[ML 筆記] Anomaly Detection (Machine Learning Model)
Anomaly Detection 異常偵測
本篇為台大電機系李宏毅老師 Machine Learning (2019) 課程筆記
上課影片:
想法:
訓練 model 在訓練資料 {x1,x2, … , xN} 上
測試時:
input x 如果『像』訓練資料 → 過 anomaly detector → 說出這是 normal 的資料
input x 如果很『不像』訓練資料 → 過 anomaly detector → 說出這是 anomaly 異常資料
什麼叫做 『像』(similar) 呢?
這就是 anomaly detection 要解的問題!
何謂『異常』的舉例:
訓練資料看很多隻雷丘 → 那皮卡丘就是異常
訓練資料看很多隻皮卡丘 → 那雷丘就是異常
訓練資料看用來寶可夢 → 那非寶可夢的數碼寶貝就是異常

『異常偵測』之應用:刷卡交易紀錄
『異常偵測』之應用:癌細胞偵測
訓練資料集:正常細胞
異常偵測的對象:癌細胞
直觀的解法:如果使用 Binary Classification 來偵測異常,則類別定義為
Class 1: Normal
Class 2: Anomaly
BUT
其實問題並沒有這麼簡單!
困難點 1: 異常資料分布無法掌握
其實不太容易把異常偵測視為普通的 Binary Classification 的問題
因為
世界上的所謂的『異常』可能性太多了,根本無法窮舉
也就是上面的 Class 2 所謂的異常資料的分佈,根本是未知的!
困難點 2: 資料難以蒐集
異常交易偵測的例子中
多數的交易都是正常的交易,且異常的交易也不會告訴你他是異常的,必須人工挑出!
並沒有一個 label 能做為所謂的 “unkown”

(上圖的 Open-set Recognition - 能把沒有看過的東西回報 “unkown”)
且 Training data 當中
1 訓練資料是乾淨的正常的 (銀行的所有交易紀錄確保全部都是正常的)
2. 訓練資料中其實也不是全部都是正常的 (銀行的所有交易紀錄其實會混雜異常交易)
以辛普森家族圖片辨識 Model 為例:

每一位訓練資料都有標注分別是誰

如果我們已經 train 好一個辛普森家庭成員的分類器
則我們在使用的時候,除了 output 辨識結果,還要在 output 一個信心分數 c
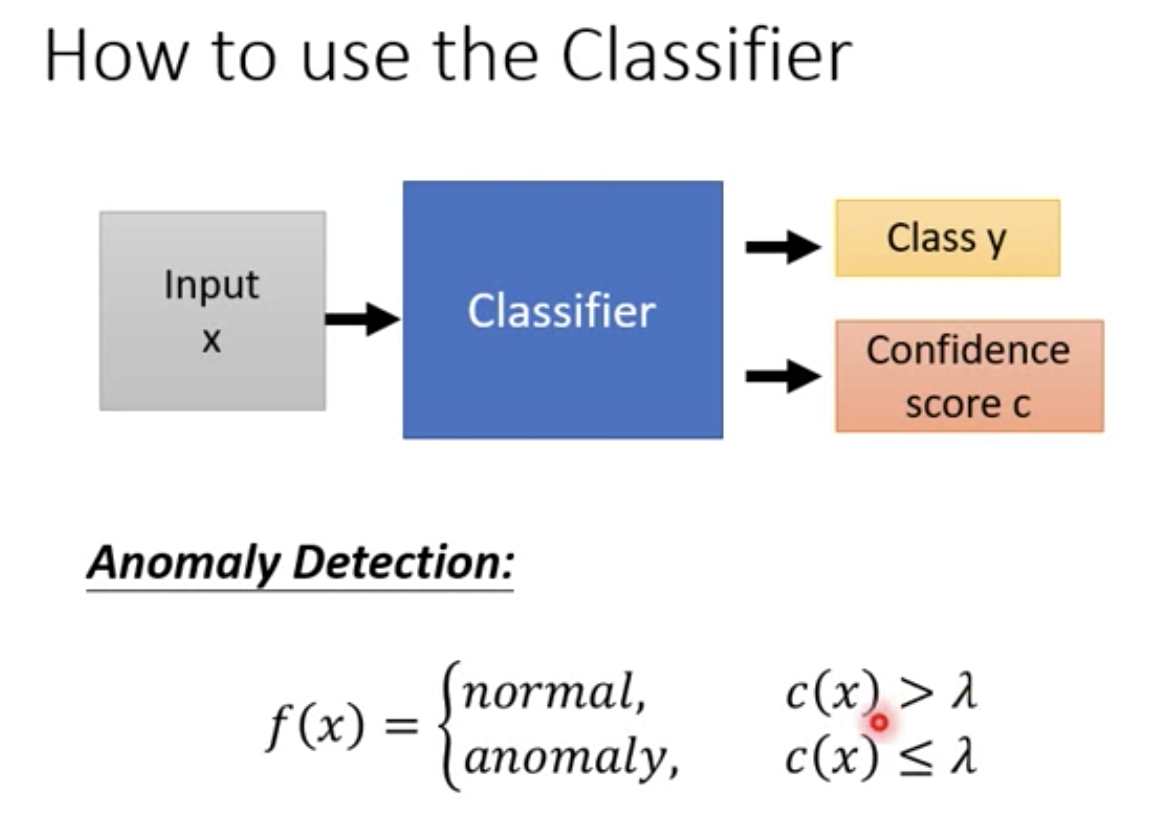
假設信心分數 output 小於某一個 threshold lambda 的話
我們就說這張圖片不是辛普森家庭!
How to Estimate Confidence
測試一張圖片,透過分類器的 output 得到一個 distribution 定性分析

信心分數的取法:可以取最高的數值當作信心分數
假設測試 model 時,我們拿以下資料來看 output 結果

以上結果看起來很正常,但是也是會有反例

看 Kaggle 提供的大量的純辛普森家族的測試資料,信心分數的分佈
結果非常的集中
辨識正確的以藍色辨識錯誤的以紅色表示

如果我們丟 15000 張其他動畫的人物,分布會長怎樣呢?

大部分的 data 信心分數都偏低,但還是約有 1/10 的資料信心分數仍然偏高,但顯然是分類錯誤的狀況!
Network for Confidence Estimation 信心分數的評估

想法:訓練 classifier 的同時,還要訓練另一個 output 信心分數的 model 同時進行!
Framework of 異常偵測系統
延續辛普森家族的例子~~
我們使用 Confience 來打造異常偵測系統

Training Set 全部都是辛普森家族的人物圖片(分別標明每個人物的名字)
Development Set 需要模仿 testing set ,所以要包含“非”辛普森家族的圖片在內
利用 Development set 來調參數,避免 overfit 在 testing set 上
異常偵測系統的效能評估
假設我們使用了 100 張辛普森家族圖片(用藍色表示),5 張不是辛普森家族圖片(紅色)來測試 model

目前測試結果,異常圖片有一張小櫻的 confd. 為 0.998 超高 (很糟糕)
,一張辛普森家族的圖片拿到很低的 confd.
在異常偵測的評估裡面,正確率並不是一個好的評估準則!
因為在這個例子當中,正常資料與異常資料的比例是非常懸殊的!
在這種問題中,『錯誤』的類型有兩種
- 異常的資料被判斷成正常的資料 (missing)
- 正常的資料被判斷成異常的資料 (False alarm)

如果切在另一個 threshold,得到下圖右邊的表

其實一個系統是好還是壞,取決於我們覺得 false alarm 比較嚴重,還是 missing 比較嚴重
舉例來說,我們把 missing 的誤判設定為扣 1 分,把 false alarm 的誤判設定扣 100 分
Cost Table A 如下
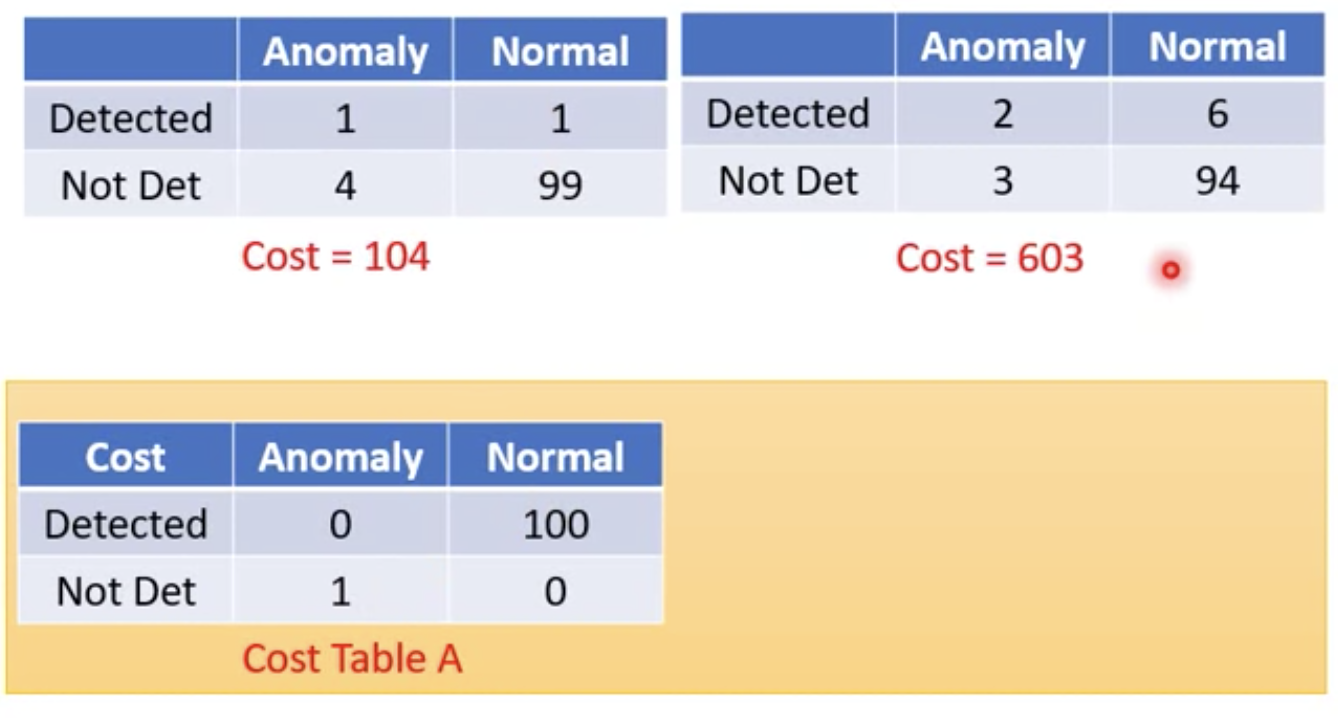
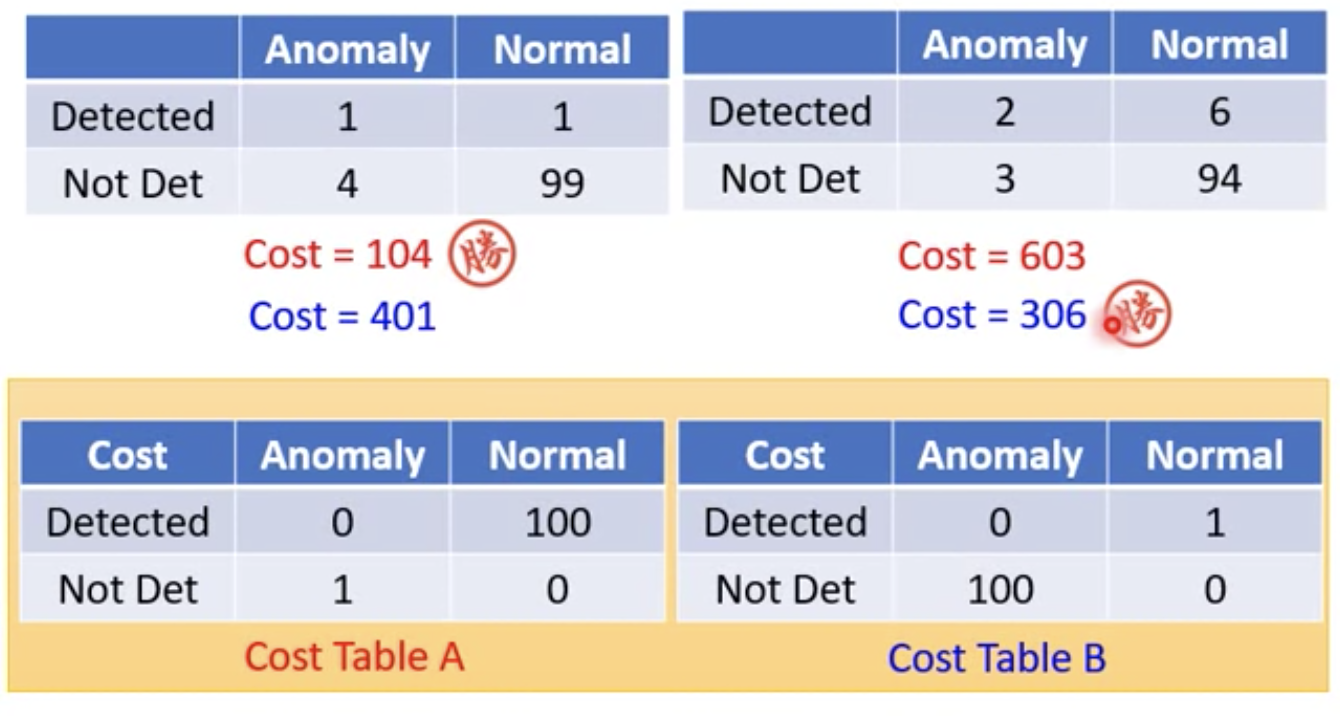
使用 Cost Table A 來評估異常偵測 confd. Threshold lambda 值的準率度的話
我們會選擇左邊的 threshold ,因為他計算出來的 Cost 值較右邊的低
但是如果我們用另一個 Cost Table B 來衡量的話,結論就會不同
要用哪種衡量方式取決與我們系統的目的而定!
Possible Issues of Anomaly Detection
假設我們做了一個貓狗分類器
顯然,一個東西既沒有貓的特徵,也沒有狗的特徵,機器會把它放在中間,得到很低的 confd.
但是也有可能我們測試的圖片,有貓的特徵,但不是貓,則會得到很高的 confd.

有一些方法來解這個問題:

想法:
假設我們可以蒐集到異常的資料,我們可以教機器說,看到正常的資料,要給他高的 confd.,看到異常的資料,我們給他低的 confd.
但是我們不容易蒐集到很多『跟正常資料很像』的『異常資料』,所以又有人提出使用 GAN 來生 data
資料沒有明確 Label 的分類問題 (Without Label)
例子:在線上多人聯合玩寶可夢的系統當中~
假設多數的寶可夢玩家都是正常的玩家,少數的玩家是阻撓大家破關的異常玩家

每一個 x 是一個玩家,一個玩家表示為一個向量
向量的第一個 feature 假設是過去一段時間內,該玩家說垃圾話的頻率
向量的第二個 feature 假設為該玩家在無政府狀態,發言的比例
註記:
無政府狀態:系統隨機挑一個玩家的指令來玩遊戲
民主狀態:系統在一段時間內,挑最多人投票的指令來進行遊戲

目前我們的問題是,我們有大量的 x 但是我們沒有 y
我們可以建立一個模型~

機率模型,可以告訴我們說,某一種使用者發生的機率有多大
假設某種玩家發生的機率,大於某個 threshold 我們就把該玩家視為正常的玩家
反之,我們可以視為異常的玩家!
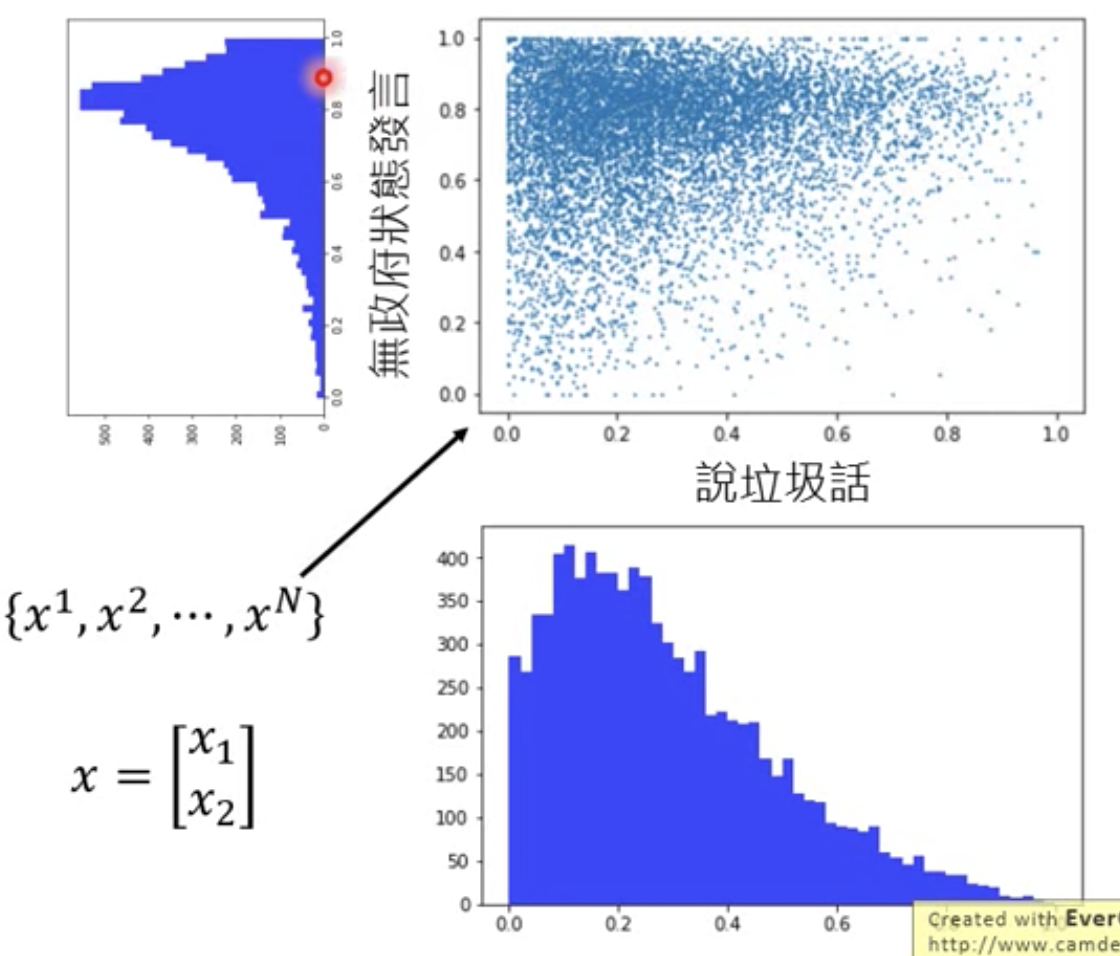
把每個玩家用二維向量 [ 說垃圾話機率, 無政府狀態發言機率 ] 來描述
統計結果:
說垃圾話的玩家的分佈,並不是完全說垃圾話的玩家最多
無政府狀態發言的比例,發現實際上,多數人都有八成左右的時間在無政府狀態下發言,因為這個遊戲大多時間是在無政府狀態下進行的

根據以上方法來計算各類型玩家的機率,我們可以得到哪一種 behavior 玩家出現的機率最大,接下來我們需要數值的方法來區分正常玩家與異常玩家
我們蒐集到 N 筆資料畫出了二維的分佈圖
我們目前所看到的數據,其實背後是有一個 probability density function 來產生的
目標就是要找出這個 probability density function 究竟長什麼樣?
而 theta 的數值決定了 probability density function 長什麼樣
theta 必須從訓練資料中來找!
那我們可以定義『可能性』Likelihood L
L 計算方式如下:
x1, x2, ... 根據 probability density function 產生的機率相乘 算出 Likelihood
選一個 theta ,讓 Likelihood 最大的那個 theta 就是我們要找的 theta 值

假設我們的 probability density function 是 Gaussian Distrubution ← 很常用
以 mean (miu) 跟 covariance matrix (sigma) 來控制
所以可以把 Likelihood theta 置換成 Likelihood mu sigma
如果有了一群 user mean 值,可以透過計算 Likelihood 的大小,來區別誰是正常的玩家
(正常的玩家,計算出來的 Likelihood 比較大,異常的玩家平均後,計算出來的 Likelihood 比較小)

上述的 mu 跟 sigma 是有公式可以解的
所有個 training 平均為 mu*
有了 mu* 既可以找出 sigma*


當然 probability density function 不一定是 Gaussian 但是 Gaussian 比較常用
(probability density function 也可以用 Neural Network 來產生)
找出了mu*, sigma* 就可以有 probability density function 來偵測哪個 input data x 是異常玩家

當然,可以用更多個 feature 來計算 mu* sigma* 的 probability density function

其他的方法:可以用 Auto-encoder 來做這件事
回到辛普森的例子:
Auto-encoder 做的事情是把所有訓練資料 Encode
輸入一張圖片先 encode 成一個向量 code 再依據 code 過 decode 回原來的圖片
Auto-encoder 的訓練過程,讓 Decoder 後的圖片,跟 input 端的圖片越像越好!

這樣的訓練機制下,如果是正常的測試資料輸入,圖片可以還原回來,還原度較高。
如果異常資料輸入時, Decoder 還原出來得圖片就會根原圖差異蠻大的,因此可以偵測異常用






Hi there! Thank you for sharing your thoughts about electrician in your area. I am glad to stop by your site and know more about electrician. Keep it up! This is a good read. I will be looking forward to visit your page again and for your other posts as well.
回覆刪除visual inspection machine