[ML筆記] Batch Normalization
Batch Normalization
本篇為台大電機系李宏毅老師 Machine Learning and having it Deep and Structured (2017)
課程筆記
上課影片:
上課影片:
先從 Feature scaling 或是稱作 Feature Normalization 說起

假設 x1 跟 x2 的數值差距很大
x1 值的範圍 1,2,3,4, ...
x2 值的範圍 100, 200, 300, …
x1 的 weight 是 w1,x2 的 weight 是 w2
w1 前面乘的值比較小,所以他對於結果的影響比較小
我們把 w1, w2 對於 Loss 的值的影響做圖 (左下圖藍色圈),
在 w1 方向上的變化斜率比較小,Gradient 變化比較小
在 w2 方向上的變化斜率比較小,Gradient 變化比較大
這樣會讓 training 變得比較不容易,要分別在不同方向上給不同的 learning rate
所以我們透過 feature scaling 的方法把不同的 feature 做 normalization
讓我們的 error surface 看起來比較接近正圓形,會讓我們的 training 比較好做 (右下圖綠色圈)
讓我們的 error surface 看起來比較接近正圓形,會讓我們的 training 比較好做 (右下圖綠色圈)
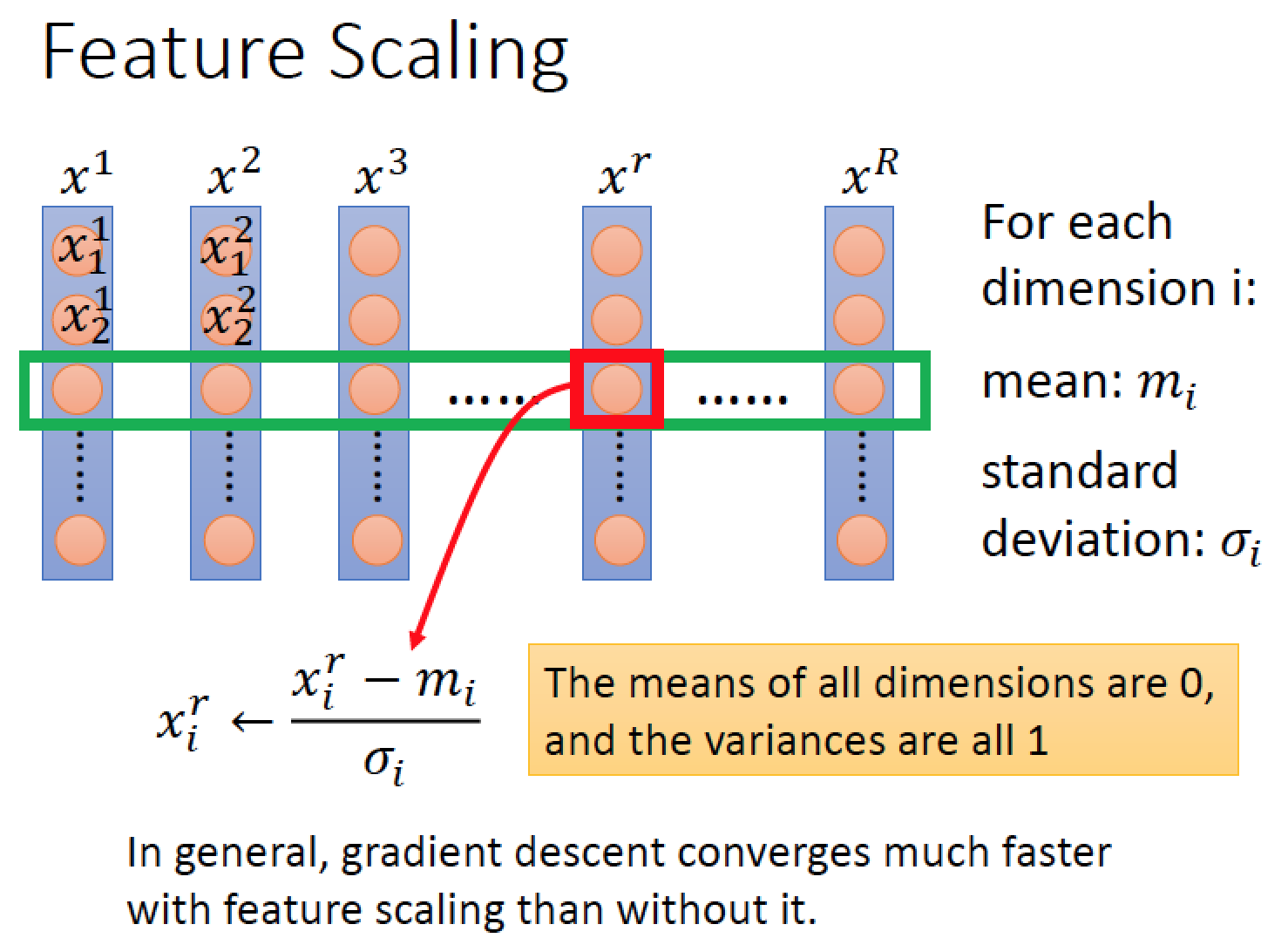
Feature Scaling 做法:
對於第 i 個維度的每一筆 data 都減掉該維度的 mean 再除以該維度的 standard deviation
Deep Learning 當中對 Hidden Layer 之間做 Feature scaling:

input 做完 Feature Scaling 然後進入 Layer1
經過 Layer1 運算後的 output 在要進入 Layer2 之前也做 Feature Scaling
經過 Layer2 運算後的 output 在要進入下一個 Layer3 之前也做 Feature Scaling
這樣對於每一個 Layer 都做 Normalization 對於 Deep Learning 是很有幫助的
因為他解決了一個叫做 Internal Covariate Shift 的問題
可以讓 Internal Covariate Shift 比較輕微一點
Internal Covariate Shift 問題:
假設每一個人都是一個 Layer
想像有三個人透過傳話筒來傳話
對於中間那人來說,左邊的人叫他把話筒降低,右邊的人叫他把話筒升高
他就把左手邊的話筒放低,右手邊話筒升高,他可能移動太多
兩邊都調整太多後,造成結果不好
當一個 Deep Network 非常深的時候,狀況也是一樣的,當我們後面的 Layer 根據前面
的結果做出調整,但是前面的 Layer 也根據更前面的結果更動了,大家都動的情況下,
造成結果還是壞掉了
的結果做出調整,但是前面的 Layer 也根據更前面的結果更動了,大家都動的情況下,
造成結果還是壞掉了
為了解決這個問題,過去傳統的方法就是 Learning Rate 設小一點
Learning Rate 設小一點的缺點就是慢
Normalization 的好處:把每一個 Layer 的 feature 都做 Normalization 後,
對於每一個 Layer 而言,確保 output 的 Statistic 是固定的
對於每一個 Layer 而言,確保 output 的 Statistic 是固定的
但是麻煩的地方在於,我們不太容易讓他的 Statistic 固定,
因為在整個 training 的過程中,Network 的參數是不斷在變化的,
所以每一個 Hidden Layer 的 mean 跟 variance 是不斷在變化的,
所以我們需要一個新的技術,這個技術就叫做 “Batch Normalization”
因為在整個 training 的過程中,Network 的參數是不斷在變化的,
所以每一個 Hidden Layer 的 mean 跟 variance 是不斷在變化的,
所以我們需要一個新的技術,這個技術就叫做 “Batch Normalization”
Batch 的概念複習:
我們在 training 的時候,不會只挑一個 data 出來,而是一次挑一把 data 出來 train
假設我們一次挑出 3 筆 data 出來 train,我們的 Batch = 3

使用 GPU 加速運算時,假設我們的 Batch = 3
x1, x2, x3 這三筆資料會是平行運算的,我們把 x1, x2, x3 排在一起變成一個 input matrix X
對 weight matrix W 運算,得到一個 output matrix Z
Batch Normalization
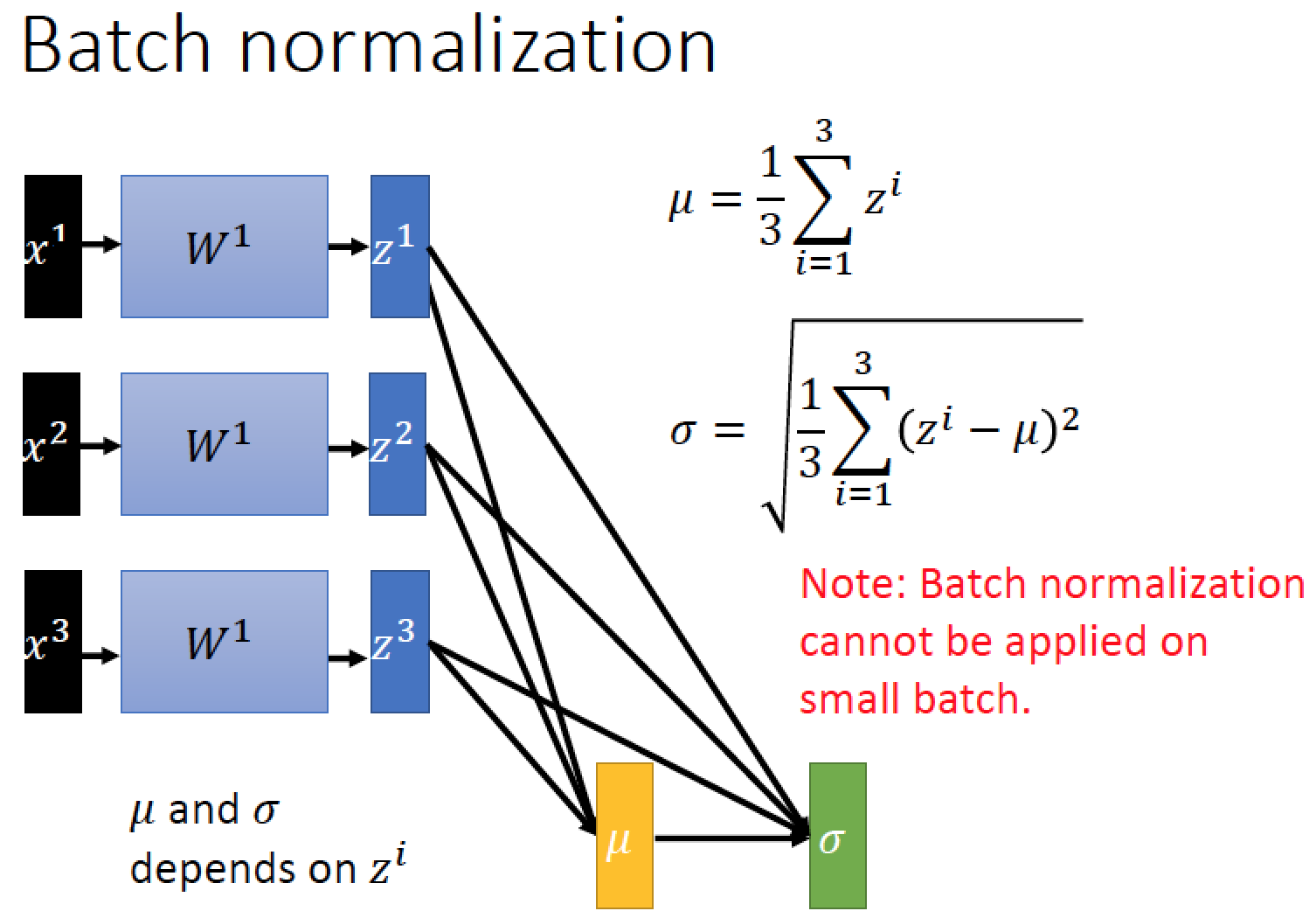
Normaliation 可以放在 activation function 之前,也可以放在 activation function 之後
我們採用把 Normalization 放在 activation 之前,因為有些 activation function
像是 tanh 或是 sigmoid 會有 saturation region,我們不喜歡 input 會落在 saturation region
所以先做 Normalization 在丟進 activation function
可以比較能夠確保我們的值不會掉進 saturation region
像是 tanh 或是 sigmoid 會有 saturation region,我們不喜歡 input 會落在 saturation region
所以先做 Normalization 在丟進 activation function
可以比較能夠確保我們的值不會掉進 saturation region
我們現在要做 Normalization,要先算平均 ‘mu’ 以及 standard deviation ‘sigma’
要注意的事情:做 Batch Normalization 的時候,
目前的平均 ‘mu’ 跟標準差 ‘sigma’ 都是 depend on z1, z2, z3
目前的平均 ‘mu’ 跟標準差 ‘sigma’ 都是 depend on z1, z2, z3
雖然我們希望 mu 跟 sigma 是代表整個 training set 上面的情況,
但是實作上這件事非常耗時間去運算,所以才只針對 Batch 去計算 mu 跟 sigma
但是實作上這件事非常耗時間去運算,所以才只針對 Batch 去計算 mu 跟 sigma
因此 Batch 的 size 不能夠太小,否則我們無法從 batch 裡面估測整個 data 的情況
→ Batch 太小的話 Batch Normalization 的 Performance 會很差
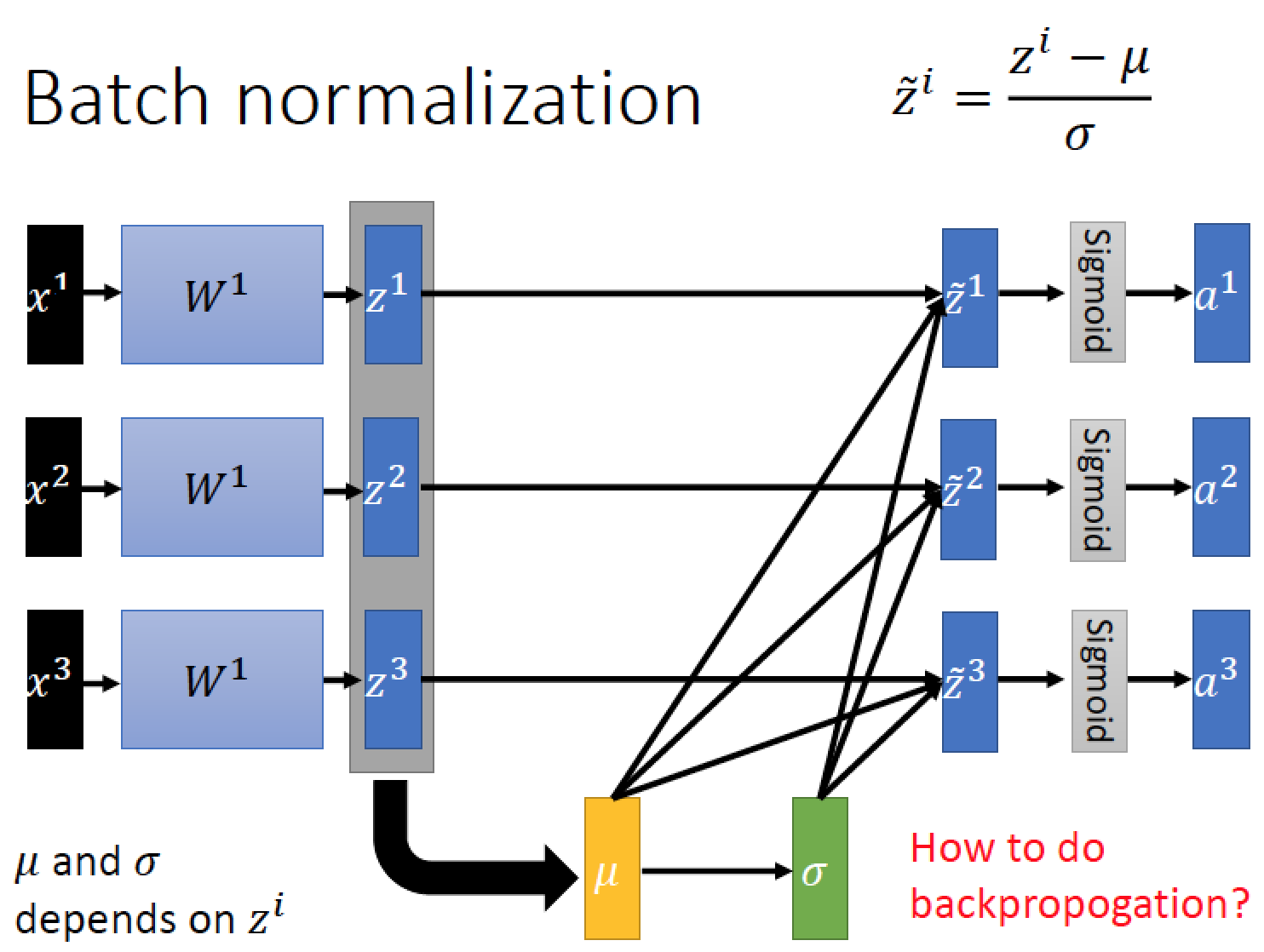
接下來,我們把 z - mu 再除以 sigma
經過 Normalization 之後的 z 他們的 mean 是 0 ,標準差是 1
然後經過 activation function 例如 sigmoid 後,得到運算後的結果 a
有 Batch Normalization 的時候該怎麼 train 呢?
把整個 batch 裡面所有個 data 一起考慮:
要想像成一個巨大的 Network input 是一整個 Batch (比原本的 Network 多出了 sigma 跟 mu)
input x1,x2, x3 得到 z1, z2, z3 然後經過 mu 跟 sigma運算後,得到新的 z 的值
我們把 Z Normalize 後,可以直接丟進 activation function
但是有時候我們不希望丟進 activation function 的資料 mean 都是 0,標準差都是 1

所以我們又加上 garma 跟 beta 來調整他的 mean 跟 standard deviation
調整完之後才丟進 activation function
如果我們今天的 garma 跟好等於 sigma,beta 剛好等於 mu 的話,就跟沒有做事一樣
但是加入 beta 跟 garma 還是有不一樣的地方
因為 mu 跟 sigma 是根據 input data 的 feature 決定的,而 beta 跟 garma
則是根據 Network 想要怎麼加才自動加上去的,所以 beta 跟 garma 是獨立的,
不會受到 input feature 所影響
則是根據 Network 想要怎麼加才自動加上去的,所以 beta 跟 garma 是獨立的,
不會受到 input feature 所影響
接下來看一下 testing 時怎麼做:
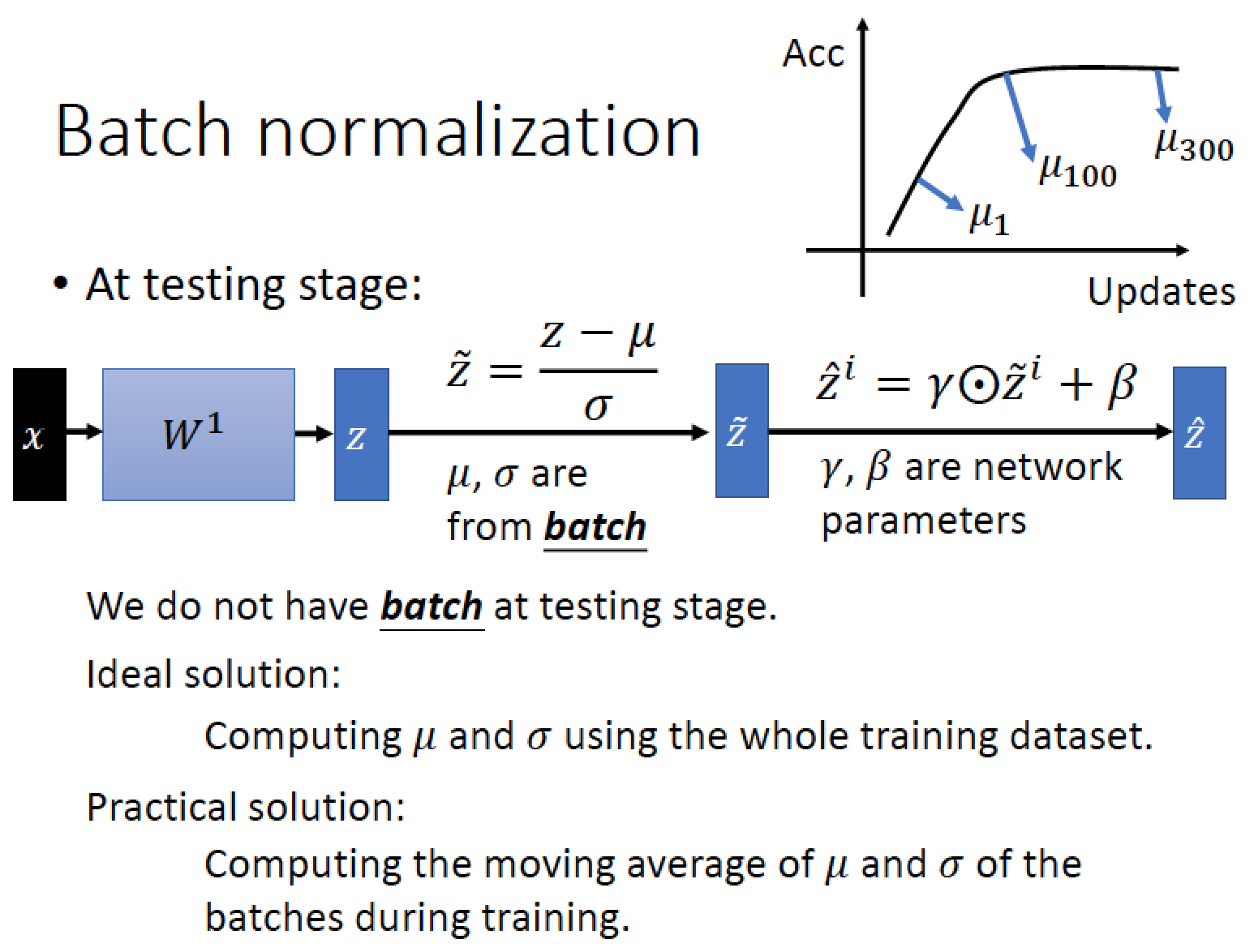
Testing 的時候 data 是一筆一筆進來的,所以我們沒法計算 mu 跟 sigma,
必須在 training 完畢就要確定
必須在 training 完畢就要確定
解決方案1:把整個 training set 看一遍,計算真正的 mu 跟 sigma
這個做法不切實際,如果 training data 超大,完全沒辦法做。
解決方案2:mu 跟 sigma 是在 training 過程中逐步地更新的,
training 完後的後 mu 跟 sigma 也確定下來
training 完後的後 mu 跟 sigma 也確定下來
Batch Normalization 的好處

可以 training 加速,可以防止 gradient vanishing 的問題,
可以幫助 sigmoid 或是 tanh 這種的 activation function
可以幫助 sigmoid 或是 tanh 這種的 activation function
可以讓參數的 initialization 的影響較小
有一些對抗 Overfitting 的效果,但是主要的作用還是用在 training 不好的時候使用,
提升 training 的準確率
提升 training 的準確率
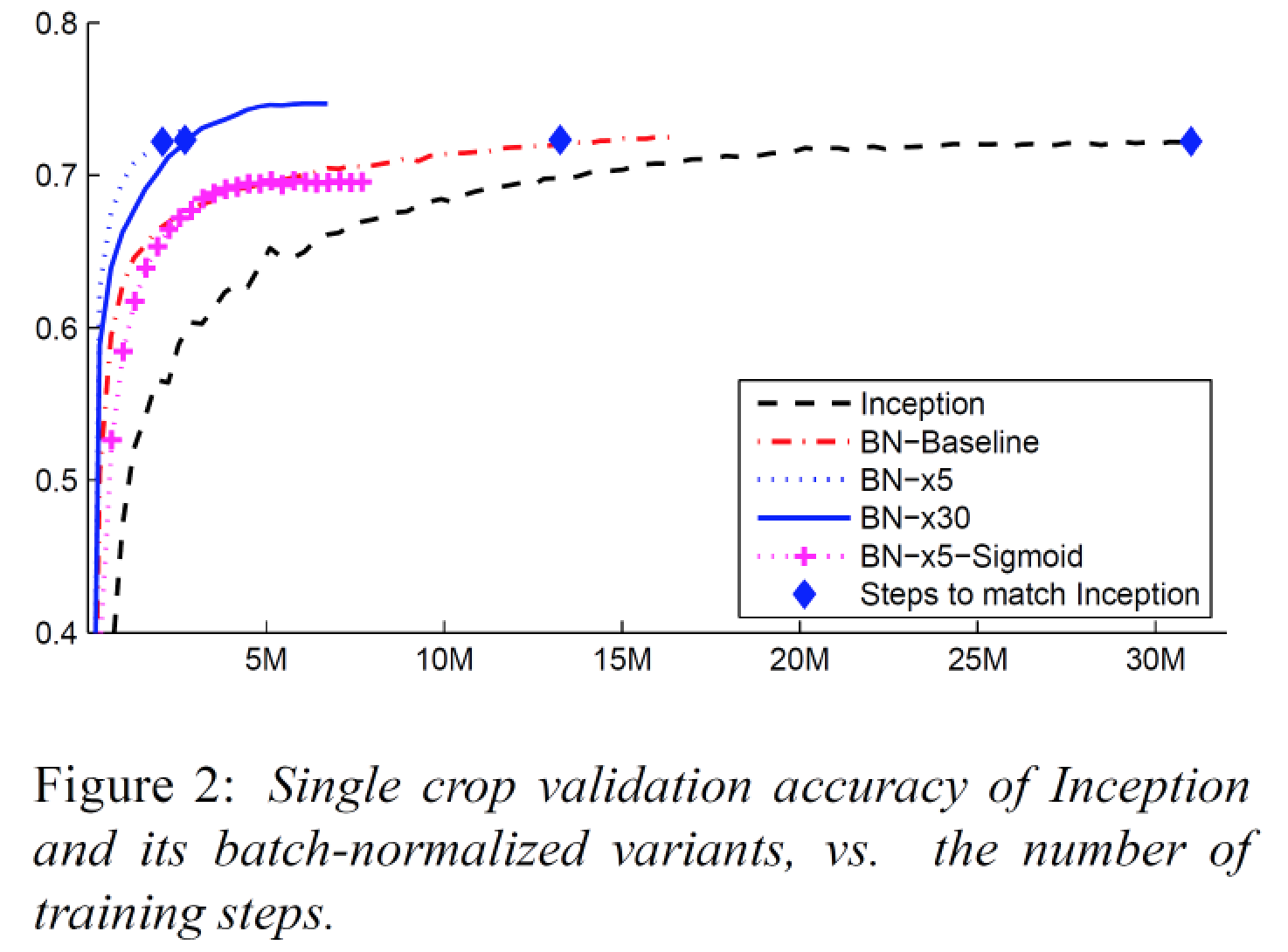
不做 Batch Normalization 的話 Sigmoid function 是 train 不起來的





感謝你....
回覆刪除淺顯易懂
回覆刪除感恩你 淺顯易懂
回覆刪除感恩 講得很清楚 幫助很大
回覆刪除另外想請問Gamma值和Beta值是hyperparameters嗎?感覺像XD
應該不算是? 原影片 19:25 處有解說
刪除