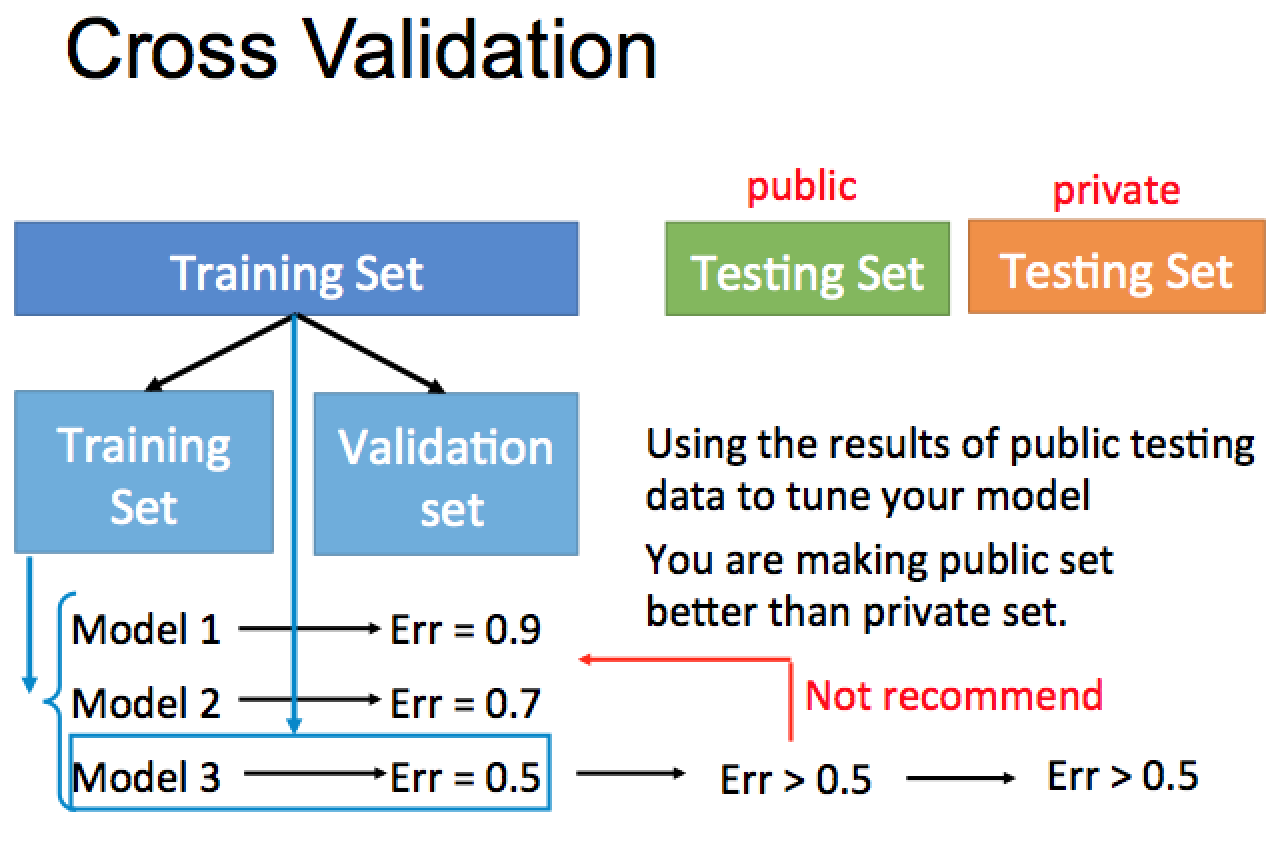
不建議這麼做:
看到 public testing set 結果差,就回頭去再多搞一些東西
不這麼做的原因是因為:
這樣做直接受到 testing set 的 bias 影響,到了真正的 Private testing set 還是不 work
有人會擔心說,Validation Set 分出來的可能也有 bias 分壞掉了
那就使用以下方法來分你的 data
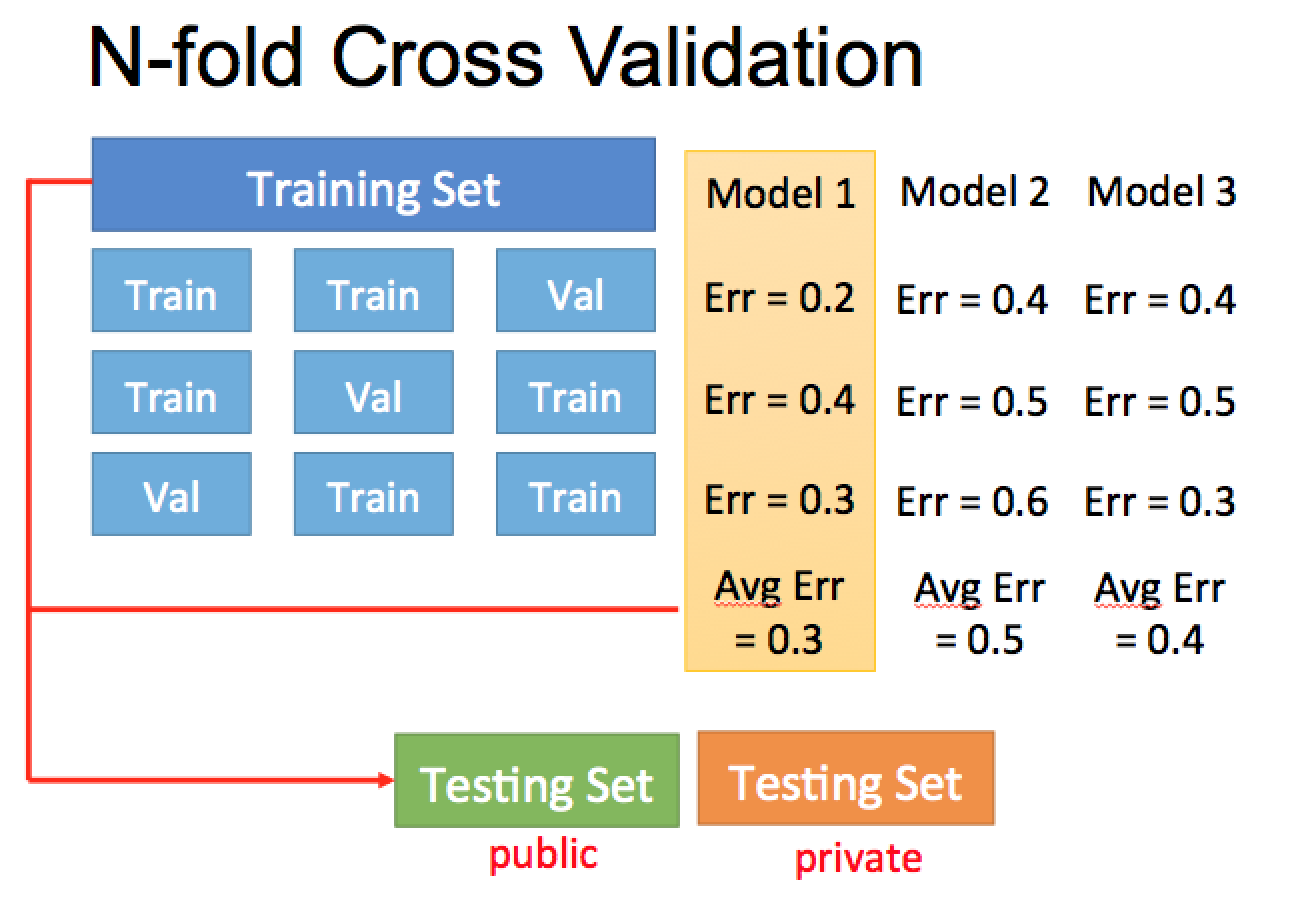
把 training set 分成多份,分別互相當對方的 validation set 跟 training set
這樣多重驗證下,得到的 model 會更為客觀!






留言
張貼留言